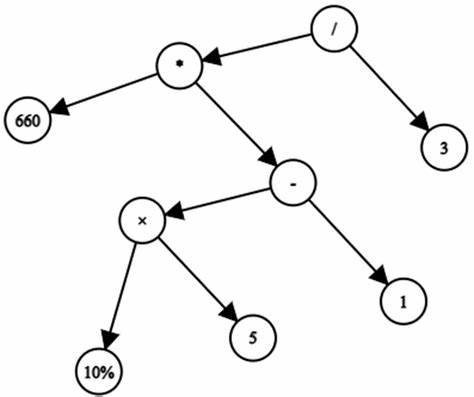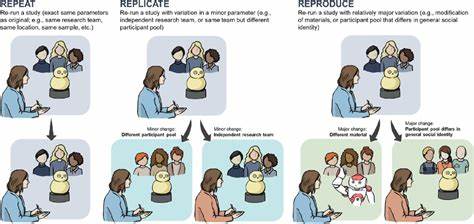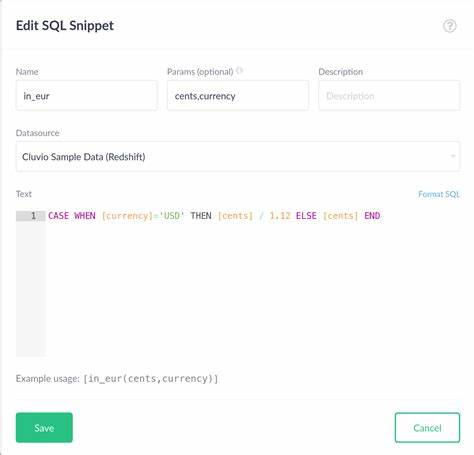
Daten sind das Herzstück moderner Technologien und bilden die Grundlage für nahezu alle Entwicklungen im Bereich des maschinellen Lernens und der künstlichen Intelligenz. Dennoch zeigt sich überraschend oft, dass die Herkunft, Qualität und Zugänglichkeit dieser Daten überhaupt nicht hinreichend hinterfragt werden. Viele Forschungseinrichtungen und Unternehmen setzen auf sogenannte Open Data, also frei zugängliche Datensätze, um ihre Algorithmen zu trainieren oder neue Erkenntnisse zu gewinnen. Doch Open Data ist nicht gleich Open Data. Hinter dem Begriff verbirgt sich eine Vielzahl von Nuancen, die häufig übersehen werden.
Eine besonders interessante und oft problematische Erscheinung ist das Phänomen der sogenannten Clopen Data – Daten, die gleichzeitig offen und geschlossen sind. Aber was genau bedeutet das? Und welche Probleme und Lösungsansätze verbergen sich hinter diesem Begriff? Zum besseren Verständnis lohnt sich ein kurzer Ausflug in die Welt der Topologie: Clopen bezeichnet in diesem Kontext eine Menge, die sowohl offen als auch geschlossen ist. Übertragen auf die Datenwelt sind Clopen Data also Datensätze, die zwar theoretisch verfügbar sind, in der Praxis aber kaum oder nur schwer genutzt werden können. Sie sind offen im Sinne der Zugänglichkeit, gleichzeitig aber geschlossen aufgrund von Nutzungsbeschränkungen, mangelnder Dokumentation oder anderen Einschränkungen. Ein besonders häufiger Fall von Clopen Data findet sich dort, wo Organisationen oder Institutionen lediglich das absolute Minimum leisten, indem sie Daten einfach irgendwo hochladen, ohne diese angemessen zu dokumentieren oder aufzubereiten.
Solche Datensätze sind oft unzureichend beschrieben, enthalten kaum bis keine Schlüsselwörter und sind mit unklaren oder restriktiven Lizenzbestimmungen versehen. Für Forscher und Entwickler wird es dadurch extrem schwer, die Daten sinnvoll einzusetzen – geschweige denn, die Ergebnisse reproduzierbar zu gestalten. Die Folge sind oft Frustration und ineffiziente Arbeitsprozesse. Ein weiteres Hindernis bei Clopen Data sind bürokratische Hürden, die den Zugang erheblich erschweren. Einige Daten werden zwar offiziell als verfügbar kommuniziert, sind aber nur nach aufwändigen Antragsverfahren zugänglich.
Studien belegen, dass in solchen Fällen lediglich ein Teil der Anfragen zum Erfolg führt. Sogar wenn der Zugang genehmigt wird, kann es immer noch zu Problemen kommen, da die bereitgestellten Daten womöglich wieder nur minimale Informationen ohne ausreichende Kontextualisierung bieten. Diese Schattenwelt der Datenverfügbarkeit schafft eine exklusive Gruppe von Nutzern, die sich im Dschungel der Zugangsbedingungen zurechtfinden können. Alle anderen bleiben außen vor – eine echte Barriere für Fortschritt und Innovation. Eine besonders tragische Ausprägung von Clopen Data betrifft gut gemeinte Datenpublikationen, die zwar sorgfältig mit Metadaten versehen wurden und sich in strukturierten Datenbanken befinden, aber schlecht auffindbar sind.
Hier sorgt die schlechte Benutzeroberfläche oder eine unzureichende Suchmaschinenfunktion dafür, dass eigentlich öffentlich zugängliche Informationen von potenziellen Nutzern kaum entdeckt werden können. Ein allzu wörtlicher oder unflexibler Suchalgorithmus lässt Nutzer schnell verzweifeln, etwa wenn Suchbegriffe nicht exakt mit dem gespeicherten Vokabular übereinstimmen. Diese Art von Clopen Data entsteht also nicht aus Nachlässigkeit bei der Datenerstellung, sondern aus mangelnder Berücksichtigung der Endanwenderperspektive bei der Datenbereitstellung. Die Folgen von Clopen Data sind vielfältig und weitreichend. Zum einen wird wertvolles Datenpotenzial nicht genutzt, was gerade in Bereichen wie dem maschinellen Lernen den Fortschritt hemmt.
Zum anderen verliert die Gesellschaft das Vertrauen in Datentransparenz und Offenheit, wenn der vermeintliche Zugang zu Daten im Alltag durch zahlreiche Hürden und Ineffizienzen eingeschränkt wird. Auch das Risiko von Fehlentwicklungen steigt, wenn Daten zwar vorhanden sind, aber der Nachvollziehbarkeit und Reproduzierbarkeit wissenschaftlicher Arbeiten dadurch Grenzen gesetzt sind. Doch wie lässt sich das Problem der Clopen Data überwinden? Ein wichtiger Schritt ist das Bewusstsein – in der Forschung ebenso wie bei den Datenproduzenten. Daten sollten nicht mehr als selbstverständlich gegeben gelten, sondern als wertvolle Ressource, die umsichtig und verantwortungsvoll behandelt werden muss. Das schließt eine umfassende Dokumentation ein, klare Lizenzbedingungen und eine benutzerfreundliche Bereitstellung mit ein.
Von Seiten der Wissenschaft ist es hilfreich, aktiv Feedback an Datenlieferanten zu geben. Eine Wertschätzung der aufwändigen Arbeit hinter der Datenaufbereitung kann neue Kooperationen fördern und die Qualität der Dateninfrastruktur langfristig verbessern. Hier zeigt sich auch, dass die Kultur, die in der Datengemeinschaft gelebt wird, entscheidend für den Umgang mit Daten ist. Eine stärkere Anerkennung von Datenproduktion und -kuratierung in Fachkonferenzen und Publikationen unterstreicht den wachsenden Stellenwert des Themas. Technisch gesehen sollte bei der Entwicklung von Datenportalen und Suchfunktionen mehr Augenmerk auf Nutzerfreundlichkeit und Auffindbarkeit gelegt werden.
Die Suchalgorithmen müssen flexibler und semantisch intelligenter werden, um auch variierende Suchanfragen sinnvoll bedienen zu können. Ebenso kann der Einsatz von Metadaten, Tags und standardisierten Formaten die Zugänglichkeit deutlich erhöhen. Letztlich geht es darum, eine Brücke zu schlagen zwischen reiner Datenverfügbarkeit und wirklicher Nutzbarkeit. Clopen Data kann nur dann in vollem Umfang ihr Potenzial entfalten, wenn sämtliche Stakeholder – Produzenten, Nutzer und Techniker – zusammenarbeiten. Vor allem in Zeiten zunehmender Digitalisierung und datengetriebener Innovationen ist es zentral, den Zugang zu Daten nicht nur formal zu gewährleisten, sondern praktisch erlebbar zu machen.
Betrachtet man die Entwicklung der Datenlandschaft heute, so ist ein Wandel spürbar. Initiativen zur Förderung von Open Data gewinnen an Bedeutung, viele Institutionen verbessern ihre Datenportale kontinuierlich. Es bleibt jedoch eine Herausforderung, Clopen Data zu entschärfen und für jedermann wirklich offene, gut dokumentierte und einfach zu nutzende Datensätze bereitzustellen. Dabei spielt nicht nur Technologie eine Rolle, sondern ebenso kulturelle und organisatorische Veränderungen. Ohne diese ganzheitliche Transformation droht der Fluch der Clopen Data weiterhin Innovationen auszubremsen und wissenschaftliche Erkenntnisse zu verkomplizieren.
Der Weg zu einer echten Datenoffenheit ist lang und erfordert eine Vielzahl kleiner Schritte – vom klaren Lizenztext über eine intuitive Suchfunktion bis hin zur inhaltlichen Sorgfalt bei der Datenerfassung. Besonders Forscher sollten aktiv vermitteln, welche Bedürfnisse sie haben und wie die Nutzung von Daten in der Praxis aussieht. Nur so kann ein Klima entstehen, in dem Datenerzeuger und -nutzer im Dialog stehen und gemeinsam daran arbeiten, dass Daten mehr sind als nur eine Datei, die irgendwo gespeichert ist. Daten sollten zu transparenten, zugänglichen und nützlichen Ressourcen werden, auf denen nachhaltige Innovationen aufbauen können. Zusammenfassend lässt sich sagen, dass Clopen Data ein vielschichtiges Problem darstellt, das im Kern die Diskrepanz zwischen formaler Offenheit und tatsächlicher Nutzbarkeit beschreibt.
Die Überwindung dieser Diskrepanz ist essenziell für den Fortschritt in datengetriebenen Disziplinen und für eine stärkere Vernetzung zwischen Datenerzeugern und Verbrauchern. Gleichzeitig zeigt sich, dass es bei der Datenbereitstellung nicht nur um technische Lösungen geht, sondern auch um den Aufbau von Vertrauen, Kommunikation und Wertschätzung – eine komplexe, aber lohnenswerte Aufgabe für die Zukunft der Datenwelt.