Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat in den letzten Jahren das Feld der Künstlichen Intelligenz revolutioniert. Allerdings steht der Einsatz dieser Modelle oft in der Kritik, insbesondere wenn es um die Herkunft der Trainingsdaten geht. Ein Großteil der bislang verwendeten Texte ist unlizenzierter oder urheberrechtlich geschützter Inhalt, was zu juristischen und ethischen Problemen führt. In diesem Kontext stellt The Common Pile v0.1 einen bedeutenden Fortschritt dar: Ein umfangreiches, 8 Terabyte großes Datenset, das ausschließlich aus gemeinfreien und offen lizenzierten Texten besteht.
Dieses Datenset ist speziell für das Training leistungsstarker Sprachmodelle konzipiert und bietet neue Perspektiven hinsichtlich Transparenz, Legalität und Qualität der KI-Entwicklung. Die Herausforderung, ein Dataset dieser Größe ausschließlich aus legal verfügbarem Material zu erstellen, ist enorm. Die Mehrheit der bisherigen Datenquellen stammt aus dem Internet, wo Inhalte häufig ohne klare Lizenzbedingungen verbreitet werden. The Common Pile v0.1 verfolgt einen anderen Ansatz, der die Nutzungsrechte strikt berücksichtigt und somit die Grundlage für eine verlässliche und ethisch verantwortbare KI-Forschung legt.
Das Projekt wurde von einem Team um Nikhil Kandpal, Brian Lester, Colin Raffel und weitere renommierte Wissenschaftler vorangetrieben, die mit ihrer Expertise dafür sorgten, dass die Datenqualität trotz der klaren Lizenzvorgaben nie vernachlässigt wurde. Das Spektrum der aufgearbeiteten Inhalte ist beeindruckend vielfältig. The Common Pile integriert Daten aus über 30 verschiedenen Quellen, die eine Bandbreite von wissenschaftlichen Artikeln, programmierbarem Quellcode, klassischen Büchern, Enzyklopädien, Lehrmaterialien bis hin zu Audio-Transkripten umfassen. Diese Vielfalt verleiht den darauf trainierten Modellen eine breite Wissensbasis und ermöglicht deren Einsatz in zahlreichen Anwendungsbereichen – von der wissenschaftlichen Informationsverarbeitung bis hin zur Bildungsunterstützung und kreativen Textgenerierung. Eine wichtige Besonderheit des Projekts ist die Validierung des Datensatzes durch praktische Anwendung.
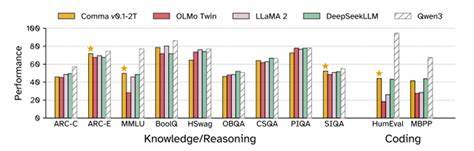
So wurden mit Comma v0.1-1T und Comma v0.1-2T zwei Sprachmodelle mit sieben Milliarden Parametern auf Trainingsdaten aus The Common Pile v0.1 trainiert. Diese Modelle, die auf jeweils 1 beziehungsweise 2 Billionen Tokens basieren, konnten in ihren Leistungen mit vergleichbaren Modellen konkurrieren, die auf unautorisierten oder lizenzierten Datensätzen trainiert wurden, wie etwa Llama 1 und Llama 2 mit sieben Milliarden Parametern.
Das zeigt anschaulich, dass offen zugängliche Daten nicht nur ethisch vorteilhaft, sondern auch technisch konkurrenzfähig sind. Der offene Charakter sowohl des Datasets als auch der zugehörigen Software und Trainingsmethoden sorgt für eine unerwartete Transparenz in einem ansonsten oft undurchsichtigen Feld. Interessierte Forscher, Entwickler und Unternehmen können nicht nur auf die 8 Terabyte umfassenden Texte zugreifen, sondern auch den Quellcode zur Erstellung des Datensets sowie die Trainingskonfigurationen und Modell-Checkpoint-Dateien herunterladen. Diese Offenheit ebnet den Weg für eine breite Kollaboration und weitere Verbesserungen, was der gesamten KI-Community zugutekommt. Von gesellschaftlicher Bedeutung ist zudem, dass The Common Pile Modelltrainingsverfahren fördert, die keine Urheberrechte verletzen und somit rechtliche Risiken minimieren.
Dies ist insbesondere relevant im derzeitigen Diskurs um KI-Training und geistiges Eigentum, der immer lauter und komplexer wird. Das Projekt bietet ein praktikables Gegenmodell zu bisherigen, oft intransparenten Datenpraktiken und zeigt auf, dass leistungsfähige KI-Systeme auch ohne fragwürdige Quellen realisiert werden können. Die technische Umsetzung der Datensammlung ist ebenso bemerkenswert wie die gesellschaftliche Wirksamkeit. Bei der Aggregation der 8 Terabyte an textuellem Material mussten Quellen sorgfältig geprüft und Metadaten konsistent aufbereitet werden. Zudem wurden redundante oder qualitativ unzureichende Dokumente herausgefiltert, um die Datenqualität hoch zu halten.
Durch gezieltes Kuratieren und maschinelles Validieren entstand ein robustes, vielseitiges Datenset, das speziell auf die Bedürfnisse moderner Sprachmodelle abgestimmt ist. Auf der Forschungsseite können neue Modelle auf The Common Pile trainiert und evaluiert werden, ohne auf ins Blaue hinein gesammelte Daten zurückgreifen zu müssen. Dies ist besonders für wissenschaftliche Reproduzierbarkeit und vergleichbare Benchmarks entscheidend. Auch ethische Aspekte wie Datenschutz, Persönlichkeitsrechte und Rechte der Inhaltsersteller lassen sich durch die zugrunde liegenden Lizenzen besser handhaben und ermöglichen somit einen verantwortungsvolleren Umgang mit KI. Der Einfluss von The Common Pile geht über den unmittelbaren Nutzen für die KI-Modellentwicklung hinaus.
Das Projekt setzt ein starkes Zeichen für offene Datenkultur und fördert den Zugang zu Wissen, der bislang häufig durch geschlossene Systeme begrenzt war. Gerade im Bereich Bildung und Forschung können die frei verfügbaren Texte eine große Rolle spielen, um neue Lern- und Lehrsysteme auszubauen. Zudem profitieren Unternehmen, die KI-Technologie verantwortungsvoll einsetzen wollen, von einer verlässlichen Datenbasis ohne rechtliche Fallstricke. Nicht zuletzt illustriert The Common Pile v0.1 einen Trend, der in den kommenden Jahren immer wichtiger wird: Die Balance zwischen Leistungsfähigkeit von KI und ethischer, rechtlicher Integrität.
Angesichts der zunehmenden gesellschaftlichen Relevanz solcher Systeme rücken Projekte, die Transparenz, Offenheit und Legalität in den Vordergrund stellen, in den Fokus. Damit leistet The Common Pile einen entscheidenden Beitrag zur Schaffung eines nachhaltigen KI-Ökosystems. Zusammenfassend lässt sich festhalten, dass The Common Pile v0.1 nicht nur ein massives, technisch ausgefeiltes Dataset ist, sondern auch eine Blaupause für künftige Entwicklungen im Bereich KI-Daten darstellt. Es vereint rechtliche Sicherheit, hohe Datenqualität und breite Anwendbarkeit und zeigt auf, wie die Zukunft der Sprachmodell-Entwicklung aussehen kann – offen, transparent und innovativ.
Forschende, Entwickler und Unternehmen, die nachhaltige und leistungsfähige Sprachmodelle schaffen möchten, sind mit The Common Pile v0.1 bestens gerüstet, um die kommenden Herausforderungen zu meistern und neue Potenziale zu erschließen.