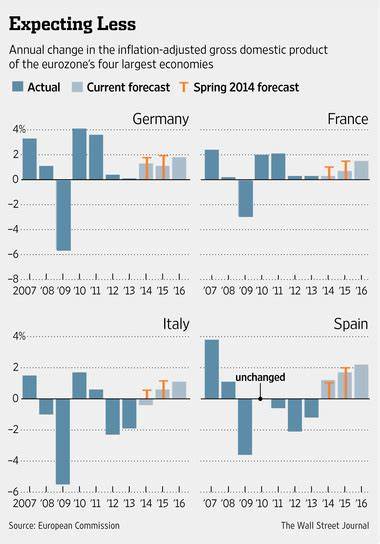
Das Voynich-Manuskript ist zweifellos eines der rätselhaftesten Dokumente der Weltgeschichte. Seit seiner Entdeckung beschäftigt es Historiker, Kryptographen und Linguisten gleichermaßen. Das Manuskript ist bekannt für seine unlesbare Schrift, die bislang keiner bekannten Sprache oder Schriftart zugeordnet werden konnte. Die Bedeutung des Textes bleibt bis heute unbekannt, wobei die Transliteration eine der vielversprechendsten Methoden darstellt, um Ordnung in das komplexe Schriftsystem des Manuskripts zu bringen und eine computerbasierte Analyse zu ermöglichen. Transliteration ist ein Prozess, bei dem handgeschriebene Schriftzeichen in computerlesbare Symbole umgewandelt werden.
Dabei geht es nicht um eine Übersetzung oder Umschrift im eigentlichen Sinne, sondern um eine symbolgenaue Übertragung der ursprünglichen Zeichen in eine digitale Form. In Bezug auf das Voynich-Manuskript bedeutet dies, jedem einzelnen, handschriftlich erstellten Charakter eine konsistente Entsprechung im digitalen Alphabet zuzuordnen. Diese Vorgehensweise erlaubt, trotz fehlendem Verständnis der eigentlichen Sprache oder Bedeutung, statistische Auswertungen und Vergleiche der Zeichen abzubilden. So können Muster erkannt und Hypothesen entwickelt werden, die auf reinen Textdaten basieren. Die Anfänge der Transliteration reichen bis in die Mitte des 20.
Jahrhunderts zurück. Besonders hervorzuheben ist die Arbeit des sogenannten First Study Groups (FSG) um William Friedman, einem der bekanntesten und einflussreichsten Kryptologen seiner Zeit. In den 1940er Jahren begann das FSG mit der ersten systematischen Transliteration wesentlicher Textteile des Voynich-Manuskripts anhand von Fotokopien. Die Gruppe entwickelte ein eigenes Alphabet bestehend aus Großbuchstaben und Zahlen, das Zeichen des Manuskripts in eine maschinenverarbeitbare Form brachte. Allerdings war diese Transliteration nie vollständig, da sich die Forscher auf den linearen Fließtext konzentrierten und schwierige Abschnitte wie kreisförmige Beschriftungen oder komplizierte Diagramme bewusst ausließen.
Durch diese eigenständige Methode legten sie dennoch eine solide Grundlage für spätere Untersuchungen. Die Transliteration von William R. Bennett Anfang der 1970er Jahre stellte eine weitere wichtige Station dar. Für seine computergestützte Sprachanalyse entwickelte er ein völlig eigenes Alphabet, das allerdings in der Fachwelt keine breite Anwendung fand. Weniger bekannt ist die Rolle Jonina Duker, einer damals noch jungen Studentin, die Bennett bei der Analyse unterstützte.
Eine fundamentale Veränderung brachte Ende der 1970er Jahre der Kryptanalytiker Prescott Currier mit seinem von ihm selbst entworfenen Alphabet. Seine Zeichenkodierung umfasste das gesamte lateinische Großbuchstaben- sowie Ziffernarsenal, was eine deutlich umfassendere Repräsentation der Voynich-Zeichenwelt ermöglichte. Bemerkenswert ist die Zusammenarbeit mit Mary D'Imperio, die zeitgleich mit einem eigenen Alphabet arbeitete, sich aber schließlich für Curriers System entschied. Dadurch entstand ein vereintes Alphabet, das bis in die 1990er Jahre als Standard galt und auch zum frühen Internetbestandteil wurde. Die unterschiedlichen Alphabete zeigen jedoch, dass es zwischen den Forschern keine Einigkeit darüber gab, welches Zeichen genau einen Buchstaben oder eine Einheit darstellt.
So lassen sich viele der Voynich-Zeichen als Ligaturen mit mehreren Teilen deuten. Jim Reeds prägte hierfür den Ausdruck der „rare characters“ – seltene oder eigenartige Zeichen, die in keiner der bisherigen Alphabete vollständig abgebildet wurden. Dies führte zur Einführung von speziellen Bezeichnungen von ‚X1‘ bis ‚X128‘, um diese einzigartigen Formen erfassen zu können. Mit dem Aufstieg des Internets in den 1990er Jahren erhielt die Transliteration neuen Aufwind. Die Nutzer der frühen Voynich-Mailinglisten setzten die Arbeit fort und erweiterten Curriers Alphabet um Kleinbuchstaben, um auch zuvor fehlende Zeichen zu berücksichtigen.
Parallel entwickelte Jacques Guy das sogenannte Frogguy-Alphabet, ein innovatives System, das nicht ganze Zeichen abbildete, sondern die einzelnen Striche und Minims, aus denen die Buchstaben bestehen. Diese Herangehensweise brachte eine sehr nahe Darstellung der Schriftform und ermöglichte erstmals eine genaue Wiedergabe von Ligaturen und verschmolzenen Zeichen. Guy führte zudem eine Kapitalisierungsregel ein, die Verbindungen zwischen Zeichen kenntlich macht und somit eine realistischere Erfassung des Textflusses erlaubte. Trotz seines Potenzials kam das Frogguy-Alphabet aber aufgrund seiner Komplexität und des häufigen Gebrauchs von Apostrophen nicht zu bedeutenden transliterierten Texten. Auf Grundlage von Guy’s Arbeiten entwickelten Gabriel Landini und René Zandbergen das sogenannte EVA-Alphabet (Extensible Voynich Alphabet), das seit den 2000er Jahren zum verbreitetsten Standard wurde.
Mit EVA wurde erstmals versucht, ein superset aller bisherigen Alphabete zu schaffen, das sowohl einfach in der Handhabung ist als auch alle bisher bekannten Zeichen vollständig abbilden kann. Es erlaubt die konsistente, reversible Übersetzung in frühere Alphabete und unterstützt auch seltene Zeichen durch spezielle Zusatzcodes. EVA verzichtet auf Sonderzeichen wie Apostrophe und sichert trotzdem eine sehr genaue Schriftwiedergabe. Dank seines Aufbaus ist es zudem besonders gut geeignet, um computerbasierte Analysen durchzuführen und eine standardisierte Datenbasis zu schaffen. Eine weitere Bereicherung brachte Takeshi Takahashi aus Japan, der EVA in umfassender Weise nutzte und erheblich erweiterte.
Seine Version ermöglichte eine nahezu vollständige digitale Transliteration des Manuskripts, basierend auf einer detaillierten Kopie des Originals. Die sogenannten capitalised EVA-Zeichen dienen der Darstellung von Figuren mit Aufständen oder „benched“ Zeichen, die im Manuskript mehrfach vorkommen. Takahashis Transliteration wird heute häufig als Referenz betrachtet und ist in wissenschaftlichen Kreisen anerkannt. Parallel zur Verbreitung des EVA-Formats entstanden wichtige ergänzende Projekte, etwa die Landini-Stolfi Interlinear Datei (LSI). Sie sammelt verschiedene ältere transliterierte Versionen und stellt sie nebeneinander zum Vergleich dar.
Dies erleichtert das Studium von Unterschieden und Gemeinsamkeiten der Transliterationen erheblich und dient als wichtige Datengrundlage für Forschungen. Im neuen Jahrtausend versuchte auch Glen Claston mit dem v101-Alphabet das Problem zu adressieren, indem er ein völlig eigenes zweiseitiges System schuf, das bis zu 299 verschiedene Zeichen umfasst. Seine Herangehensweise benutzt spezielle ASCII-Zuweisungen und ein fontbasiertes Rendering, was eine sehr präzise Darstellung des Manuskripts ermöglicht. Das v101-Alphabet berücksichtigt zudem Varianten einzelner Zeichen, die in früheren Alphabetsystemen als gleich angesehen wurden, und versucht so den feinen schriftlichen Nuancen gerecht zu werden. Obwohl das System technisch anspruchsvoll ist, wurde es bislang weniger weit verbreitet als EVA.
Bis etwa 2017 gab es keine einheitliche Standardsprache für Transliteration. Das erschwerte die Zusammenarbeit zwischen Forschern sowie die Nachvollziehbarkeit der Ergebnisse erheblich. Unterschiedliche Formate, unklare Loci-Beschreibungen und unterschiedliche Zeichenbelegungen sorgten für Verwirrung. Die Herausforderung lag insbesondere darin, digitale Dateien so anzulegen, dass sie sowohl den Text als auch seine genaue Position im Manuskript erfassen – sogenannte Loci. Nur mit diesen Informationen ist eine präzise Zuordnung zu bestimmten Passagen möglich.
Die Lösung kam mit der Entwicklung des IVTFF-Formats (Intermediate Voynich Transliteration File Format), das erstmals eine umfassende Vereinheitlichung mit Metadaten, Seitenvariablen und klarer Locus-Struktur ermöglichte. Es erlaubt die Integration der bekannten Haupttransliterationen, etwa FSG, Currier/D’Imperio, Takahashi, Zandbergen-Landini und Claston, in einem gemeinsamen, durchsuchbaren sowie standardisierten Dateiformat. Dies bedeutete einen Durchbruch bei der patentierten Standardisierung. Eine weitere Herausforderung bestand darin, die unterschiedlichen Alphabete zu vereinen. Die Einführung des STA (Super Transliteration Alphabet) löste dieses Problem elegant, indem es ein synthetisches, zweistelliges System einführte, das auf zwei ASCII-Zeichen basiert und Familien von ähnlichen Zeichen zusammenfasst.
Die Familie wird durch einen Großbuchstaben definiert, die individuellen Mitglieder durch einen weiteren Buchstaben oder eine Ziffer. Dieses System erlaubt die umfassende Abbildung sämtlicher bisheriger Alphabete und ist insbesondere für computerbasierte Vergleiche ideal. Im Zuge dieser Arbeiten entstand neben STA auch das AAA-Alphabet (Analytisches Alignment-Alphabet), das sich auf eine detaillierte Analyse und den Vergleich zweier Vollversionen der Transliterationen spezialisiert hat. Es ist besonders ausführlich, beschreibt einzelne Strichbestandteile und Verbindungsdetails und bietet somit eine Grundlage für algorithmische Zuordnungen und Textanalysen auf einem bislang unerreichten Präzisionsniveau. Ein wichtiger Meilenstein war die Erschaffung der sogenannten Referenztransliteration (Code RF), die auf der automatisierten Kombination der ZL- und GC-Transliterationen beruht.
Sie erfüllt den Zweck, eine möglichst vollständige und konsistente digitale Textbasis zu schaffen, mit der weitere wissenschaftliche Analysen und Vergleichsstudien durchgeführt werden können. Dabei wird bewusst auf subjektive Interpretationen verzichtet, damit die rohe Vorlagenform bestmöglich erhalten bleibt. Heute sind verschiedene Transliterationstexte in standardisierten Formaten verfügbar und werden von Forschern weltweit genutzt, um das Voynich-Manuskript weiter zu beleuchten. Digitale Werkzeuge wie IVTT ermöglichen das selektive Filtern und die individuelle Bearbeitung der umfangreichen Datenmengen. Zudem erlauben moderne True-Type-Fonts, die transliterierten Texte im originalgetreuen Erscheinungsbild darzustellen, was die Lesbarkeit und Nachvollziehbarkeit für Experten und Interessierte erheblich verbessert.
Trotz all dieser Fortschritte bleibt die Transliteration eine Herausforderung. Die Unklarheiten, welche Zeichen als eigenständige Einheiten zu betrachten sind und wo Wortgrenzen verlaufen, beeinflussen bis heute die Ergebnisse. Manche Zeichen sind mehrdeutig, Schreibvarianten sind häufig und handschriftliche Eigenheiten erschweren objektive Entscheidungen. Software-gestützte Optische Zeichenerkennung (OCR) für das Voynich-Manuskript könnte hier zukünftig entscheidend helfen, ist aber bislang in der Entwicklungsphase. Die bedeutende Rolle der Transliteration liegt in ihrer Funktion als Schlüssel zur computerbasierten Erforschung des Manuskripts.
Durch die akkurate digitale Abbildung des Textes können statistische Analysen vorgenommen, Frequenzen ermittelt und Muster entdeckt werden, die sprachlich oder symbolisch neue Erkenntnisse bringen könnten. Dies ist der erste notwendige Schritt auf dem langen Weg zur möglichen Entzifferung oder zumindest einer besseren Verständnisgrundlage. Abschließend lässt sich sagen, dass die Transliteration des Voynich-Manuskripts ein faszinierendes Beispiel für die Verbindung aus alter Handschrift und modernster Technologie ist. Die Vielfalt der Alphabete und Systeme spiegelt den langen Weg und die intensive Forschungsarbeit wider, die sich über Jahrzehnte erstreckt hat. Mit der Einführung einheitlicher Formate und umfassender Superset-Alphabete sind die Grundlagen gelegt, damit künftige Generationen von Wissenschaftlern das Geheimnis dieses Manuskripts immer weiter ergründen können.
Die Arbeit ist also nicht beendet, sondern mit der Transliteration ein neuer Anfang gemacht worden, der das Tor zu weiteren Entdeckungen öffnen wird.