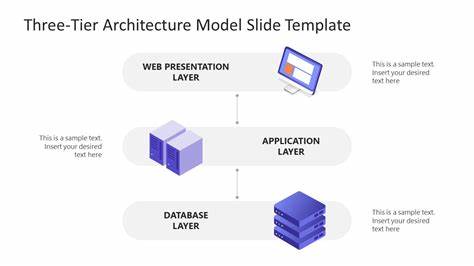
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat die Anforderungen an Infrastruktur und Speicherlösungen erheblich gesteigert. Diese Modelle beinhalten oft Dateien im Bereich von mehreren Dutzend bis hin zu hunderten Gigabyte, die zwar effizient verarbeitet, aber auch äußerst schnell geladen werden müssen. Gerade bei verteiltem Betrieb in Cloud-Umgebungen stellt der Speicherzugriff häufig einen Engpass dar, der die gesamte Effizienz der Inferenz behindern kann. Eine herkömmliche Verwendung eines einzigen Speichertyps – etwa reine lokale Datenträger oder rein cloudbasierte Objektspeicher – genügt angesichts der Durchsatz- und Latenzanforderungen oftmals nicht mehr. Um diesen Herausforderungen zu begegnen, hat sich eine dreistufige Speicherarchitektur etabliert, die lokale Hochgeschwindigkeitsspeicher mit einem intelligenten Cache-System und der Skalierbarkeit von Cloud-Objektspeichern kombiniert.
Diese Struktur ermöglicht es, Modellladezeiten drastisch zu verkürzen, gleichzeitig Kosten zu senken und die Auslastung der teuren GPU-Ressourcen zu erhöhen.Der erste Speicherbereich dieser Architektur ist die sogenannte Hot-Tier. Hierbei handelt es sich um lokale NVMe-SSDs, die direkt an die GPU-Server angeschlossen sind. NVMe-Laufwerke bieten eine außergewöhnlich hohe sequenzielle Leseleistung im Bereich von mehreren Gigabyte pro Sekunde bei extrem niedriger Latenz. Die Integration als POSIX-Dateisystem ermöglicht es, dass Anwendungen wie TensorFlow, PyTorch oder Hugging Face nahtlos auf die Daten zugreifen können, ohne dass umfangreiche Anpassungen am Code notwendig sind.
Das bedeutet, dass Modelle direkt vom NVMe-Laufwerk gemappt oder gelesen werden können, was insbesondere bei Formaten wie Safetensors, die auf mmap und zufälligen Zugriff angewiesen sind, erhebliche Geschwindigkeitsvorteile bringt. Ein typisches Szenario zeigt, dass ein 512 MB großes Modell in etwa 0,2 Sekunden vollständig vom NVMe-Cache geladen werden kann. Damit erhöht sich die Gesamtgeschwindigkeit gegenüber einem reinen Cloud-Download um ein Vielfaches. Das Hot-Tier dient somit als zentraler Cache, in dem die am häufigsten gebrauchten Modelle und Daten lokal vorgehalten werden. Bereits beim Start eines Dienstes ist es üblich, die Modelle ganz oder teilweise durch sequentielle Vorkonditionierung in den OS-Seiten-Cache zu laden, um das gesamte System optimal zu beschleunigen.
Die zweite Ebene, Warm-Tier genannt, erweitert diesen Ansatz auf Cluster-Ebene. Anstatt dass jeder Server seine Modelle nur lokal lädt oder direkt von der Cloud bezieht, ermöglichen intra-cluster Dateifreigabesysteme oder Peer-to-Peer-Dateiserver den Austausch von bereits lokal zwischengespeicherten Modellen zwischen den Rechnern. Dadurch kann ein Server, der ein Modell bereits vollständig oder teilweise im NVMe-Cache hat, anderen Servern im Netzwerk die Daten mit hoher Bandbreite zur Verfügung stellen. Typischerweise werden hierfür Netzwerkgeschwindigkeiten im Bereich von 10 bis 25 Gbit/s vorausgesetzt, was Übertragungsraten von etwa ein bis zwei Gigabyte pro Sekunde bedeutet. Damit können mehrere Instanzen eines Modells gleichzeitig in einem Cluster ausgeführt werden, ohne dass jedes Mal alle Server das volle Modell eigenständig aus der Cloud laden müssen.
Dieser Ansatz ist vergleichbar mit BitTorrent-artigen Verteilungssystemen und minimiert redundante Zugriffe auf die Cloud, wodurch Bandbreitenverbrauch und Kosten spürbar reduziert werden. Außerdem verhindert das Warm-Tier so typische Flaschenhälse bei der Modellverteilung innerhalb großer GPU-Cluster. Die Architektur der Warm-Tier-Implementierungen variiert je nach verwendetem Distributed Filesystem oder eigenständiger P2P-Lösung, die teilweise automatisiert Cache-Status überwachen und die Verteilung steuern. Außerdem ermöglicht dieser Zwischenspeicher eine bessere Auslastung des Netzwerkes und trägt zur Stabilität der gesamten Struktur bei, indem er Lastspitzen beim Modell-Download aus der Cloud vermeidet.Das dritte und letzte Glied der Speicherarchitektur bildet die Cold-Tier, welche typischerweise aus Cloud-Objektspeichern wie Amazon S3, Google Cloud Storage oder Azure Blob Storage besteht.
Diese Speicher sind auf maximale Skalierbarkeit, Kosteneffizienz und Haltbarkeit ausgelegt, jedoch mit höheren Latenzen und geringeren Durchsatzraten je Einzelzugriff. Hier liegen alle persistente Kopien aller Modelle, Checkpoints und Datensätze. Da die Latenz hier häufig im Bereich von mehreren zehn bis hundert Millisekunden liegt und der Durchsatz je Verbindung oft wenige hundert Megabyte pro Sekunde beträgt, wird die Cold-Tier fast ausschließlich für seltene oder initiale Zugriffe genutzt. Wenn etwa ein Modell zum ersten Mal benötigt wird, holt ein Knoten es aus der Cold-Tier herunter und speichert es anschließend im Warm- oder Hot-Tier zwischen. Darüber hinaus fungiert die Cold-Tier als zuverlässige Quelle der Wahrheit und Archivspeicher, bei dem alte Modelle ohne Kosten für teure Hochgeschwindigkeitsspeicher vorgehalten werden.
Eine effektive Nutzung erfordert Multithreading und parallele Anfragen, um die maximale Bandbreite zu erreichen. Dabei sollten möglichst viele gleichzeitige Downloads mit Range Requests eingesetzt werden, um den Transfer zu optimieren. Aufgrund von Gebühren für Speicher- und Netzwerkzugriffe ist die Minimierung von direkten Cold-Tier-Zugriffen auch ein essentieller Faktor zur Kosteneinsparung.In der Praxis ist der Betrieb dieser dreistufigen Speicherarchitektur mit einigen bewährten Verfahren verbunden, die die Effizienz weiter steigern. So ist es sinnvoll, Modelle gezielt vorab zu laden und Caches systematisch aufzuheizen.
Dies bedeutet, dass man etwa ein Modell zunächst auf einem Server aus der Cold-Tier holt und es danach über das Warm-Tier an die anderen Knoten verteilt, was das gleichzeitige Laden durch mehrere Instanzen drastisch beschleunigt. Für alle Ebenen sollte ein leistungsfähiges, mindestens 10 Gbit/s schnelles Netz verwendet werden, idealerweise sogar 25 oder 40 Gbit/s, um eine Verzögerung durch Netzwerkengpässe zu vermeiden. Zudem profitieren moderne LLM-Frameworks und Speicherlösungen von parallelen und asynchronen Ladeprozessen, die mehrere Leseoperationen gleichzeitig ausführen, um die volle Bandbreite der NVMe-SSDs und Netzwerkschnittstellen auszunutzen. Das Monitoring der Cache-Hit-Raten ist ein weiteres wichtiges Instrument, um sicherzustellen, dass so oft wie möglich das Hot- oder Warm-Tier bedient wird und Nicht-Treffer aus der Cold-Tier minimiert bleiben. In umfangreichen Umgebungen hilft eine automatische Verwaltung der Cache-Eviction mit Algorithmen wie LRU oder LFU, um den begrenzten Speicherplatz auf den lokalen NVMe-Disks effektiv zu nutzen und Modelle bei Bedarf auszutauschen oder zu löschen.
Zusammenfassend hat sich die dreistufige Speicherarchitektur als state-of-the-art für die Inferenz großer Sprachmodelle in der Cloud etabliert. Die Kombination aus extrem schnellen lokalen NVMe-SSDs, einer intelligenten, clusterweiten Zwischenspeicherung und der elastischen Skalierbarkeit von Cloud-Objekt-Speichern sorgt für eine signifikante Verkürzung der Ladezeiten und eine Entlastung kostspieliger Netzressourcen. Auf diese Weise wird sichergestellt, dass GPUs zur Inferenz bereitstehen und nicht durch IO-Latenzen gebremst werden. Für Unternehmen und Entwickler, die auf die effiziente Bereitstellung großer Modelle angewiesen sind, ist die Implementierung einer solchen mehrstufigen Speicherlösung daher ein entscheidender Schritt zum Erfolg. Die Auswahl zwischen Managed Services und Open-Source-Lösungen bietet dabei Flexibilität hinsichtlich Aufwand, Kontrolle und Kosten, wobei die Grundprinzipien und Patterns gleich bleiben.
Gerade angesichts der wachsenden Bedeutung von Anwendungen wie Chatbots, automatischen Übersetzungen und KI-gestützten Textanalysen wird die Bedeutung leistungsfähiger Speicherarchitekturen in Zukunft weiter zunehmen. Wer frühzeitig auf eine Drei-Ebenen-Strategie setzt, profitiert langfristig von besserer Performance, niedrigeren Betriebskosten und einer skalierbaren Infrastruktur, die den steigenden Anforderungen der KI-Welt gewachsen ist.




![Overflow Attacks in Telecommunications Hardware (CVE-2025-32105,06) [pdf]](/images/75F4957D-640B-407F-A3ED-D7CFF3BA1D5D)