Die präzise Erkennung von Wortarten, auch bekannt als POS-Tagging (Part-of-Speech-Tagging), gilt als essenzieller Schritt in modernen natürlichen Sprachverarbeitungsprozessen (Natural Language Processing, NLP). Die Qualität des POS-Taggings hat direkten Einfluss auf die Leistungsfähigkeit von Anwendungen wie Grammatikprüfungen, maschineller Übersetzung oder sprachbasierten Assistenzsystemen. Während viele gängige Ansätze auf statistischen oder neuronalen Modellen beruhen, gewinnt eine Methode namens Transformation-Based Learning (TBL) zunehmend an Bedeutung – und das nicht ohne Grund. Transformation-Based Learning bietet einen eleganten Mittelweg zwischen einfachen regelbasierten Systemen und komplexen neuronalen Netzwerken. Entwickelt von Eric Brill in den frühen 1990er Jahren, zeichnet sich diese Technik durch ihre Kombination aus maschinellem Lernen und handkodierten Regeln aus.
Dabei entstehen aus einer anfänglich groben Markierung von Texten systematisch Regeln, die schrittweise die Genauigkeit der Markierungen verbessern. Ein großes Plus von TBL besteht darin, dass es trotz einfacher Methode äußerst genau ist und dabei äußerst geringe Latenzzeiten erzielt – was für viele Anwendungen im Echtzeitbereich entscheidend ist. Um das Prinzip besser zu verstehen, lohnt sich ein Blick darauf, wie herkömmliche POS-Tagging-Methoden funktionieren. Konventionelle Algorithmen setzen häufig auf probabilistische Modelle wie Hidden Markov Models oder Maximum-Entropy-Modelle, bei denen auf Basis großer Textkorpora Wahrscheinlichkeiten für bestimmte Wortarten vergeben werden. Alternativ kommen moderne Transformer-Modelle zum Einsatz, die mittels tiefer neuronaler Netze komplexe Muster in Texten erfassen können.
Obwohl solche Modelle oft eine hervorragende Performance erreichen, bringen sie auch Herausforderungen mit sich: Komplexität, hoher Rechenaufwand und Schwierigkeiten bei der Anpassung an spezifische Anwendungsfälle. Hier setzt Transformation-Based Learning an. Es beginnt mit einer einfachen Basismarkierung, die im schlechtesten Fall lediglich jedem Wort die häufigste mögliche Wortart zuweist. Auf dieser Grundlage bewertet das System Fehler, indem es die Basismarkierung mit einem standardisierten Korpus vergleicht, der als Referenz gilt. Nun werden aus einer vordefinierten Menge an möglichen Regeln, sogenannten Patch-Kriterien, Transformationsregeln abgeleitet, welche das Tagging verbessern können.
Durch wiederholtes Testen und Evaluieren werden jene Regeln ausgewählt, die die Genauigkeit erhöhen, und dauerhaft im System gespeichert. So entsteht nach und nach ein Regelwerk, das die ursprüngliche Markierung optimiert. Ein besonderer Vorteil dieses Verfahrens liegt in der Interpretierbarkeit der Regeln. Da jede Transformation von Menschen nachvollzogen und bei Bedarf angepasst werden kann, sind Entwickler in der Lage, gezielt auf Problemstellungen einzugehen und das System zu verfeinern, ohne gänzlich neue Modelle zu trainieren. Dieser Ansatz führt zu hoher Präzision bei vergleichsweise geringem Rechenaufwand und ermöglicht eine flexible Anpassung an unterschiedliche Sprachvarianten oder Fachgebiete.
Die praktische Umsetzung dieser Methode umfasst den Einsatz sogenannter PatchCriteria. Diese Kriterien analysieren bestimmte Eigenschaften der Wörter im Satz, etwa ob ein benachbartes Wort mit einer bestimmten Wortart getaggt ist oder ob das aktuelle Wort einen bestimmten Textwert hat. Komplexere Regeln kombinieren mehrere dieser Kriterien, um feinere Kontextunterschiede zu erfassen. Beispielsweise kann eine Regel besagen, dass ein Wort nur dann als Konjunktion interpretiert wird, wenn es in unmittelbarer Nähe eines Verbs steht und einen bestimmten Textwert besitzt. Solche präzisen Transformationen erhöhen die Genauigkeit, indem sie Mehrdeutigkeiten im Sprachgebrauch effektiv auflösen.
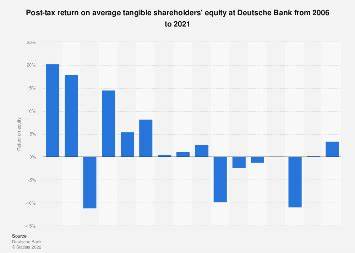
Ein praktisches Beispiel verdeutlicht das Vorgehen: Das Wort „tan“ kann sowohl als Verb („ich will braun werden“) als auch als Adjektiv („ich bin schon braun“) verwendet werden. Ein einfaches Modell würde in diesem Fall nur auf die Wahrscheinlichkeiten zurückgreifen und womöglich das Adjektiv fälschlicherweise als Verb taggen. Durch die Anwendung von Transformationsregeln, die den Kontext um das Wort herum berücksichtigen – zum Beispiel durch die Analyse der benachbarten Wörter und deren Wortarten – kann TBL diese Fehlklassifikation gezielt korrigieren. In der Praxis wurde durch die Implementierung von Transformation-Based Learning das POS-Tagging in bestimmten Systemen von einer Genauigkeit von etwa 40 Prozent auf beeindruckende 95 Prozent gesteigert, ohne dass dies signifikante Auswirkungen auf Verarbeitungsgeschwindigkeit oder Speicherverbrauch hatte. Gerade im Vergleich zu tiefen neuronalen Netzwerken, die oft große Rechenleistung benötigen, zeigt sich hier ein enormes Effizienzpotenzial.
Die geringe Latenz macht TBL-Systeme besonders attraktiv für Anwendungen, bei denen schnelle Reaktionszeiten entscheidend sind, etwa bei Echtzeit-Grammatikprüfungen oder sprachgesteuerten Interfaces. Die Flexibilität von Transformation-Based Learning eröffnet zudem vielfältige Einsatzszenarien. Da die Regelvorlagen relativ leicht erstellt und kombiniert werden können, lassen sich neue Sprachmerkmale oder Besonderheiten mühelos integrieren. Des Weiteren lassen sich die Algorithmen durch den Einbezug zusätzlicher linguistischer Informationen erweitern, wie etwa Nomenphrasen-Erkennung oder Satzgrenzen, um das Tagging weiter zu verbessern. Neben seiner technischen Brillanz punktet Transformation-Based Learning auch im Hinblick auf Wartbarkeit und Weiterentwicklung.
Während neuronale Netzwerke oft als „Black Box“ gelten, können TBL-Modelle transparent analysiert, debuggt und gezielt optimiert werden. Dies führt zu einer besseren Nachvollziehbarkeit der Ergebnisse und ermöglicht eine langfristige Stabilität des Systems. Nicht zuletzt ist die Kombination aus hoher Genauigkeit, geringer Komplexität und adaptiver Regelanpassung ein überzeugendes Argument für den Einsatz von TBL. Mit dem stetigen Fortschreiten der NLP-Forschung und der zunehmenden Verbreitung von Sprachassistenten, automatischen Übersetzungsdiensten und textbasierten Analysetools, gewinnt die Bedeutung von effizienten und präzisen POS-Tagging-Methoden weiter an Bedeutung. Zusammenfassend lässt sich sagen, dass Transformation-Based Learning eine der vielversprechendsten Techniken im Bereich der natürlichen Sprachverarbeitung darstellt.