Im Jahr 2025 hat die Künstliche Intelligenz einen bedeutenden Fortschritt durch die Einführung der Group Relative Policy Optimization, kurz GRPO, erlebt. Dieser neuartige Reinforcement Learning (RL)-Algorithmus, der von DeepSeek entwickelt wurde, stellt eine innovative Alternative zu etablierten Ansätzen wie Proximal Policy Optimization (PPO) dar. GRPO wurde speziell entworfen, um die Herausforderungen bei der Anpassung von RL an große Sprachmodelle (LLMs) zu meistern. Mit der Weiterentwicklung von Flow-GRPO hat sich nun auch die Möglichkeit ergeben, RL auf Flow-Modelle anzuwenden, die insbesondere bei der Bildverarbeitung und -erzeugung von Bedeutung sind. Diese Entwicklungen markieren einen erheblichen Fortschritt für KI-Systeme, die sowohl in der natürlichen Sprachverarbeitung als auch in multimedialen Domänen aktiv sind.
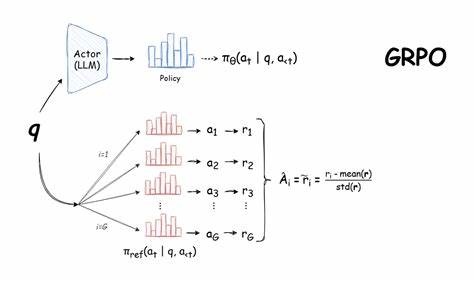
Die traditionelle RL-Methode PPO, eingeführt von OpenAI im Jahr 2017, wurde in zahlreichen Anwendungen erfolgreich eingesetzt, von der Robotik über autonome Systeme bis hin zu Spielagenten. Doch trotz seiner Zuverlässigkeit bringt PPO einige Einschränkungen mit sich – vor allem im Hinblick auf Speicherbedarf und Rechenleistung. PPO basiert auf einem Actor-Critic-Ansatz, was bedeutet, dass zusätzlich zum Entscheidungsmodell ein separates Wertmodell, der sogenannte Kritiker, trainiert werden muss. Dieses Modell benötigt nicht nur erheblichen Speicherplatz, sondern kann sich auch negativ auf die Trainingsgeschwindigkeit und Stabilität auswirken, vor allem bei komplexen und längeren Aufgaben wie der Berechnung von mathematischen Ketten oder ausführlichen Textgenerierungen. Hier setzt GRPO an, indem es die Notwendigkeit eines separaten Kritiker-Netzwerks komplett eliminiert.
Stattdessen bewertet GRPO die Leistung eines Modells nicht anhand eines absoluten Wertmaßes, sondern relativ innerhalb von Gruppen. Durch den Vergleich von Modellausgaben in Gruppen erhält das Modell wertvolle Lernsignale ohne den Overhead zusätzlicher Netzwerke. Diese Innovation ermöglicht eine deutlich effizientere Nutzung der GPU-Ressourcen und beschleunigt den Lernprozess, was besonders bei reasoning-intensiven Aufgaben wie komplexen mathematischen Problemen oder Programmieraufgaben relevant ist. Das Prinzip von GRPO basiert darauf, die Policy-Optimierung auf relativen Vergleichen zu stützen. Anstatt einzelne Aktionen isoliert anhand von Wertschätzungen zu beurteilen, wird eine Rangordnung innerhalb von Ergebnisgruppen erstellt, die anschließend für die Policy-Verbesserung genutzt wird.
Dieses Vorgehen erlaubt es dem Modell, schneller aus seinen eigenen Outputs zu lernen und fördert die Fähigkeit zu langen Chain-of-Thought (CoT)-Überlegungen, bei denen mehrere Denk- und Schlussfolgerungsschritte nacheinander verarbeitet werden. Das erste große Anwendungsbeispiel für GRPO fand sich in den Modellen DeepSeek-R1 und DeepSeek-R1-Zero. Diese Modelle zeigen eindrucksvoll, wie GRPO nicht nur eine Alternative zu PPO darstellt, sondern in einigen Bereichen sogar überlegen ist. Besonders auffällig ist die Fähigkeit, auch bei komplexen mathematischen oder algorithmischen Aufgaben die Genauigkeit signifikant zu steigern, ohne dass dafür eine komplexere Modellarchitektur nötig wäre. Darüber hinaus konnten durch den Wegfall des Kritiker-Netzwerks sowohl Trainingszeit als auch erforderliche Rechenleistung substantiell reduziert werden.
Die jüngste Entwicklung in dieser Reihe ist Flow-GRPO, die es ermöglicht, Reinforcement Learning nicht nur auf Sprach- oder Textmodelle anzuwenden, sondern auch auf Flow-Modelle. Flow-Modelle sind eine Klasse von generativen Modellen, die insbesondere im Bereich der Bildverarbeitung und Bildgenerierung Verwendung finden. Sie zeichnen sich durch ihre Fähigkeit aus, komplexe Verteilungen genau abzubilden, wodurch hochwertige Bilder und visuelle Inhalte erzeugt werden können. Flow-GRPO integriert die Idee von GRPO in das Training von Flow-Modellen und erweitert die Möglichkeiten des RL auf visuelle Domänen. Dabei werden ähnliche Prinzipien angewendet: Anstatt einen separaten Kritiker zu benötigen, bewertet Flow-GRPO die Modellparameter und Outputs auf Basis relativer Gruppenergebnisse, um den Lernprozess effizienter und ressourcenschonender zu gestalten.
Diese Innovation ist besonders spannend, da sie die Brücke zwischen rein sprachbasierten Modellen und multimodalen Modellen schlägt und somit neue Anwendungsbereiche für RL eröffnet. Der Vorteil, den Flow-GRPO gegenüber herkömmlichen RL-Algorithmen bietet, liegt in der besseren Skalierbarkeit und Flexibilität. Das Training von Flow-Modellen ist häufig sehr speicherintensiv und zeitaufwendig, da die Modelle große Mengen an Bilddaten und komplexe Wahrscheinlichkeitsverteilungen verarbeiten müssen. Durch den Verzicht auf ein zusätzliches Kritiker-Netzwerk und die Nutzung relativer Bewertungen kann Flow-GRPO den Ressourcenbedarf signifikant reduzieren, was den Einsatz auch in ressourcenbegrenzten Umgebungen erleichtert. Trotz der vielen Vorteile und Durchbrüche haben sowohl GRPO als auch Flow-GRPO noch Limitationen.
Ein wichtiger Punkt ist, dass das Fehlen eines spezifischen Wertschätzers bedeutet, dass die Lernsignale stark von der Zusammensetzung der Gruppen abhängen, in denen Bewertungen durchgeführt werden. Das kann zu Inkonsistenzen oder zur Notwendigkeit komplizierter Gruppierungsstrategien führen, um stabile Lernergebnisse zu garantieren. Zudem erfordern diese Algorithmen eine sorgfältige Abstimmung der Hyperparameter, um optimale Ergebnisse zu erzielen. In komplexeren realen Umgebungen könnte dies die Anwendung erschweren. Die Integration von GRPO und Flow-GRPO in bestehende KI-Frameworks zeigt dennoch das Potenzial für eine neue Generation von effizienten, leistungsstarken RL-Systemen.
Insbesondere Firmen und Forschungslabore, die mit großen Sprachmodellen und multimodalen KI-Ansätzen arbeiten, profitieren stark von den ressourcenschonenden Trainingsmethoden. Das spart nicht nur Kosten und Zeit, sondern ermöglicht auch die Entwicklung von Modellen, die gleichzeitig hohe Performanz und Erklärbarkeit bieten. In der Praxis eröffnet die Kombination von GRPO und Flow-GRPO neue Möglichkeiten für innovative Anwendungen. Von automatisierten mathematischen Problemlösern über KI-gestützte Codierungsassistenz bis hin zur realistischeren und anpassbaren Bildgenerierung können verschiedenste Bereiche von der verbesserten Lernfähigkeit und Effizienz dieser Algorithmen profitieren. Wissenschaftliche Projekte und industrielle Anwendungen sind gleichermaßen interessiert, da neue RL-Methoden helfen, komplexe Aufgabenstellungen zu bewältigen, die bisher mit herkömmlichen Ansätzen zu ressourcenintensiv oder instabil waren.








