Die fortschreitende Entwicklung großer Sprachmodelle (LLMs) hat in den letzten Jahren für zahlreiche Innovationen gesorgt, die weit über reine Textverarbeitung hinausgehen. Besonders in spezialisierten Fachgebieten wie der Chemie eröffnen diese Modelle neue Möglichkeiten, Wissen zu extrahieren, Probleme zu lösen und sogar Vorschläge für experimentelle Vorgehensweisen zu generieren. Doch wie gut sind diese KI-Systeme wirklich im Umgang mit chemischem Wissen und chemischem Denken – im Vergleich zu menschlichen Experten? Dieser Frage geht ein aktuelles Forschungsprojekt nach, das das ChemBench-Framework vorgestellt hat, um die Fähigkeiten von LLMs systematisch zu evaluieren und mit der Expertise von Chemikern zu vergleichen. Große Sprachmodelle und ihr Potenzial in der Chemie Große Sprachmodelle sind künstliche Intelligenzen, die auf riesigen Textdatenmengen trainiert wurden, um Zusammenhänge in Sprache zu erkennen und eigene Texte zu generieren. Sie sind in der Lage, nach Belieben Sätze zu vervollständigen, Fragen zu beantworten oder auch komplexe Problemstellungen zu bearbeiten, ohne explizit für jede einzelne Aufgabe trainiert worden zu sein.
Besonders im Forschungsfeld Chemie wird das Potenzial dieser Modelle erkannt, denn ein überwiegender Anteil chemischen Wissens liegt in wissenschaftlichen Publikationen und Textquellen vor – und genau damit können LLMs umgehen. Im Gegensatz zu traditionellen datenbasierten Modellen, die sich meist auf numerische Eigenschaften oder spezifische chemische Reaktionen konzentrieren, bieten LLMs die Möglichkeit, chemisches Wissen im Kontext zu verstehen und flexibel auf unterschiedlichste Fragestellungen zu reagieren. Beispiele hierfür sind die Vorhersage chemischer Eigenschaften, das Planen von Synthesewegen oder das Interpretieren spektraler Daten mithilfe natürlicher Sprache. Das ChemBench-Framework: Ein neuer Standard für Bewertung Das neu entwickelte ChemBench-Framework dient als Benchmark zur Evaluation von LLMs im Bereich Chemie. Es umfasst eine umfangreiche Sammlung von über 2700 wissenschaftlich geprüften Frage-Antwort-Paaren, die eine breite Palette chemischer Themen abdecken.
Die Fragen stammen sowohl aus traditionellen Prüfungen als auch aus automatisch generierten Datensätzen und sind nach Schwierigkeitsgrad sowie Art der erforderlichen Fähigkeiten (Wissen, Rechnen, Argumentation, Intuition) kategorisiert. Entscheidend ist, dass ChemBench nicht nur Multiple-Choice-Aufgaben beinhaltet, sondern auch offene Fragestellungen, die echtes chemisches Denkvermögen erfordern. Außerdem wurde der Komplexität chemischer Probleme Rechnung getragen, indem molekularstrukturelle Informationen in standardisierten Formaten wie SMILES speziell kodiert und vom Modell erkannt werden können. Vergleich der LLM-Leistung mit menschlichen Chemikern Im Rahmen der Untersuchung wurden führende LLMs, sowohl offene als auch proprietäre, auf die ChemBench-Datenbank angewendet. Parallel dazu wurde eine Gruppe von 19 Chemikern unterschiedlicher Fachrichtungen gebeten, dieselben Fragen unter realistischen Bedingungen zu beantworten, wobei einigen Experten auch Werkzeuge wie Websuche und Chemie-Software zur Verfügung standen.
Die Resultate überraschen: Die besten KI-Modelle erzielten auf dem Gesamtdatensatz durchschnittlich bessere Ergebnisse als die besten menschlichen Experten. Dies veranschaulicht die beeindruckende Fähigkeit der Sprachmodelle, umfangreiches Wissen zu konsolidieren und darauf basierende Antworten zu liefern. Gleichzeitig zeigte sich jedoch, dass die Modelle bei bestimmten Grundaufgaben immer noch Schwierigkeiten haben, beispielsweise bei Aufgaben, die tiefgehendes chemisches Faktenwissen und komplexe mechanistische Überlegungen erfordern. Zudem geben sie manchmal übermäßig selbstbewusste Antworten, auch wenn diese falsch sind. Fachgebietsbezogene Unterschiede und Herausforderungen Eine differenzierte Auswertung der Antworten offenbarte, dass die Modelle in Bereichen wie allgemeiner und technischer Chemie oft gut abschneiden, während erhebliche Defizite in spezialisierten Fachgebieten wie Analytischer Chemie oder Fragen zur Toxizität bestehen.
So war etwa die korrekte Vorhersage der Anzahl von Signalen im Kernspinresonanzspektrum eine große Herausforderung, die selbst für erfahrene Chemiker komplex ist. Interessanterweise korrelierte die Performance der Modelle nicht signifikant mit der scheinbaren Komplexität der Moleküle, etwa anhand von molekularen Deskriptoren gemessen. Dies deutet darauf hin, dass die KI-Modelle nicht im eigentlichen Sinne „strukturell“ über Moleküle nachdenken, sondern eher Muster und Ähnlichkeiten aus gelernten Trainingsdaten abrufen und extrapolieren. Desweiteren erwiesen sich das Einschätzen von chemischen Präferenzen oder Intuition, wie sie etwa bei der Auswahl von Kandidaten in der Wirkstoffentwicklung erforderlich sind, als problematisch für die Sprachmodelle. Während menschliche Chemiker hier oft eine gute Übereinstimmung ihrer Entscheidungen aufweisen, zeigen die KI-Modelle hierzu kaum systematisches Verständnis.
Unzuverlässige Selbstbewertung der KI-Modelle Ein relevanter Aspekt beim Einsatz von KI-Systemen ist deren Fähigkeit, Unsicherheiten zu kommunizieren. In der Chemie, wo falsche Angaben erhebliche Konsequenzen haben können, ist das besonders essenziell. Die Studienergebnisse zeigten, dass viele der getesteten Sprachmodelle keine gut kalibrierten Einschätzungen zu ihrer eigenen Antwortsicherheit liefern können. Selbst bei eindeutig falschen Antworten geben manche Modelle sehr hohe Vertrauenswerte an. Diese mangelnde Zuverlässigkeit erschwert den unkritischen Einsatz der Modelle in sicherheitsrelevanten oder hochkomplexen Szenarien.
Auswirkungen und Perspektiven für Forschung und Lehre Die Tatsache, dass moderne LLMs in vielen Bereichen der Chemie die durchschnittlichen Leistungen erfahrener Experten übertreffen können, wirft neue Fragen für die Lehre und Ausbildung auf. Insbesondere wird deutlich, dass reines Auswendiglernen von Fakten an Bedeutung verliert, während Kritisches Denken, tiefes Verständnis und die Fähigkeit zur Anwendung von Wissen in unbekannten Kontexten zentrale Kompetenzen bleiben. Gleichzeitig bieten die Modelle enormes Potenzial als unterstützende Werkzeuge oder sogenannte „Chemie-Copiloten“, die nicht nur Informationen bereitstellen, sondern auch bei der Planung von Experimenten, Literaturrecherchen und Hypothesengenerierung assistieren können. Damit wird die Zusammenarbeit von Mensch und Maschine zum Schlüssel erfolgreicher chemischer Forschung. Sicherheitsbedenken und ethische Gesichtspunkte Mit den wachsenden Fähigkeiten von LLMs entstehen auch neue Risiken, vor allem im Hinblick auf den Missbrauch durch unbefugte Personen bzw.
zum Zweck der Herstellung gefährlicher oder toxischer Stoffe. Da die Modelle selbst grundlegende Sicherheitsaspekte oftmals nur unzureichend einschätzen und kommunizieren können, ist ein verantwortungsvoller Umgang und die Implementierung von Kontrollmechanismen unerlässlich. Eine weitere Herausforderung ist die Zugänglichkeit der Modelle für Laien, etwa Studenten oder die allgemeine Öffentlichkeit, die ohne fachliche Kontrolle falsche oder irreführende Information erhalten könnten. Hier ist eine klare Kommunikation der Grenzen der KI erforderlich, ebenso wie die Entwicklung von Systemen, die zuverlässige Warnhinweise generieren oder fehlerhafte Aussagen erkennen können. Die Rolle von spezialisierten Datenbanken und Tool-Integration Es zeigte sich, dass die Wissensdatenbanken, auf denen die Modelle trainiert sind, nicht alle notwendigen und relevanten Fakten für eine umfassende Beantwortung von chemischen Fragen abdecken.
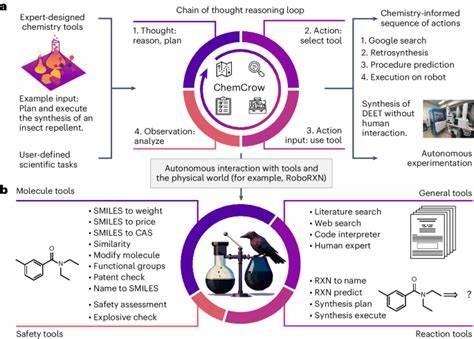
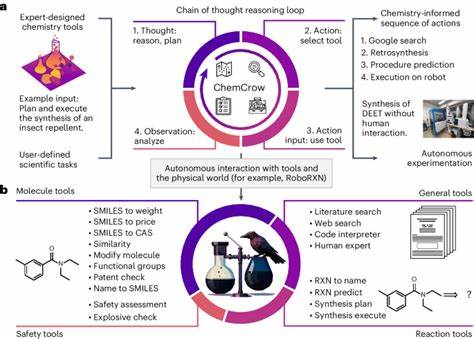
Zwar kann die Integration von externen Suchwerkzeugen Verbesserungen bringen, wie etwa bei agentenbasierten Systemen, die Forschungsarbeiten durchsuchen, doch fehlen häufig spezialisierte Datenquellen wie PubChem oder Gestis, die für viele Fragen unerlässlich sind. Dies legt nahe, dass zukünftige Weiterentwicklungen von KI-Systemen in der Chemie verstärkt Hybridlösungen implementieren werden, welche breite Sprachmodelle mit Fachdatenbanken, Softwaretools und Rechnern vernetzen, um spezifische und korrekte Antworten zu bieten. Fazit Die Erforschung der Fähigkeiten großer Sprachmodelle im Vergleich zum Wissen und zur Denkweise menschlicher Chemiker ist ein spannendes Feld mit weitreichenden Implikationen für Wissenschaft, Bildung und Sicherheit. Die präsentierten Ergebnisse zeigen einerseits die beeindruckenden Leistungen moderner KI-Systeme, die in vielen klassischen Tests und Aufgaben menschliche Experten übertreffen können. Andererseits offenbaren sie auch wesentliche Schwächen, insbesondere bei komplexem reasoning, Intuition und in der zuverlässigen Einschätzung von Unsicherheiten.