In den letzten Jahren hat sich gezeigt, dass Künstliche Intelligenz (KI) und insbesondere KI-Modelle zu einem zentralen Bestandteil moderner Softwareanwendungen geworden sind. Diese Modelle stellen jedoch neue Anforderungen an die Software- und Hardware-Architekturen, die bisher in der containerorientierten Entwicklung kaum berücksichtigt wurden. Die Komplexität und der intensive Ressourcenbedarf von KI-Modellen verlangen nach einer neuen Herangehensweise, wie sie effizient und benutzerfreundlich lokal sowie in Containerumgebungen betrieben und verwaltet werden können. Docker hat mit der Einführung des Docker Model Runner einen wichtigen Schritt gemacht, um genau diese Anforderungen zu adressieren und Entwicklern einen leistungsfähigen, flexiblen und modularen Weg zu bieten, KI-Modelle in ihre Workflows zu integrieren. Die Zielsetzung bei der Entwicklung des Docker Model Runner war es, eine Lösung zu schaffen, mit der Nutzer KI-Modelle lokal ausführen und sowohl von Containern als auch von Host-Prozessen darauf zugreifen können.
Dieses Ziel klingt zunächst einfach, doch im Hintergrund eröffnete sich ein großes Feld technischer Herausforderungen. Eine kleine Entwicklergruppe musste dabei vorgegebenen Zeitplänen gerecht werden, ohne dabei die Nutzererfahrung zu beeinträchtigen. Daraus ergaben sich mehrere zentrale Designprinzipien, die die Basis für die erfolgreiche Umsetzung bildeten und gleichzeitig Spielraum für zukünftige Erweiterungen ließen. Eines der wichtigsten Prinzipien war die Unterstützung mehrerer Backend-Engines. Da Docker selbst nicht auf die Entwicklung von Low-Level-Inferenz-Engines spezialisiert ist, setzte man auf bewährte Open-Source-Lösungen wie llama.
cpp, vLLM, MLX, ONNX und PyTorch. Die Wahl fiel für die erste Version auf llama.cpp, da es bereits eine Schnittstelle für die OpenAI API unterstützte und damit schnelle Integration ermöglichte. Gleichzeitig wurde die Architektur so gestaltet, dass weitere Backend-Engines problemlos ergänzt werden können. Dies garantiert Flexibilität und Zukunftssicherheit bei der Entwicklung.
Die Integration der OpenAI API als standardisierte Inferenzschnittstelle war eine strategische Entscheidung, die die Kompatibilität mit einer Vielzahl von bestehenden Tools gewährleistet. Docker wollte so die Akzeptanz der Lösung maximieren, da viele Nutzer bereits mit der OpenAI API vertraut sind. Obwohl die vollständige Abdeckung aller OpenAI API-Endpunkte noch in Arbeit ist, bildet diese Basis eine komfortable Ausgangsbasis für viele Anwendungsszenarien. Die Nutzung von llama.cpp bot zudem einen unkomplizierten Einstieg, da ein Server mit OpenAI-API-kompatibler Schnittstelle als Ausgangsbasis verwendet werden konnte.
Darüber hinaus wurde bei Docker Model Runner besonders darauf geachtet, KI-Modelle als eigenständige und gleichberechtigte Entitäten im Docker-Ökosystem zu behandeln. Modelle haben einen anderen Lebenszyklus als typische Containerprozesse und konnten deshalb nicht einfach unter den bestehenden Containern verwaltet werden. Deshalb wurden spezielle API-Endpunkte (/models) geschaffen, die die Verwaltung und den Betrieb von Modellen analog zu Images oder Netzwerken ermöglichen. Dies hebt Modelle auf eine neue, zentrale Ebene innerhalb des Docker-API-Designs und sorgt für eine klarere und intuitivere Handhabung. Eine entscheidende technische Herausforderung war die Unterstützung von GPU-Beschleunigung für Inferenzprozesse.
KI-Modelle erfordern hohe Rechenleistung, die ohne GPU-Unterstützung kaum praktikabel wäre. Die klassische Übergabe von GPU-Ressourcen durch eine VM, wie sie bei Docker Desktop üblich ist, stellte jedoch eine Schwierigkeit dar, da dies instabil oder sogar unmöglich sein kann. Docker fand eine pragmatische Lösung, indem die Inferenz außerhalb der Docker Desktop VM ausgeführt und API-Aufrufe lediglich an den Host weitergereicht werden. Das minimiert Risiken und verbessert die Leistungsfähigkeit, auch wenn damit neue Sicherheitsaspekte berücksichtigt werden müssen. Dabei kommt das Docker MCP Toolkit zum Einsatz, das es ermöglicht, komplexe Werkzeuge und Operationen in isolierten temporären Containern auszuführen.
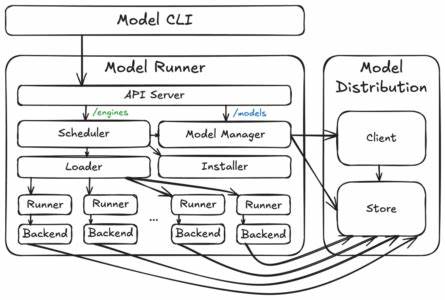
So bleiben etwaige Seiteneffekte beherrschbar. Die Architektur des Docker Model Runner ist modular aufgebaut und besteht aus drei zentralen Komponenten: dem Model Runner, dem Model Distribution Tooling und dem Model CLI Plugin. Diese Modularität ermöglichte es dem kleinen Team, die Entwicklung parallel voranzutreiben und dennoch klare Schnittstellen einzuhalten. Das erleichterte nicht nur die Iteration, sondern vereinfacht auch die Integration in unterschiedliche Plattformen wie Docker Desktop oder Docker CE. Im Kern bildet der Model Store die Basis, in dem die Modelldaten gespeichert werden.
Diese werden separiert von Container-Images gehalten, da sie unkomprimierbar sind und direkt vom Inferenz-Engine-Prozess benötigt werden. Die Model Distribution ermöglicht es, Modelle effizient aus OCI-Registern zu ziehen und aktuell zu halten. Der Model Runner selbst koordiniert die Ausführung der Modelle, verwaltet den Speicher und sorgt für eine effiziente Nutzung der Ressourcen. Sogar ein dynamischer Installer ist integriert, mit dem Nutzer beispielsweise CUDA-Unterstützung aktivieren können, ohne große Pakete vorab installieren zu müssen. Die API-Struktur teilt sich in zwei Bereiche auf: Docker-ähnliche Endpunkte für Operations wie Modell-Pulling oder Listing und OpenAI-kompatible Endpunkte für Inferenzanfragen wie Chat Completions oder Embeddings.
Diese APIs sind auf verschiedenen Wegen erreichbar, zum Beispiel über den Docker-Socket oder spezielle TCP-Endpunkte, je nach Betriebssystem und Docker-Version. Docker Desktop profitiert von der engen Integration in den Desktop-Backendprozess, während Docker CE auf eine Container-basierte Umsetzung setzt, die sich flexibler und unabhängiger von Host-Systemprozessen gestaltet. Die ersten Schritte der Implementierung konzentrierten sich auf macOS mit Apple Silicon, da hier eine homogene Plattform für das Testing und die Entwicklung zur Verfügung stand. Im Anschluss konnten die Funktionen auf weitere Plattformen wie Windows (mit x86_64 und ARM64) sowie auf GPU-Varianten portiert werden. Dabei zeigte sich speziell unter Windows die Herausforderung großer Binärdateien, weswegen GPU-Unterstützung optional per dynamischem Installer hinzugefügt wird.
Für die Integration in Docker CE wurde der Docker Model Runner bewusst als reguläres CLI-Plugin gestaltet, um ohne Sonderrechte auskommen zu können. In diesem Szenario läuft der Model Runner in einem dedizierten Container und nutzt volumebasierte Speicherung für die Modelle, was eine einfache Installation, Aktualisierung und Deinstallation ermöglicht. Allerdings ist an dieser Stelle die API-Verfügbarkeit über den nativen Docker-Socket noch nicht realisiert, stattdessen erfolgt der Zugriff über einen TCP-Host-Port. Auch hier wird an einer komfortableren Lösung gearbeitet. Blickt man in die Zukunft, so stehen vielfältige Erweiterungen und Verbesserungen an.
Die Integration von weiteren Backends wie vLLM, das bei vielen Unternehmen bereits zum Einsatz kommt, steht auf der Agenda. Ebenso wird die Kompatibilität mit der OpenAI API kontinuierlich erweitert, um möglichst viele Anwendungsfälle abzudecken und vorhandene Tools optimal zu unterstützen. Die Nutzeroberflächen – sowohl über die Befehlszeile als auch im Docker Desktop Dashboard – erhalten zusätzliche Funktionen für eine bessere Sichtbarkeit und Steuerung der ausgeführten Modelle. Langfristig öffnet sich das Projekt einer Integration mit containerd, dem modularen Container-Laufzeitsystem, um die Ausführung und Verwaltung von Modellen noch performanter und sicherer zu gestalten. Eine engere Verzahnung mit dem Moby-Projekt könnte zudem dazu beitragen, dass Docker Model Runner besser ins Docker-Ökosystem eingebunden wird, inklusive der Docker-API-Dokumentation.