In der heutigen, datengetriebenen Welt stellt die effiziente und zuverlässige Erfassung von Datenänderungen eine der zentralen Herausforderungen für moderne Unternehmen dar. PhysicsWallah, ein bekanntes EdTech-Unternehmen, das auf umfangreiche MongoDB-Datenbanken setzt, hat kürzlich einen wegweisenden Schritt unternommen, indem es von Debezium auf die CDC-Lösung von olake.io umgestiegen ist. Diese Veränderung markiert nicht nur einen technologischen Wandel, sondern bietet auch wertvolle Einsichten in die Praktikabilität und Weiterentwicklung von Dateninfrastruktur für große, verteilte Systeme. Change Data Capture wird zunehmend unverzichtbar für Organisationen, die Echtzeit-Datenintegration, schnelle Analysen und zuverlässige Datenpipeline-Prozesse sicherstellen wollen.
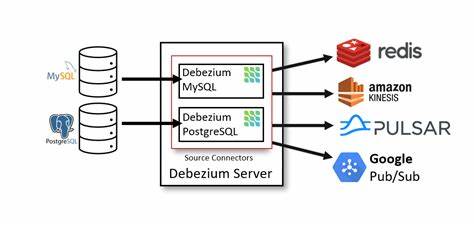
Traditionell basierte eine weit verbreitete Methode zur Implementierung von CDC auf Tools wie Debezium, das über Kafka als Messaging-Plattform funktioniert. Während dieses Setup viele Vorteile bot, zeigten sich insbesondere bei großen, komplexen Systemen wie bei PhysicsWallah auch Einschränkungen, die letztlich zu einem Wechsel führten. Ein Hauptproblem bei Debezium war die Durchführung von sogenannten Voll- und Inkrememtalladungen der Datenbestände in den MongoDB-Collections, die Millionen von Zeilen umfassen. Hier traten langwierige Ladezeiten auf, die beim Auftreten von Fehlern oft dazu führten, dass der gesamte Prozess von vorn begonnen werden musste. Diese mangelnde Resilienz kostete wertvolle Ressourcen und führte zu Verzögerungen im Data-Warehouse-Betrieb, was sich negativ auf die Analysezeiten und die Aktualität der Daten auswirkte.
Zudem wurde die Kafka- und Connect-Infrastruktur als zu schwergewichtig empfunden. Wenn das eigentliche Ziel darin besteht, Parquet- oder Iceberg-Tabellen auf S3 zu erstellen, wirkt der Umweg über Kafka mit seinen komplexen Clustern und den dazugehörigen Komponenten oft als Overhead. Das erhöhte die Anforderungen an Wartung und Betrieb und führte zu steigenden Betriebskosten. Die Handhabung von heterogenen Arrays in MongoDB erforderte zudem speziell angepasste Single Message Transforms (SMTs), was zusätzliche Entwicklungsarbeit und Fehlerquellen bedeutete. Ein weiterer technischer Nachteil war die ausschließliche Unterstützung von Continuous Streaming.
Dies bedeutete, dass bestimmte Batch-Workflows mit separaten, losen Prozessen realisiert werden mussten, die nicht nahtlos mit dem Streaming harmonierten. Außerdem verursachte der permanente Schema-Drift in den MongoDB-Datenbanken ein kontinuierliches Umcodieren, um die Iceberg-Tabellen syntaktisch und semantisch konsistent zu halten. In der Summe führte dies zu einem erhöhten Entwicklungs- und Wartungsaufwand. Vor diesem Hintergrund entschied sich das Engineering-Team von PhysicsWallah für einen Wechsel zu olake.io, das eine komplett neue Architektur zur Datenintegration anbot.
Grundlegend verändert olake.io die Pipeline, indem es den Zwischenschritt über eine Messaging-Plattform wie Kafka eliminiert. Stattdessen schreibt die Pipeline direkt von den Quellsystemen, in diesem Fall MongoDB, in Apache Iceberg – einem open-source Datenspeicher-Format, das moderne Anforderungen an Skalierbarkeit, Schema-Evolution und Abfrageperformance erfüllt. Besonders überzeugend an olake.io ist die Fähigkeit, Full Loads und CDC nahtlos in einer Pipeline zu kombinieren und über einen einzigen Schalter in der Jobkonfiguration zu steuern.
Die Infrastruktur unterstützt resiliente Voll-Ladevorgänge, die bei Unterbrechungen wie Pod-Crashes nicht von vorne beginnen müssen, sondern an der letzten Position fortgesetzt werden. Dies reduziert Ausfallzeiten und erhöht die Robustheit des ETL-Prozesses erheblich. Die automatische Schema-Evolution ist ein weiterer großer Vorteil. Neue oder geänderte Felder in MongoDB werden automatisch als nullable Spalten in den Iceberg-Tabellen abgebildet, wodurch manuelles Eingreifen minimiert wird. Komplexe, verschachtelte Dokumente aus MongoDB landen als JSON-Strings in der Tabelle, die später bei Bedarf flexibel weiterverarbeitet werden können.
So wird das Thema Schema-Drift elegant und effizient gehandhabt. Das Deployment erfolgt flexibel entweder über Kubernetes CronJobs oder Airflow-Tasks, was mit einem einzigen YAML- oder JSON-Konfigurationsfile gesteuert wird. Dieses einfache Setup erleichtert die Integration in bestehende Orchestrierungs- und Monitoring-Tools und erlaubt eine einfache Skalierung gemäß den jeweiligen Anforderungen. Die resultierende Datenpipeline bei PhysicsWallah sieht daher folgendermaßen aus: MongoDB als Quellsystem, die direct-write Pipeline von olake.io als Datenstromerzeuger, Apache Iceberg auf Amazon S3 als persistenter Datenspeicher, mit Spark-Jobs zur Datenverarbeitung und Trino als Abfrage-Engine.
Ergänzend wird gelegentlich Redshift zum Einsatz gebracht. Die Gesamtheit wird über Airflow oder Kubernetes orchestriert und automatisiert. Diese Architektur zeigt eine moderne, optimierte Herangehensweise an das Thema CDC, die zugunsten von Zuverlässigkeit, Wartbarkeit und Wirtschaftlichkeit den Umweg über klassische Brokerinnenfrastrukturen vermeidet. Insbesondere für Unternehmen, die ausschließlich Iceberg-Tabellen als Zielobjekt sehen und keine komplexen Kafka-Konsumenten benötigen, kann der direkte Weg von der Datenquelle zum Data Lake erhebliche Vorteile bieten. Die Erfahrungen von PhysicsWallah sollten nicht isoliert betrachtet werden.
Sie sind Teil eines breiteren Trends, der im modernen Datenmanagement vermehrt auf Simplizität, Resilienz und automatische Anpassungsfähigkeit setzt. Die Entwicklung von Tools wie olake.io zeigt, dass der Markt zunehmend bereit ist, traditionelle Architekturkonzepte zu hinterfragen und innovative Lösungen hervorzubringen, die den Bedürfnissen großer, wachsender Datenlandschaften gerecht werden. Unternehmen, die ähnliche Herausforderungen wie PhysicsWallah mit wachsenden MongoDB-Datenbeständen, komplexen Schemata und Elimination von redundanten Infrastrukturkomponenten haben, finden in olake.io möglicherweise eine interessante Alternative.