In der heutigen digitalen Welt haben große Sprachmodelle (Large Language Models, LLMs) wie GPT, BERT oder ähnliche KI-Systeme erheblich an Bedeutung gewonnen. Sie revolutionieren zahlreiche Branchen von Kundenservice über Content-Erstellung bis hin zu Übersetzungen. Doch mit der wachsenden Verbreitung gehen auch diverse Herausforderungen einher. Viele Nutzer machen fundamentale Fehler beim Umgang mit diesen Technologien, die teils die Qualität der generierten Inhalte schmälern oder die Effizienz der Nutzung einschränken. Dabei sind es vor allem Missverständnisse im Prompt-Design und die falsche Erwartungshaltung gegenüber den Modellen, die zu suboptimalen Ergebnissen führen.
Eine der typischen Stolpersteine besteht darin, dass viele Anwender die enorme Komplexität und die Limitationen der Sprachmodelle nicht vollständig verstehen. Große Sprachmodelle basieren auf riesigen Textdatensätzen, sind jedoch kein Ersatz für menschliches Verständnis oder Expertenwissen. Sie sind Mustererkennungsmaschinen, die auf Wahrscheinlichkeiten beruhen und somit Fehler oder unlogische Antworten generieren können. Wer beim Verfassen von Prompts zu ungenau oder oberflächlich bleibt, erhält häufig missverständliche oder vage Ergebnisse. Präzision im Prompt-Design ist daher entscheidend, um klare und zielgerichtete Antworten auszulesen.
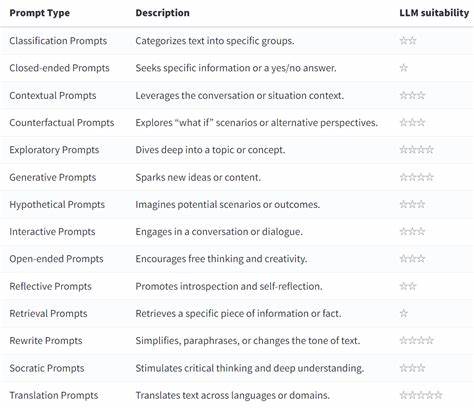
Zudem sollten Nutzer bedenken, dass LLMs keine tatsächlichen Faktenprüfer sind, deshalb sind sorgfältige Validierungen der generierten Informationen stets unverzichtbar.Ein weiterer häufig vorkommender Fehler betrifft die Eingabeaufforderung selbst, sprich die Prompts. Viele Nutzer denken, einfache Befehle oder Fragen seien ausreichend, um perfekte Antworten zu erhalten. Die Realität ist wesentlich komplexer: Das Modell versteht Kontext nur innerhalb der Eingaben und zeigt bessere Leistungen bei ausführlichen, gut strukturierten und spezifischen Anfragen. Kürze bedeutet nicht immer Klarheit – oft ist es notwendig, relevante Hintergrundinformationen einzubauen und die Aufgabenstellung sorgfältig zu definieren.
Variationen im Prompt oder das Einfügen von Beispielen können helfen, die erwünschte Antwortqualität deutlich zu verbessern. Ebenso wichtig ist das Vermeiden von zu komplexen oder mehrdeutigen Formulierungen, die das Modell verwirren oder zu interpretativen Freiräumen einladen können. Eine präzise, verständliche Sprache bildet somit die Basis für erfolgreiche Interaktionen mit LLMs.Ferner unterschätzen viele Nutzer die Möglichkeiten, die sich aus einer iterativen Vorgehensweise beim Prompt-Schreiben ergeben. Statt nur einen einzigen Versuch zu starten, sollten Anwender experimentierfreudig verschiedene Varianten testen und die Resultate vergleichen.
Durch gezielte Anpassungen und Feinstellungen kann die Antwortqualität optimiert werden. Das Ignorieren der Feedbackschleife mit dem Modell führt hingegen dazu, dass Fehler etabliert und Chancen für differenziertere Antworten vertan werden. Regelmäßiges Nachjustieren ist ein wertvoller Schritt, um die Fähigkeiten der KI bestmöglich auszuschöpfen und auf individuelle Bedürfnisse zuzuschneiden.Ein oft vernachlässigter Aspekt ist die ethische Dimension beim Einsatz solcher Technologien. Häufig werden vorgefertigte oder nicht hinterfragte Prompts genutzt, die eventuell falsche, sensible oder diskriminierende Inhalte generieren können.
Die Verantwortung für die Kontrolle der Antworten liegt dabei beim Nutzer. Eine fehlende Sensibilität für kulturelle und gesellschaftliche Kontexte kann zu problematischen Ergebnissen führen, die das Vertrauen in KI-Anwendungen untergraben. Bewusstes, verantwortungsvolles Handeln und der Einsatz von Filtermechanismen sind dringend notwendig, um Risiken zu minimieren und eine verlässliche Nutzung zu gewährleisten.Technische Limitierungen der Modelle werden oft übersehen. Trotz ihrer beeindruckenden Fähigkeiten sind LLMs nur bis zu einem gewissen Grad in der Lage, komplexe logische Zusammenhänge zu erfassen oder mehrstufige Schlussfolgerungen zu ziehen.
Dies führt bei unangemessenen oder zu komplexen Prompts zu fehlerhaften Ausgaben oder sogar kompletter Ablehnung der Antwort. Besonders Aufgaben, die tiefgehende Fachkenntnis oder kreatives Denken erfordern, überschreiten häufig die derzeitigen Möglichkeiten der Modelle und verlangen nach menschlicher Überprüfung. Nutzer sollten daher stets eine kritische Haltung bewahren und generierte Inhalte als Vorschläge betrachten, nicht als endgültige Wahrheiten.Darüber hinaus ist die mangelnde Berücksichtigung der Eingaben noch ein häufiger Fehler: Zahlreiche Anwender gehen davon aus, dass mehr Input automatisch bessere Ergebnisse garantiert. Doch ohne gezielte Strukturierung und Priorisierung der Inhalte im Prompt kann die Antwortqualität leiden.
Überladene oder zu komplexe Eingaben überfordern das Modell eher, als dass sie es unterstützen. Es gilt, den richtigen Mittelweg zwischen ausreichender Information und Klarheit zu finden. Hierbei hilft es, einzelne Teilschritte in separaten Anfragen zu formulieren und komplexe Aufgaben zu modularisieren. So können LLMs effizienter genutzt werden und produzieren fundiertere Ergebnisse.Nicht zuletzt sind die Erwartungen vieler Nutzer nicht selten unrealistisch hoch.
Einige gehen davon aus, dass ein LLM in jeder Situation perfekte, kreative oder tiefgründige Texte liefern kann. Diese Vorstellungen fördern Enttäuschungen und führen zu Fehlbedienungen. Während die Technologie beeindruckende Möglichkeiten bietet, ist sie kein Allheilmittel und sollte als Werkzeug in einem größeren Prozess eingesetzt werden. Künstliche Intelligenz ergänzt menschliches Können, ersetzt es aber nicht. Die Akzeptanz von Schwächen und die Bereitschaft, mit Nachkontrollen zu arbeiten, sind entscheidend für einen erfolgreichen Einsatz.