Mit der Veröffentlichung von ChatGPT Images hat OpenAI ein bahnbrechendes Feature ins Leben gerufen, das die Art und Weise, wie Nutzer Bilder durch künstliche Intelligenz erstellen, grundlegend verändert. Innerhalb der ersten Woche nach dem Launch meldeten sich unglaubliche 100 Millionen neue Nutzer an und generierten rund 700 Millionen Bilder – Zahlen, die nicht nur die Erwartungen deutlich übertrafen, sondern auch neue Maßstäbe im Bereich der bildgenerierenden KI setzten. Doch wie gelang es OpenAI, dieses enorme Wachstum zu bewältigen und das System trotz extremer Last stabil und zuverlässig zu halten? Die Antwort liegt in der Kombination aus innovativer Technik, agiler Entwicklung und einer flexiblen Infrastruktur, die bis an ihre Grenzen getestet wurde. Der Start von ChatGPT Images erfolgte am 25. März 2025, nur wenige Monate nach einer Reihe weiterer bedeutender Produktupdates wie ChatGPT 4.
5, der Erweiterung für macOS Codebearbeitung oder Voice Agents mit neuen Audiomodellen. Der Hauptfokus lag zunächst auf zahlenden Nutzern, bei denen das Feature zunächst exklusiv verfügbar gemacht wurde. Allerdings wurde schnell deutlich, dass die Nachfrage weit über die Prognosen hinausging. Dies führte zu einer Verzögerung des Free-User-Rollouts, der erst zwei Tage später gestartet wurde, um die kontinuierlich hohen Anfragen besser zu bewältigen. Besonders beeindruckend war der virale Anstieg in Indien, wo bereits kurz nach dem Release zahlreicher Prominenter und selbst der indische Premierminister Narendra Modi Bilder in berühmtem Ghibli-Stil teilten.
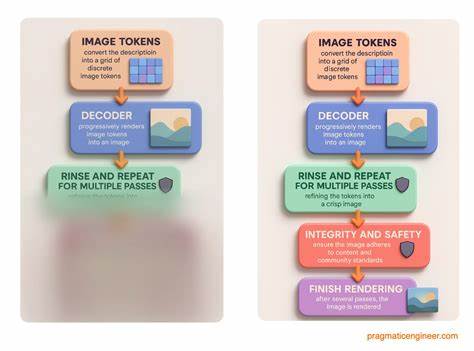
Diese Popularität führte zu einem sprunghaften Anstieg der Nutzerzahlen, mit Spitzenwerten von bis zu einer Million Neuanmeldungen in nur einer Stunde. Das Feature entwickelte sich zu einem kulturellen Phänomen und erweiterte damit die Reichweite von ChatGPT Images weit über das initial erwartete Maß hinaus. Die technische Grundlage für die Bildgenerierung ist ein komplexer, aber eleganter Prozess, der von sogenannten Image Tokens ausgeht. Nutzer geben eine Beschreibung ein, die in ein Raster diskreter Tokens übersetzt wird. Diese Tokens kodieren Bildinhalte nativ und dienen als Input für einen Decoder, der das Bild schrittweise und in mehreren Durchgängen renderiert.
Zu Beginn ist das Bild unscharf, wird jedoch mit jeder weiteren Phase klarer und detailreicher. Parallel dazu arbeitet ein integrierter Schutzmechanismus, der dafür sorgt, dass nur Inhalte generiert werden, die den Community-Standards entsprechen. Bei Abweichungen wird der Renderprozess sofort abgebrochen, um Missbrauch und problematische Inhalte zu verhindern. Der technologische Stack hinter ChatGPT Images ist bemerkenswert pragmatisch und besteht hauptsächlich aus Python, FastAPI für schnelle API-Entwicklung, C zur Optimierung kritischer Komponenten sowie Temporal, einem Workflow-System, das asynchrone Abläufe zuverlässig managt. Die Verwendung von Temporal war entscheidend für die Verarbeitung komplexer und langdauernder Prozesse, wie sie bei der Bildgenerierung üblich sind.
Diese Architektur ermöglichte es den Entwicklern, auch unter enormer Last flexible und skalierbare Systeme aufzubauen, die bei Bedarf faktisch in Echtzeit angepasst werden konnten. Die größte technische Herausforderung ergab sich aus der anfänglich synchronen Entwicklung des Features. Bildgenerierung erfolgte linear; war der Prozess unterbrochen, konnte er nicht wiederaufgenommen werden und blockierte gleichzeitig wichtige Ressourcen wie GPU-Leistung und Arbeitsspeicher. Mit dem gigantischen Ansturm sah sich das Team gezwungen, die Architektur zu überdenken und innerhalb weniger Tage auf ein asynchrones System umzusteigen. Diese Umstellung erlaubte es, Lastspitzen abzufedern, indem Anfragen zunächst in einer Warteschlange gesammelt und später abgearbeitet werden, sobald Ressourcen verfügbar sind.
Obwohl dies zulasten der Latenz für einige Nutzer ging, gewährleistete es vor allem Verfügbarkeit und Stabilität des Dienstes – ein bewusster Kompromiss zugunsten einer durchgängig funktionierenden Plattform. Die immense Nutzerzahl wirkte sich nicht nur auf die Bildgenerierungskomponenten aus, sondern belastete weite Teile der OpenAI-Infrastruktur. Datenbanken, Dateisysteme und Authentifizierungsdienste gerieten an ihre Grenzen. Hier zeigte sich der Wert der bereits vorhandenen Systemisolierungen, die einen totalen Ausfall wichtiger Dienste verhinderten. Dennoch forcierte OpenAI die strikte Trennung von ChatGPT- und OpenAI-API-Infrastrukturen, um gegenseitige Beeinträchtigungen weiter zu minimieren.
Die schnelle Skalierung der Kapazitäten erforderte neben architektonischen Maßnahmen auch handfeste Performance-Optimierungen. Entwicklerteams analysierten und reduzierten ineffiziente Datenbankabfragen, beseitigten unnötigen Codeballast und verbesserten die Ressourcennutzung. Parallel dazu wurden neue Kapazitäten bei Datenbanken und Filesystemen in rekordverdächtiger Geschwindigkeit erschlossen. Diese Doppelstrategie aus kurzfristiger Optimierung und langfristiger Infrastruktur-Erweiterung war der Schlüssel, um mit der unvorhergesehenen Nachfrage Schritt zu halten. Ein weiterer spannender Aspekt liegt in der Flexibilität und Agilität des Engineering-Teams bei OpenAI.
Rollen von Entwicklern, Forschern, Produktmanagern und Designern sind bei OpenAI bewusst überlappend und stark vernetzt. Dieses Modell fördert schnelles Shipping und unkomplizierte Kommunikation, was gerade bei solch einem disruptiven Feature enorm hilft. Die Verwendung des DRI-Rollenprinzips (Directly Responsible Individual) stellt sicher, dass klare Verantwortlichkeiten bei der Vielzahl paralleler Aufgaben jederzeit bestehen und Entscheidungen zügig getroffen werden können. Inhaltlich ebnet ChatGPT Images den Weg für vielfältige kreative Anwendungen. Nutzer können Bilder nicht nur generieren, sondern auch anhand neuer Eingaben weiterentwickeln und anpassen.
Dieses „Tweaking“ ermöglicht Iterationen bestehender Bilder und erweitert das kreative Potenzial enorm. Allerdings erfordert jede solche Anpassung erhöhte Rechenressourcen, was wiederum zu zusätzlichen Belastungen der Infrastruktur führt. Mit dem Wandel von einer GPU-dominierten Leistungsbegrenzung hin zu einem ganzheitlichen „alles ist ein Engpass“-Szenario stehen OpenAI und ähnliche Unternehmen vor neuen Herausforderungen. Nicht mehr nur spezialisierte Hardware diktiert die Leistungsgrenzen, sondern auch Speicher, Netzwerk, Datenbanken und Systeme für Benutzeridentifikation und -verwaltung. Dies unterstreicht die Komplexität moderner cloudbasierter KI-Dienste und die Notwendigkeit, Gesamtarchitekturen stets ganzheitlich im Blick zu behalten.
Die Nutzerprioritäten sind bei OpenAI klar: Verfügbarkeit hat Vorrang vor Latenz. Im Falle unerwarteter Lastspitzen wird bewusst in Kauf genommen, dass Bilder etwas länger auf sich warten lassen. Dieses Prinzip sorgt dafür, dass der Dienst jederzeit erreichbar bleibt – eine wichtige Grundlage für die Zufriedenheit der schnell wachsenden Nutzerbasis. Zusammenfassend zeigt der Start und die Skalierung von ChatGPT Images eindrucksvoll, wie durch technische Exzellenz, agile Teamarbeit und kontinuierliche Anpassung an reale Belastungsszenarien ein revolutionäres Produkt realisiert werden kann. Die Herausforderung, eine plötzliche Vervielfachung der Nutzerzahlen zu bewältigen und gleichzeitig höchste Qualitäts- und Zuverlässigkeitsstandards einzuhalten, wurde erfolgreich gemeistert.
Damit definiert OpenAI erneut die Grenzen dessen, was mit künstlicher Intelligenz möglich ist – und liefert gleichzeitig wertvolle Erkenntnisse für die Zukunft der skalierbaren, KI-gestützten Dienste.