Das Lernen aus menschlichen Präferenzen hat in den letzten Jahren enorm an Bedeutung gewonnen, vor allem im Bereich der künstlichen Intelligenz. Immer mehr Anwendungen, von interaktiven Systemen bis hin zu personalisierten Empfehlungen, verlangen eine präzise Modellierung und Interpretation menschlicher Vorlieben. Doch trotz der praktischen Erfolge stehen Forscher vor fundamentalen theoretischen Fragen, die das Verständnis und die Verbesserung dieser Verfahren erschweren. Der verbreitete Einsatz von Reinforcement Learning with Human Feedback (RLHF), also Verstärkendes Lernen mit menschlichem Feedback, stützt sich auf zwei wesentliche Annahmen, die in der Praxis oft getroffen werden. Erstens wird angenommen, dass sich paarweise Präferenzen - also die Auswahl einer bevorzugten Option gegenüber einer anderen - durch punktuelle Bewertungen, also einzelnen Belohnungen, ersetzen lassen.
Zweitens geht man davon aus, dass das Belohnungsmodell, das auf diesen punktuellen Rückmeldungen basiert, gut genug generalisiert und somit auch Verhalten außerhalb der ursprünglich gesammelten Daten verlässlich vorhersagen kann. Diese beiden Vereinfachungen erleichtern die Modellierung und ermöglichen die Funktionalität vieler Systeme, führen jedoch auch zu potenziellen Fehlerquellen. Wenn die Annahme nicht stimmt, dass paarweise Präferenzen durch punktuelle Belohnungen akkurat beschrieben werden können, kann das Modell inkorrekte Motivationselemente lernen. Ebenso ist die Generalisierung auf aus der Verteilung fallende Daten riskant, wenn das Belohnungsmodell nicht robust genug ist. Der jüngst vorgeschlagene Ansatz des Direct Preference Optimisation (DPO) versucht, der zweiten Annahme zu entgehen, indem er direkt eine Politik aus gesammelten Daten lernt, ohne dafür ein separates Belohnungsmodell zu verwenden.
Dieses Verfahren behebt also die Notwendigkeit, ein Belohnungsmodell zu trainieren, konzentriert sich aber weiterhin auf die erste Vereinfachung – nämlich die Ersatzannahme von paarweisen Präferenzen durch punktuelle Belohnungen. Um diese beiden zentralen Limitationen zu adressieren, setzen sich die Forscher mit einem neuen allgemeinen theoretischen Paradigma auseinander, welches unter der Bezeichnung \PsiPO firmiert. Dabei steht \PsiPO für ein generisches Optimierungsziel, das direkt mit paarweisen Präferenzen arbeitet und keine der beiden traditionellen Annahmen benötigt. Das bedeutet, dass dieses Paradigma einerseits die tatsächlichen Vergleichsdaten nutzt und andererseits ohne äußeres Belohnungsmodell auskommt. Dieser neue Ansatz ermöglicht es, bisherige Verfahren wie RLHF und DPO als Spezialfälle innerhalb eines übergeordneten Rahmens zu verstehen.
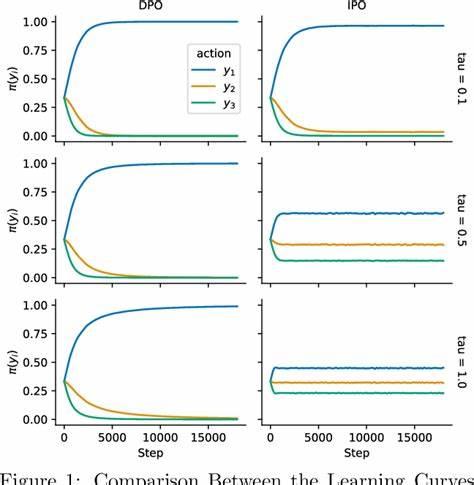
Durch diese theoretische Einbettung werden Rückschlüsse über deren Eigenschaften, Stärken und Schwächen möglich. So zeigen die Autoren auf, wo und wie etwa RLHF aufgrund der zugrundeliegenden Approximationen versagen oder suboptimale Entscheidungen treffen kann. Ebenso lassen sich die Grenzen von DPO unter dem Blickwinkel des \PsiPO-Frameworks genauer analysieren. Ein besonders interessanter Spezialfall entsteht, wenn \Psi als Identitätsfunktion gewählt wird. Hier können die Forscher eine effiziente Optimierungsstrategie entwickeln und zugleich strenge Leistungsgarantien beweisen.
In empirischen Tests auf erklärenden Beispielen zeigen sie zudem, dass dieses Verfahren dem DPO in seiner Effektivität überlegen sein kann. Solche Ergebnisse unterstreichen den praktischen Mehrwert dieses theoretischen Paradigmas, da es nicht nur das Verständnis schärft, sondern auch direkt verbesserte Lernalgorithmen ermöglicht. Die Bedeutung dieser Arbeit liegt somit nicht nur in der theoretischen Neuinterpretation des Lernens aus menschlichen Präferenzen, sondern auch in der praktischen Anwendung. Es wird ein Weg aufgezeigt, der es erlaubt, die Herausforderungen der aktuellen Methoden zu überwinden, um robustere und aussagekräftigere Modelle zu entwickeln. Gerade angesichts der zunehmenden Komplexität und Ambiguität menschlicher Rückmeldungen sind solche Fortschritte essenziell.
Zudem kann das Verständnis und die Anwendung von \PsiPO dazu beitragen, ethische und methodische Probleme zu minimieren. Indem das Lernen direkt aus den tatsächlichen Präferenzpaaren geschieht ohne Zwischenschritt über ein Belohnungsmodell, wird potenziell auch die Verzerrung reduziert, die durch falsche Annahmen oder fehlerhafte Generalisierung entsteht. Dies ist besonders relevant in sensiblen Kontexten wie der Moderation von Inhalten oder in Systemen, die Entscheidungen mit direktem Einfluss auf Menschen treffen. Abschließend lässt sich sagen, dass das vorgestellte Paradigma \PsiPO den Status quo im Bereich des Lernens aus menschlichen Präferenzen erheblich erweitert. Es schafft eine solide theoretische Basis, die existierende Ansätze integriert und zugleich neue Strategien ermöglicht.
Forschende und Entwickler bieten sich dadurch neue Werkzeuge an, um perfektionierte Modelle zu erschaffen, die sowohl auf theoretischer Ebene fundiert als auch in der Praxis wirkungsvoll sind. Die Weiterentwicklung und Anwendung solcher Paradigmen wird in den kommenden Jahren vermutlich eine zentrale Rolle spielen, um die Schnittstelle zwischen menschlicher Intuition und künstlicher Intelligenz noch effizienter und nachvollziehbarer zu gestalten. Der Zwischenschritt eines Belohnungsmodells könnte künftig überflüssig werden, was neue Horizonte für personalisierte, faire und nachvollziehbare KI-Systeme eröffnet. Insgesamt handelt es sich um einen Meilenstein in der Erforschung von Lernmethoden aus menschlichen Präferenzen, der sowohl theoretisch als auch praktisch wegweisend ist.