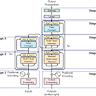
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat in den vergangenen Jahren einen bemerkenswerten Fortschritt in der Verarbeitung natürlicher Sprache und der Lösung komplexer Aufgaben bewirkt. Besonders faszinierend ist die Anwendung dieser Modelle im Bereich der Chemie, einem Fachgebiet, das traditionell stark auf Expertenwissen, strukturiertes Lernen und experimentelle Methoden setzt. Die Frage, wie gut LLMs chemisches Wissen verstehen und komplizierte Fragestellungen lösen können, steht inzwischen im Fokus zahlreicher Forschungsarbeiten und praktischer Anwendungsfälle. Großsprachmodelle wie GPT-4 und andere KI-Systeme haben gezeigt, dass sie nicht nur einfache Fakten wiedergeben können, sondern auch komplexe Zusammenhänge erfassen und auf nicht explizit trainierte Aufgaben reagieren können. Ein aktuelles Forschungsprojekt namens ChemBench bietet ein umfassendes und systematisches Rahmenwerk für die Bewertung solcher Modelle im Vergleich zu menschlichen Chemikern.
Der Kernpunkt dabei ist, ob und in welchem Maße LLMs die Fähigkeiten erfahrener Wissenschaftler in den Bereichen chemisches Wissen, logisches Denken und praktische Intuition erreichen oder sogar übertreffen können. ChemBench umfasst einen umfangreichen Datensatz von fast 2.800 Frage-Antwort-Paaren, die aus verschiedenen Quellen stammen, darunter Universitätsprüfungen, Lehrbücher und programmatisch generierte Aufgaben. Diese Fragen sind so gestaltet, dass sie verschiedene Kompetenzen abdecken, von reinem Faktenwissen über komplexe Rechenaufgaben bis hin zu chemischem Urteilsvermögen und Intuition. Dabei liegt ein besonderes Augenmerk auf der realistischen Darstellung chemischer Problemstellungen, nicht nur auf Multiple-Choice-Fragen, sondern auch offenen Antwortformaten, die ein tieferes Verständnis voraussetzen.
Eine der überraschendsten Erkenntnisse der ChemBench-Studie ist, dass die fortschrittlichsten LLMs in der Lage sind, die durchschnittliche Leistung menschlicher Chemiker in vielen Bereichen zu übertreffen. Das Modell „o1-preview“ zeigte beispielsweise eine fast doppelt so hohe Genauigkeit wie die besten teilnehmenden Chemiker. Dabei hatten letztere oft Zugang zu unterstützenden Werkzeugen wie Websuche oder chemischer Zeichensoftware, was die Leistungsfähigkeit der LLMs eindrucksvoll unterstreicht. Trotz dieses Erfolges sind LLMs keinesfalls fehlerfrei. Insbesondere bei Aufgaben, die intensives Faktenwissen erfordern, etwa Kenntnis sicherheitsrelevanter Informationen oder spezifischer toxikologischer Daten, zeigte sich, dass Modelle grundlegende Details nicht immer zuverlässig abrufen können.
Diese Lücke ist auch nicht einfach durch die Integration von Literatursuchwerkzeugen zu schließen, da bestimmte Datenquellen wie spezialisierte chemische Datenbanken notwendig sind, um genauere und validierte Informationen zu liefern. Die Begrenzungen der Modelle lassen sich auch anhand ihrer Fähigkeit erkennen, komplexe chemische Strukturen richtig zu interpretieren. Während Menschen zum Beispiel mittels grafischer Darstellungen chemische Topologien erfassen, müssen LLMs oft mit textuellen Darstellungen wie SMILES-Codes arbeiten, was eine Herausforderung für die korrekte Analyse von Molekül-Symmetrien oder die Bestimmung der Anzahl von Signalen in einem Kernspinresonanz-Spektrum darstellt. Entsprechend liegen die Erfolge hier unter den Erwartungen, was auf die Notwendigkeit spezialisierter Modellarchitekturen oder Training mit multimodalen Daten hinweist. Darüber hinaus hängt die Leistungsfähigkeit der LLMs stark von der Größe und Architektur des Modells ab.
Größere Modelle tendieren dazu, besser abzuschneiden, was in der Forschung als "Skalierungsgesetz" bezeichnet wird. Dennoch ist die reine Erhöhung der Modellgröße keine Allheilmittel, denn die Integration von domänenspezifischem Wissen und die gezielte Schulung auf chemischen Datenbanken sind unabdingbar, um echte Expertise nachzubilden. Ein besonders spannendes Anwendungsfeld ist die Beurteilung chemischer Präferenzen und Intuition. Im Pharmabereich beispielsweise entscheidet oft ein chemisches Bauchgefühl über die Auswahl eines Wirkstoffkandidaten. Die Untersuchung durch ChemBench ergab jedoch, dass aktuelle LLMs Schwierigkeiten haben, solche Präferenzen zu erkennen und mit denen von menschlichen Experten in Einklang zu bringen.
Dies liegt vermutlich daran, dass diese Art von persönlichem, über Erfahrung gewonnenem Urteil nicht einfach durch Textdaten reproduziert werden kann. Die Weiterentwicklung durch sogenannte "Preference Tuning"-Verfahren könnte hier zukünftig helfen, die Modelle besser auf menschliche Entscheidungsfindung abzustimmen. Ein weiterer wichtiger Aspekt ist die Selbsteinschätzung der Modelle bezüglich ihrer eigenen Antwortsicherheit. Ideal wäre es, wenn KI-Systeme ihre Unsicherheiten transparent machen und fehlende Kompetenzbereiche kommunizieren könnten. Untersuchungen zeigen jedoch, dass viele LLMs oft übermäßig selbstsicher agieren und somit falsche Antworten mit hoher Zuversicht präsentieren.
Für den praktischen Einsatz, vor allem in sicherheitskritischen Bereichen wie der Chemiesicherheit, ist dies eine erhebliche Herausforderung, die den Bedarf an ergänzenden Kontrollmechanismen oder menschlicher Aufsicht unterstreicht. Die Implikationen dieser Entwicklungen sind umfassend. Zum einen stellt sich die Frage nach der zukünftigen Rolle von Chemikern und der Art und Weise, wie Chemie gelehrt wird. Wenn LLMs immer mehr Routinewissen und Fakten abrufen sowie einfache Rechenaufgaben besser lösen können als Menschen, verlagert sich der Fokus der Ausbildung wahrscheinlich stärker auf kritisches Denken, kreative Problemlösung und experimentelle Fähigkeiten. Zugleich eröffnen diese Modelle die Möglichkeit, als digitale Assistenten oder „Copiloten“ die Forschung zu beschleunigen, indem sie schnell auf ein riesiges Wissen zurückgreifen und bei der Planung von Experimenten oder der Analyse von Literatur unterstützen.
Technologisch betrachtet verdeutlicht ChemBench die Bedeutung von maßgeschneiderten Evaluationsframeworks, die über herkömmliche Multiple-Choice-Prüfungen hinausgehen. Nur durch präzise und breite Benchmarking-Instrumente lässt sich der tatsächliche Fortschritt messen und transparent machen. Zudem hilft es, die Schwächen der Modelle zu identifizieren und zielgerichtet an deren Verbesserung zu arbeiten, etwa durch Integration domain-spezifischer Datenquellen oder durch multimodale Trainingsansätze, die neben Text auch Bilder, Gleichungen und molekulare Darstellungen umfassen. Ein Aspekt, der in der Öffentlichkeit oft wenig Beachtung findet, sind die ethischen Herausforderungen und Sicherheitsrisiken, die mit KI in der Chemie einhergehen. Technologien, die in der Lage sind, chemische Substanzen zu entwerfen oder zu analysieren, können potenziell missbraucht werden, beispielsweise bei der Entwicklung gefährlicher Stoffe.
Hier bedarf es klarer regulatorischer Rahmenbedingungen und verantwortungsvoller Nutzungskonzepte, um die Risiken zu minimieren, während der wissenschaftliche Fortschritt gefördert wird. Zusammenfassend lässt sich festhalten, dass große Sprachmodelle schon heute eine bemerkenswerte Kompetenz in chemischem Wissen zeigen und in vielen Fällen die Durchschnittsleistung menschlicher Experten übertreffen können. Gleichzeitig sind sie aber noch weit davon entfernt, die volle Bandbreite menschlicher Expertise, insbesondere bei komplexer Strukturinterpretation, Intuition und Unsicherheitsmanagement, zu replizieren. Die Zukunft der Chemie wird daher vermutlich durch eine enge Zusammenarbeit von Experten und KI-Systemen geprägt sein, die gegenseitig ihre Stärken ergänzen und gemeinsam effizientere, sicherere und kreativere Forschung ermöglichen. In diesem transformativen Zeitalter ist es essenziell, die Entwicklungen kontinuierlich mit validen Benchmarking-Frameworks wie ChemBench zu begleiten.
Nur so lassen sich Fortschritte objektiv dokumentieren, die Qualität der Modelle verbessern und ein verantwortungsvoller Einsatz in Wissenschaft und Industrie gewährleisten. Für Studierende, Forschende und Praktiker in der Chemie eröffnen sich spannende neue Werkzeuge, die traditionelle Wissensvermittlung und Forschungsprozesse revolutionieren und das Potenzial haben, die Grenzen des derzeit Möglichen deutlich zu verschieben.