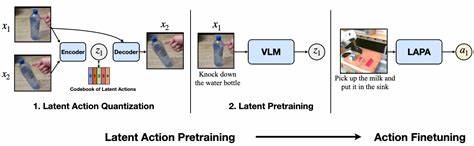
Visuelle Sprachassistenten (VLA) sind eine innovative Technologie, die zunehmend in den Bereichen künstliche Intelligenz und Mensch-Maschine-Interaktion an Bedeutung gewinnt. Diese Systeme ermöglichen es Nutzern, mithilfe von Sprache und visuellen Eingaben Aufgaben zu erledigen, Informationen abzurufen oder Geräte zu steuern. Ein zentrales Element in der Entwicklung solcher Assistenten ist das latente Aktionsmodell, das Handlungen in einer versteckten Repräsentation kodiert und so komplexe Interaktionen ermöglicht. Innerhalb dieses Rahmens spielen sogenannte Distraktoren eine wichtige Rolle, die die Leistung und Genauigkeit der Systeme sowohl positiv als auch negativ beeinflussen können. Das Verständnis und die Berücksichtigung von Distraktoren ist entscheidend, um die Effizienz und Zuverlässigkeit von VLAs weiter zu steigern.
Distraktoren sind in der Praxis jene Elemente innerhalb einer visuellen Szene oder einer Benutzeranfrage, die die Aufmerksamkeit des Systems vom relevanten Ziel ablenken können. Sie können in Form von irrelevanten Objekten, ähnlichen Elementen oder Störgeräuschen auftreten. In einem latenten Aktionsmodell wirken sie sich auf die interne Entscheidungsfindung aus, weil das Modell Schwierigkeiten haben kann, zwischen wichtigen und unwichtigen Informationen zu unterscheiden. Dies kann zu Fehlinterpretationen führen und letztlich die korrekte Ausführung einer Aktion verhindern. Für Entwickler von VLAs ist es daher von zentraler Bedeutung, Strategien zur Handhabung von Distraktoren zu integrieren, um die Robustheit der Systeme zu erhöhen.
Das latente Aktionsmodell liefert eine flexible und effiziente Möglichkeit, komplexe Handlungsfolgen zu repräsentieren. Im Kern kodiert es Aktionen nicht als einfache, explizit vorgegebene Sequenzen, sondern als latente Variablen, die unterschiedliche mögliche Handlungen in einer abstrakten Repräsentation zusammenfassen. Dies erlaubt dem Modell, auf unvorhergesehene Situationen zu reagieren und Handlungsempfehlungen auch bei vagen oder unvollständigen Informationen abzuleiten. Allerdings kann gerade diese Flexibilität zu einer Schwäche werden, wenn Distraktoren die interne Repräsentation verzerren. Das Modell könnte beispielsweise eine visuelle Szene falsch interpretieren, weil ein Distraktor als relevanter Faktor gedeutet wird.
Ein weiterer Aspekt ist, dass Distraktoren die Trainingsphase der Modelle beeinflussen. In unzureichend annotierten Daten oder Datensätzen mit hohem Rauschanteil können Distraktoren die Qualität der latenten Repräsentation verschlechtern, da das Modell zu stark auf irrelevante Merkmale eingeht. Die Auswahl geeigneter Trainingsdatensätze, die gezielt Distraktoren enthalten, kann dagegen helfen, die Resilienz des Modells zu erhöhen. Das Training mit schwierigen Szenarien sorgt dafür, dass der VLA lernt, relevante von irrelevanten Informationen zu unterscheiden und folgerichtig die Handlung zu planen. Methodisch stehen verschiedene Ansätze zur Verfügung, um den Einfluss von Distraktoren zu reduzieren.
Ein bewährtes Mittel ist die Integration von Aufmerksamkeitsmechanismen, die dem Modell helfen, relevante Bildregionen oder Dialogbestandteile zu fokussieren. Diese Mechanismen können auf neuronalen Netzen basieren und zahlen auf das latente Aktionsmodell ein, indem sie eine Gewichtung der eingehenden Informationen ermöglichen. Das Resultat ist, dass weniger störende Informationen in die latente Repräsentation einfließen und die Handlungsauswahl auf fundierteren Daten basiert. Darüber hinaus sind multimodale Lernansätze entscheidend. Durch die Kombination von visuellen, sprachlichen und anderen sensorischen Eingaben kann der VLA redundante und widersprüchliche Informationen besser ausfiltern.
Beispielsweise hilft die Verknüpfung von visuellen Objekten mit gesprochener Beschreibung dabei, Distraktoren abzugrenzen. Wenn eine visuelle Referenz zu einem Objekt klar in der Sprache verankert ist, fällt es dem Modell leichter, irrelevante Elemente zu erkennen und auszublenden. Im praktischen Einsatz sind VLAs mit latentem Aktionsmodell besonders in komplexen und dynamischen Umgebungen gefordert, etwa im Smart-Home-Bereich, in Fahrzeugen oder bei Assistenzsystemen für Menschen mit Einschränkungen. Dort führt die Vielfalt an sichtbaren Objekten schnell zu einer Vielzahl an möglichen Distraktoren. Eine herausfordernde Aufgabe ist die Echtzeitverarbeitung von Sprach- und Bildinformationen, bei der das Modell schnell zwischen Zielobjekt und Ablenkungen unterscheiden muss.
Hier zeigt sich, dass Optimierungen im Hinblick auf Distraktoren entscheidend für die Akzeptanz und Nutzbarkeit des Systems sind. Die Zukunftsforschung beschäftigt sich daher intensiv damit, wie die Sensibilität der Modelle für Distraktoren reduziert werden kann, ohne dabei wichtige Kontextinformationen zu verlieren. Entwicklungen in Explainable AI könnten dazu beitragen, besser zu verstehen, welche Bestandteile einer Szene vom latenten Aktionsmodell berücksichtigt werden. Durch verbesserte Interpretierbarkeit könnten Entwickler zielgerichteter Anpassungen vornehmen, um die Auswirkungen von Distraktoren zu minimieren. Zusammenfassend ist die Berücksichtigung von Distraktoren bei VLAs mit latentem Aktionsmodell eine komplexe, aber essentielle Herausforderung.
Sie beeinflusst maßgeblich die Genauigkeit, Robustheit und Benutzerfreundlichkeit solcher Systeme. Nur durch die Kombination aus datengetriebenem Training, fortschrittlichen Aufmerksamkeitsmechanismen, multimodalem Lernen und interpretierbaren Modellen lässt sich die nächste Generation von visuellen Sprachassistenten entwickeln, die zuverlässig und effizient in unterschiedlichsten Anwendungsszenarien agieren können.