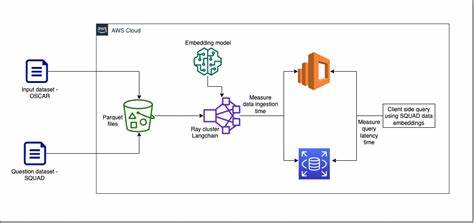
In der heutigen Datenlandschaft ist die Fähigkeit, große Datenmengen aus unterschiedlichsten Quellen zu sammeln und zu verarbeiten, essenziell für den Unternehmenserfolg. Die zunehmend komplexere Datenumgebung, in der Informationen nicht nur aus Datenbanken, sondern auch aus Cloud-Diensten, APIs und internen Tools stammen, stellt Entwickler vor erhebliche Herausforderungen. Eine Multi-Source-Ingestion-Pipeline ist das Herzstück moderner Daten- und Wissensmanagementsysteme. Indem sie Daten effizient aus mehreren Plattformen wie Google Drive, Jira, Confluence oder SharePoint extrahiert, bereitet sie den Boden für fortgeschrittene Analysen, automatisierte Entscheidungsfindungen und intelligente Wissensgraphen. Doch wie baut man eine solche Pipeline, die flexibel bleibt und mit wachsendem Datenvolumen sowie sich ständig ändernden Quellen ohne Qualitätsverlust skaliert? Hier kommt Ray ins Spiel, ein Framework für verteiltes Computing, das speziell für die nahtlose Parallelisierung in Python entwickelt wurde und eine optimale Ressourcenausnutzung bei gleichzeitig hoher Performance ermöglicht.
Eine entscheidende Fragestellung bei der Entwicklung einer Multi-Source-Ingestion-Pipeline ist die Balance zwischen Flexibilität und Komplexität. Kommerzielle oder Open-Source-Bibliotheken wie LlamaIndex bieten zwar schnelle Einstiegsmöglichkeiten, stoßen jedoch schnell an ihre Grenzen, wenn es darum geht, neue oder speziell angepasste Datenquellen zu integrieren. Die Lösung ist häufig eine maßgeschneiderte Architektur, die modular aufgebaut ist und dennoch äußerst erweiterbar bleibt. Das Prinzip der Abstraktion spielt dabei eine elementare Rolle. Es erlaubt durch klar definierte Schnittstellen und wiederverwendbare Komponenten, dass neue Datenquellen wie Lego-Steine hinzugefügt werden können, ohne das bestehende System zu destabilisieren.
Inspiriert von bewährten Architekturmustern wie Pipes-and-Filters und dem Builder Pattern, lässt sich eine Ingestion-Pipeline entwerfen, die einzelnen Verarbeitungsschritten – sogenannten Steps – eine klare und einheitliche Struktur gibt. Jeder Step verarbeitet Eingabedaten, transformiert sie und gibt das Ergebnis an den nächsten Schritt weiter. Das schafft nicht nur Ordnung, sondern sorgt auch für einfache Wartbarkeit und Erweiterbarkeit. Diese Vorgehensweise erleichtert es Entwicklerteams, neue Funktionalitäten und Datenquellen zu integrieren, ohne den Kern der Pipeline neu schreiben zu müssen. Essenziell sind dabei basisklassen, die als Miniaturbausteine fungieren.
Eine abstrakte Pipeline Step Klasse gewährleistet, dass jeder einzelne Verarbeitungsschritt dieselbe Schnittstelle nutzt und somit untereinander austauschbar ist. Das Pipeline-Objekt verwaltet die Abfolge der Schritte und kann bequem erweitert oder umorganisiert werden. Der Builder hingegen ist eine Schicht, die komplexe Pipelines Schritt für Schritt konfiguriert und instanziiert, wodurch unterschiedliche Anforderungen einzelner Datenquellen elegant adressiert werden können. Eine Schlüsselrolle nehmen die sogenannten Connectoren ein, die als Interface zwischen der Pipeline und der jeweiligen Datenquelle fungieren. Sie bestehen häufig aus einer Gateway-Komponente, die die Verbindung mit externen APIs herstellt, und einem Reader, der die Daten entsprechend den Bedürfnissen der Pipeline aufbereitet.
Ein Beispiel dafür ist der Jira-Connector, der über eine OAuth-gesicherte Schnittstelle Daten aus Jira-Projekten sicher abruft und für die Weiterverarbeitung formatiert. Sicherheit spielt hierbei eine zentrale Rolle, denn moderne Authentifizierungsmechanismen wie OAuth 2.0 sorgen dafür, dass sensible Zugangsdaten nicht im Code hinterlegt werden und der Zugriff granular kontrolliert werden kann. Im Leser-Klassenmodul werden anschließend komplexe Datenstrukturen wie Epics, Tasks oder Benutzerinformationen so aufbereitet, dass die Pipeline sie nahtlos verarbeiten kann. Ist die Pipeline mit ihren einzelnen Schritten und Connectoren definiert, folgt die Orchestrierung aller Bausteine.
Ein Manager- oder Dispatcher-Modul erlaubt es, neue Datenquellen systematisch anzumelden, ihre spezifischen Pipelines zu erzeugen und anschließend zeitgleich auszuführen. Die Koordination dieser Abläufe ist bei hohen Nutzerzahlen und vielen Verbindungen von zentraler Bedeutung, denn nur so bleibt die Latenz gering und die Nutzererfahrung flüssig. Genau an dieser Stelle entfaltet Ray seine Stärke. Der offene Framework für verteilter Datenverarbeitung nutzt das Konzept der Remote-Functions, mit denen Aufgaben parallel auf mehreren Knoten ausgeführt werden können. Durch die Annotation der wichtigen Pipeline-Schritte mit Ray's remote-Dekorator können mehrere Pipelines gleichzeitig gestartet und überwacht werden.
Dies führt nicht nur zu einer deutlichen Reduzierung der Wartezeiten, sondern ermöglicht auch die horizontale Skalierung durch Hinzufügen weiterer Rechenknoten. Die maximale Skalierbarkeit kann sowohl auf Ebene einzelner Connectors pro Nutzer als auch auf ganzen Datenquellen umgesetzt werden. In einem Szenario, in dem ein Unternehmen mehrere Benutzer mit vielen Datenquellen und unterschiedlichen Connectoren gleichzeitig bedienen muss, lassen sich somit schnell dutzende parallele Pipelines orchestrieren. Ein weiterer Vorteil von Ray liegt in seiner Integration mit dem Python-Ökosystem und seiner einfachen API, die den Einstieg auch für Entwickler erleichtert, die bislang kaum mit verteiltem Computing gearbeitet haben. Die Kombination aus modularer Softwarearchitektur und skalierbarer Verteilungstechnologie ist der Schlüssel dazu, eine Multi-Source-Ingestion-Pipeline zu bauen, die sowohl robust als auch zukunftsweisend ist.
Im Ergebnis entsteht ein adaptives System, das sich ständig weiterentwickelt und leicht an neue Anforderungen oder Plattformen anpassen lässt. Statt ein Flickwerk aus halb integrierten Lösungen entsteht eine klar strukturierte Anwendung, die in größeren Unternehmen die Grundlage für Wissensmanagement, Data Analytics oder Machine Learning-Systeme legt. Natürlich sollte bei der Entwicklung solcher Systeme immer der pragmatische Aspekt nicht außer Acht gelassen werden. Komplexität muss bewusst gesteuert werden, damit die Wartbarkeit nicht leidet. Je nach Projekt kann es sinnvoll sein, bestehende Lösungen heranzuziehen, wenn Anforderungen moderat sind und die Time-to-Market eine hohe Priorität besitzt.
In anspruchsvolleren Szenarien, in denen Flexibilität, Skalierbarkeit und Sicherheitsanforderungen im Vordergrund stehen, lohnt sich die Investition in eine eigene Architektur. Abschließend lässt sich sagen, dass der Aufbau einer Multi-Source-Ingestion-Pipeline mit Ray ein spannendes Beispiel dafür ist, wie moderne Engineering-Prinzipien und leistungsstarke Tools zusammenwirken können, um den steigenden Herausforderungen der Datenverarbeitung zu begegnen. Die richtige Kombination aus bewährten Designmustern, sorgfältiger Planung und zeitgemäßer Technologie ermöglicht es, ein System zu schaffen, das nicht nur heute funktioniert, sondern auch morgen noch flexibel und performant bleibt. Damit wird es möglich, dem Daten-Dschungel Herr zu werden und wertvolle Erkenntnisse aus verstreuten Quellen effektiv nutzbar zu machen.






![Nuclear blasts, preserved on film [video]](/images/63AF7364-5393-4A8D-BEE9-5633B65C93FE)