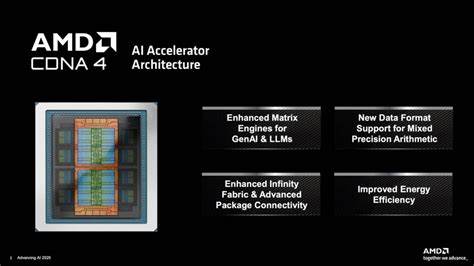
AMD hat mit der Ankündigung der MI350X und MI355X erfreuliche Neuigkeiten für alle Anwender im Bereich der Künstlichen Intelligenz (KI) veröffentlicht. Die neuen GPUs basieren auf der fortschrittlichen CDNA 4 Architektur und versprechen einen erheblichen Leistungssprung sowie verbesserte Effizienz bei AI-Workloads. Diese Entwicklungen markieren nicht nur einen technischen Meilenstein für AMD, sondern auch einen wichtigen Schritt im intensiven Wettbewerb mit Nvidia, dem bislang führenden Anbieter im KI-Hardwaremarkt. Die neue GPU-Generation adressiert sowohl Forschungseinrichtungen als auch Unternehmen, die hohe Rechenleistungen für maschinelles Lernen, neuronale Netze und komplexe Datenanalysen benötigen. Die Kombination aus innovativer Technologie und optimiertem Leistungsmanagement verspricht dabei signifikante Vorteile in puncto Performance pro Dollar und Gesamtbetriebskosten (TCO).
Die MI350X und MI355X GPUs zeichnen sich durch verschiedene technische Highlights aus, die sie von der Vorgängergeneration, insbesondere dem MI300X, deutlich abheben. AMD weist einen 3x Leistungsschub im Vergleich zu den älteren Modellen aus und betont in Benchmark-Vergleichen eine Überlegenheit gegenüber Nvidias GPUs in bestimmten Inferenz- und Trainingstasks. Besonders bei Inferenzberechnungen wird ein bis zu 1,3-facher Vorsprung erzielt, was die neuen Instinct-Modelle insbesondere für Anwendungen mit hoher Anfragefrequenz sehr attraktiv macht. In realen AI-Workloads, die unter anderem Modelltraining und Chatbot-Interaktionen umfassen, sollen die GPUs zudem mit 4-facher Rechenleistung glänzen und die Effizienz maßgeblich steigern. Die zugrunde liegende CDNA 4 Architektur bildet das Fundament für diese erheblichen Fortschritte.
Im Vergleich zum Vorgänger, der auf CDNA 3 basiert, wurde ein fortschrittlicher Fertigungsprozess bei TSMC (N3P) verwendet, der nicht nur eine höhere Transistordichte, sondern auch verbesserte Energieeffizienz bietet. Mit 185 Milliarden Transistoren übertrifft die neue Generation den Vorgänger um etwa 21 Prozent, wodurch mehr Recheneinheiten und Speicherkapazitäten integriert werden können. Die parallele Weiterentwicklung der sogenannten Infinity Fabric, AMDs Datenverbindungstechnologie zwischen den Chipmodulen, erlaubt inzwischen eine Bandbreite von bis zu 5,5 Terabyte pro Sekunde, was für hohe Durchsatzraten bei der Datenkommunikation zwischen den GPUs sorgt. Der Speicher spielt eine ebenfalls zentrale Rolle bei der Leistungssteigerung. Beide GPUs sind mit bis zu 288 GB HBM3E ausgestattet, einem leistungsstarken, energieeffizienten High-Bandwidth-Memory, der Bandbreiten bis zu 8 Terabyte pro Sekunde unterstützt.
Im Vergleich zum Vorgänger und mancher Konkurrenten ermöglicht diese Kombination aus großer Kapazität und schnellster Datenzufuhr eine außergewöhnlich schnelle Verarbeitung großer Datenmengen, wie sie für Trainingsdaten neuronaler Netzwerke üblich sind. Besonders bemerkenswert ist die Unterstützung neuer Datentypen wie FP4 und FP6, die speziell für KI-Anwendungen optimiert sind und präzise, aber dennoch ressourcenschonend rechnen. Die Differenzierung zwischen den beiden Modellen MI350X und MI355X liegt vor allem im Kühlkonzept und der Leistungsaufnahme. Der MI350X ist primär für luftgekühlte Systeme ausgelegt und bietet somit eine effizientere Nutzung in Standard-Serverumgebungen mit niedrigerem Energieverbrauch. Die gezielte Optimierung für diesen Anwendungsfall sorgt für geringere Gesamtbetriebskosten bei gleichzeitig hoher Leistung.
Dem gegenüber steht der MI355X, der mit einem deutlich höheren Total Board Power (TBP) von bis zu 1.400 Watt spezifiziert ist und für flüssigkeitsgekühlte Racks und High-End-Server konzipiert wurde. Diese Variante setzt vor allem auf maximale Rechenperformance ohne Kompromisse bei der thermischen Auslegung. Dank der Flüssigkeitskühlung lassen sich so viele GPUs auf engem Raum betreiben, was eine optimale Raumausnutzung in Rechenzentren ermöglicht. Im Rahmen der Infrastruktur bekräftigt AMD seine klare Fokussierung auf Rack-Scale-Systeme.
Die Möglichkeit, bis zu acht dieser GPU-Module miteinander zu koppeln und über die Infinity Fabric mit einer Gesamtbandbreite von mehr als einem Terabyte pro Sekunde zu verbinden, eröffnet enorme Skalierungspotenziale. Die Systeme werden von AMDs fünfter EPYC Prozessoren-Generation 'Turin' begleitet, die speziell für den Einsatz in datenzentrierten, KI-intensiven Workloads ausgelegt sind. Die Kombination aus CPUs und GPUs sorgt dabei für hohe Parallelisierbarkeit und flexible Ressourcenzuweisung, wodurch komplexe KI-Modelle effizient trainiert und ausgewertet werden können. Im direkten Vergleich mit Nvidias aktuellen Lösungen, wie den GB200 und B200 Modellen, positioniert sich AMD mit den neuen GPUs konkurrenzfähig bis sogar vorn. Besonders bei der FP64-Leistung, die für wissenschaftliche Berechnungen und Simulationen relevant bleibt, sieht sich AMD deutlich im Vorteil.
Nvidia tendiert hingegen dazu, seine Hardware eher für niedrigere Präzisionsstufen im KI-Bereich zu optimieren. Bei diesen Formaten wie FP16, FP8 und speziell dem neu unterstützten FP6 ist AMD jedoch nah an der Konkurrenz dran oder kann diese marginal übertreffen. Interessant ist zudem die Tatsache, dass AMD den FP6-Datentyp mit derselben Geschwindigkeit wie FP4 verarbeiten kann, was in der Branche als Innovation für bestimmte KI-Arithmetikprozesse gilt. Leistungsoptimierung bleibt allerdings auch mit einem deutlich höheren Energiebedarf verbunden. Im Vergleich zum Vorgänger MI300X mit 750 Watt steigt der Verbrauch des MI355X auf 1.
400 Watt an. AMD rechtfertigt diesen Anstieg durch die extreme Dichte und die daraus resultierende Möglichkeit, mehr Rechenleistung pro Rack-Einheit zu bündeln. Die Effizienz berechnet sich damit nicht nur auf Hardwareebene, sondern auf das Verhältnis von Leistung zu Kosten (TCO) im Gesamtsystem, was für Rechenzentrumsbetreiber ein entscheidendes Kriterium ist. Eine sorgfältige Abwägung zwischen Energieverbrauch, Kühlung und Performance ermöglicht es Unternehmen, basierend auf ihrem individuellen Bedarf die richtige GPU-Variante zu wählen. Die MI350X und MI355X erscheinen im standardisierten OAM-Formfaktor, der volle Kompatibilität mit gängigen Servern nach dem Open Compute Project (OCP) gewährleistet.
Dies erleichtert und beschleunigt die Integration in bestehende Systeme und reduziert die Time-to-Market für neue KI-Projekte. AMD verfolgt mit dieser Strategie eine konsequente Skalierbarkeit und Modularität, um sowohl kleinere Forschungseinrichtungen als auch große Unternehmen mit maßgeschneiderten Lösungen zu bedienen. Zusätzlich zur Hardware betont AMD die umfassende Unterstützung für moderne Netzwerktechnologien. Die GPUs sind kompatibel zu fortschrittlichen Netzwerkkarten des Pollara-Ultra Ethernet Consortium (UEC) und nutzen mit Ultra Accelerator Link (UAL) eine schnelle, latenzarme Datenverbindung zwischen den Knoten. Für intensive skalenübergreifende Workloads bietet AMD sowohl Direct Liquid Cooling (DLC) als auch Air-Cooled (AC) Rack-Lösungen an, welche je nach Anforderungen und Rechenzentrumskonzept verschiedene Leistungs- und Kapazitätsstufen adressieren.
Die Benchmarkergebnisse von AMD belegen eindrucksvoll, wie sich die MI350X und MI355X in der Praxis schlagen. Insbesondere die Fähigkeit, komplexe Large Language Models wie Llama 3.1 auf höchstem Niveau zu betreiben, macht die GPUs äußerst attraktiv für moderne KI-Anwendungen. Werte wie ein bis zu 4,2-facher Leistungsvorsprung gegenüber der Vorgängergeneration in AI-Agent- und Chatbot-Szenarien heben die Effektivität der Hardware hervor. Auch im Content-Generierungs- und Analysebereich zeigen sich deutliche Verbesserungen, was den Einsatz in kreativen wie analytischen Bereichen unterstützt.
Für viele Anwender ist zudem die Tatsache relevant, dass AMD auf eine APU-Version mit integrierten CPU-Kernen verzichtet und stattdessen reine GPU-Chips präsentiert. Diese Entscheidung erlaubt eine klar fokussierte Optimierung der Grafik- und AI-Leistung und erleichtert die Integration in bestehende Server-Architekturen, die CPU und GPU getrennt skalieren. Zusammenfassend markieren die neuen MI350X und MI355X GPUs einen bedeutenden Fortschritt bei AMD im Segment der KI-Beschleuniger. Mit fortschrittlicher Fertigung, innovativer Architektur und starken Leistungsdaten nähert sich AMD zunehmend an die bisherigen Marktführer an und schafft gleichzeitig neue Optionen für Rechenzentren, die auf maximale Effizienz und Skalierbarkeit setzen. Die Kombination aus speicherstarken HBM3E Modulen, hohen Datenbandbreiten und unterstützten KI-spezifischen Datenformaten stellt eine ideale Plattform für anspruchsvolle KI-Workloads der nächsten Generation dar.
Die Zukunft der KI-Beschleuniger zeigt sich bei AMD also klar in der Weiterentwicklung modularer, skalierbarer und energieeffizienter Systeme. Unternehmen und Institutionen, die auf innovative und leistungsstarke Lösungen setzen möchten, finden in den MI350X und MI355X eine überzeugende Alternative am Markt, die mit einem guten Preis-Leistungs-Verhältnis und einer starken technischen Basis überzeugt. Während sich die Branche weiterhin rasant entwickelt, sind die neuen GPUs ein klares Signal, dass AMD im Wettlauf um die bevorzugte KI-Hardware eine wichtige Rolle einnimmt und die Entwicklung aktiv mitgestaltet.