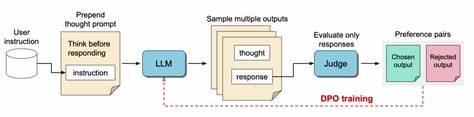
Die rasante Entwicklung großer Sprachmodelle (LLMs) verzeichnete in den letzten Jahren einen bemerkenswerten Fortschritt, insbesondere bei komplizierten Denkaufgaben und der Erzeugung natürlicher Sprache. Modelle, die mit zusätzlichen Mechanismen für logisches Denken ausgestattet wurden, sogenannte Reasoning-enhanced Large Language Models (RLLMs), haben durch gezieltes Training oder durch spezielle Prompting-Verfahren, wie Chain-of-Thought (CoT), beachtliche Erfolge erzielt. Diese Vorgehensweise soll den Modellen eine strukturiertere, nachvollziehbare Denkweise vermitteln, die zu präziseren Ergebnissen bei komplexen Problemen führt. Doch trotz dieser bemerkenswerten Fortschritte offenbart sich ein unerwarteter Nachteil: Die Integration von CoT scheint bei der korrekten Befolgung einfacher bis komplexerer Anweisungen nicht nur Vorteile, sondern auch erhebliche Schwächen mit sich zu bringen.Untersuchungen an 15 unterschiedlichen Modellen mittels der Benchmarks IFEval und ComplexBench zeigen konsistent, dass beim Einsatz von Chain-of-Thought-Prompting die Genauigkeit bei der Ausführung von Anweisungen signifikant abnimmt.
Während IFEval einfache, regelverifizierbare Einschränkungen untersucht, widmet sich ComplexBench komplexen, zusammengesetzten Anforderungen. Das Ergebnis ist überraschend eindeutig: Gerade bei solchen Aufgaben, in denen Präzision und strikte Regelbefolgung im Vordergrund stehen, führt das explizite logische Nachdenken öfter zu Fehlern als zu Verbesserungen.Der Grund für diesen Effekt lässt sich durch tiefgehende Analysen, darunter auch eine aufmerksamkeitsbasierte Untersuchung – „Constraint Attention“ – erklären. Dieser Ansatz beleuchtet, auf welche Teile des Inputs das Modell während seiner Antwortgenerierung den Fokus legt. Die Studien zeigen, dass Chain-of-Thought-Methoden häufig die Aufmerksamkeit des Modells von den wesentlichen Anweisungen weglenken und stattdessen auf irrelevante oder überflüssige Inhalte konzentrieren.
Das führt dazu, dass einfache und klare Regeln vernachlässigt werden oder unnötige Informationen hinzugemischt werden, obwohl sie nicht verlangt sind. Dieses Phänomen ist besonders kritisch in Kontexten, in denen Modelle nicht nur Sprache generieren, sondern auch spezifische Vorgaben exakt umsetzen müssen, wie zum Beispiel in juristischen, medizinischen oder technischen Anwendungen.Interessanterweise zeigen die Untersuchungen aber auch, dass das logische Denken nicht per se nutzlos ist. Es existieren Szenarien, in denen das reasoning der Modelle tatsächlich ihre Leistung verbessert: insbesondere wenn es um formale Aspekte wie die präzise Formatierung, lexikalische Genauigkeit und die Vermeidung kryptischer Fehler geht. Dort trägt die strukturierte Überlegung dazu bei, Fehler zu vermeiden, die bei rein oberflächlicher Spracherzeugung häufig auftreten.
Dennoch überwiegen in vielen Fällen die negativen Auswirkungen, wenn es darum geht, klare, einfache Anweisungen exakt nachzuvollziehen.Um diesem Dilemma zu begegnen, haben die Forscher mehrere innovative Strategien vorgestellt, welche die Schwächen von CoT bei der Instruktionsbefolgung ausgleichen beziehungsweise minimieren sollen. Diese umfassen unter anderem Techniken des in-context learnings, bei denen das Modell durch gezielte Beispiele innerhalb des Promptings seine Aufmerksamkeit besser auf relevante Aspekte lenken kann. Weiterhin wird die Idee der Selbstreflexion verfolgt, bei der das Modell seine eigenen Antworten kritisch überprüft und gegebenenfalls korrigiert. Besonders spannend sind allerdings selektive Reasoning-Methoden, bei denen das Modell zunächst entscheidet, ob ein expliziter Denkprozess für die jeweilige Aufgabe überhaupt notwendig ist.
Hier sticht die sogenannte Classifier-selective reasoning Methode hervor. Dabei wird ein separater Klassifikator eingesetzt, der je nach Komplexität und Art der Aufgabe entscheidet, ob das Modell die Antwort mit oder ohne Chain-of-Thought-Prozess generieren soll. Dieses Vorgehen zeigte sich in den Experimenten als besonders effektiv, da so das Potenzial für reasoning-induzierte Fehler stark reduziert werden kann – ohne dabei auf die Vorteile des logischen Denkens in komplexeren Situationen verzichten zu müssen.Diese neu gewonnenen Erkenntnisse haben weitreichende Implikationen für die künftige Entwicklung von LLMs und deren Anwendung. Erstens zeigen sie auf, dass das einfache Hinzufügen von reasoning-Komponenten nicht automatisch zu besseren Ergebnissen führt.
Vielmehr ist eine differenzierte und situationsabhängige Steuerung notwendig, um die Leistungsfähigkeit der Modelle optimal zu nutzen. Zweitens unterstreichen sie die Bedeutung von Transparenz und Erklärbarkeit in Sprachmodellen: Instrumente wie die Constraint Attention bieten wertvolle Einsichten darüber, wie und warum ein Modell bestimmte Entscheidungen trifft, was für das Vertrauen in KI-Systeme essentiell ist.Nicht zuletzt betonen die Ergebnisse die Bedeutung interdisziplinärer Forschung: Eine enge Zusammenarbeit von KI-Forschern mit Experten aus den Fachgebieten, in denen LLMs eingesetzt werden, ist entscheidend, um dieses Spannungsfeld von logischem Denken und präziser Instruktionsbefolgung zu meistern. Nur so lassen sich Anwendungen entwickeln, die sowohl kreativ als auch zuverlässig agieren.Zusammenfassend kann gesagt werden, dass das Versagen des Denkens in Form von Chain-of-Thought-Prompting bei der Befolgung von Anweisungen ein überraschendes und wichtiges Forschungsfeld eröffnet.
Es erinnert daran, dass künstliche Intelligenz nicht nur mit mehr Komplexität versehen, sondern vor allem klug gesteuert und angepasst werden muss. Die vorgestellten Ansätze zur selektiven Anwendung von reasoning und zur Verbesserung der Aufmerksamkeit auf relevante Instruktionen bieten einen vielversprechenden Weg, um die Flexibilität und Zuverlässigkeit großer Sprachmodelle weiter zu erhöhen. Angesichts der zunehmenden Integration von LLMs in alltägliche und professionelle Anwendungen ist das Verständnis und die Bewältigung dieser Herausforderungen entscheidend für die nächste Generation intelligenter Systeme.



![New Study Confirms That Cancer Cells Ferment Glutamine [video]](/images/727B9F70-1D80-4EFA-8BDD-DECD956AC107)