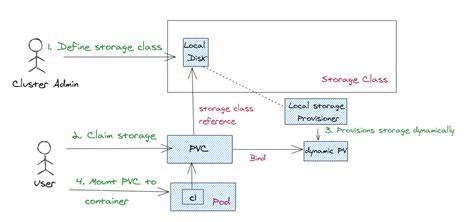
Kubernetes entwickelt sich kontinuierlich weiter, um den steigenden Anforderungen moderner Container-Orchestrierung gerecht zu werden. Ein zentrales Thema dabei ist die Verwaltung von Speicherressourcen, insbesondere bei der automatischen Bereitstellung von Persistent Volumes (PV) in dynamischen Umgebungen. Mit der Einführung von Kubernetes Version 1.33 wurde erstmals eine alpha-Funktion vorgestellt, die als Storage Capacity Scoring bekannt ist und entscheidende Verbesserungen bei der Planung von Pods mit speicherbezogenen Anforderungen ermöglicht. Die Speicherverwaltung in Kubernetes stellt häufig eine Herausforderung dar, da die verfügbaren Ressourcen der einzelnen Nodes stark variieren können.
Insbesondere bei node-lokalen Volumes, deren Kapazität durch den physischen Speicher des Hosts begrenzt ist, kann die herkömmliche Filterung unzureichend sein. Bisher wurden Knoten mit unzureichendem Speicherplatz lediglich für die Volume-Bindung ausgeschlossen, eine differenzierte Bewertung der Speicherverfügbarkeit war aber nicht möglich. Storage Capacity Scoring erweitert diese Funktionalität signifikant, indem es bei der Pod-Planung eine Punktbewertung der Knoten nach deren verfügbarer Speicherkapazität ermöglicht. Das Ziel dieser Verbesserung ist es, die Platzierung von Pods nicht nur anhand der ausreichenden Speicherkapazität zu gewährleisten, sondern auch darauf zu achten, wie effizient dieser Speicher genutzt wird. Dabei können unterschiedliche Strategien verfolgt werden: Einerseits besteht die Möglichkeit, Pods bevorzugt auf Knoten mit besonders viel freiem Speicher zu planen, wodurch eine spätere flexible Erweiterung der PVs erleichtert wird.
Andererseits kann es in Cloud-Umgebungen mit Kostenfokus sinnvoll sein, Knoten gezielt saturiert zu verwenden, also Pods auf Knoten mit möglichst geringem verfügbarem Speicher zu bündeln, um ungenutzte Ressourcen und damit verbundene Betriebskosten zu minimieren. Technisch integriert sich Storage Capacity Scoring in den bestehenden VolumeBinding-Plugin des Kubernetes-Schedulers. Es verwendet dabei dynamisch erhobene Speicherkapazitätsinformationen der einzelnen Knoten, die über die Storage Capacity API bereitgestellt werden. So kann der Scheduler die Knoten nicht nur filtern, sondern eine differenzierte Bewertung vornehmen, welche Knoten für die geplanten Volumes am besten geeignet sind. Dies sorgt für eine ausgeglichenere und vorhersehbarere Verteilung der Speicheranforderungen.
Die Konfiguration dieser Funktion ist bewusst flexibel gestaltet. Administratoren können über sogenannte Shape-Parameter steuern, ob Knoten mit hohem oder niedrigem Speicherplatz bevorzugt werden sollen. Voreingestellt ist eine Priorisierung zugunsten der höheren verfügbaren Kapazität, um eine optimale Skalierbarkeit sicherzustellen. Durch das Anpassen dieses Parameters lassen sich aber gezielt Szenarien umsetzen, bei denen Kostenoptimierung oder Ressourcenbündelung im Vordergrund stehen. Ein weiterer wichtiger Aspekt ist die Ablösung der bisherigen alpha-Funktion VolumeCapacityPriority, welche bisher eine ähnliche Aufgabe erfüllte, jedoch nur bei der statischen Provisionierung genutzt werden konnte.
Storage Capacity Scoring bietet nicht nur eine deutlich verbesserte Integration in den Scheduling-Workflow, sondern ersetzt VolumeCapacityPriority vollständig. Dabei wurde auch die Standardlogik der Priorisierung geändert zugunsten der Berücksichtigung der nodespezifischen Kapazitäten mit Fokus auf Skalierbarkeit und Effizienz. Die Aktivierung von Storage Capacity Scoring erfolgt in der aktuellen Alpha-Phase über das Feature-Gate in der kube-scheduler-Konfiguration. Administratoren müssen dafür das Flag StorageCapacityScoring auf true setzen. Im weiteren Verlauf der Kubernetes-Entwicklung ist davon auszugehen, dass diese Funktion in einer späteren Version stabilisiert wird, was eine breite Nutzung in produktiven Clustern vorantreiben wird.
Aus Sicht der Praxis bringt Storage Capacity Scoring zahlreiche Vorteile. Zum einen verbessert es die Vorhersagbarkeit und Stabilität bei der Volumenbereitstellung, indem es verhindert, dass Volumes auf Knoten mit knapper Kapazität geplant werden. Zum anderen ermöglicht es, ressourcenintensive Umgebungen effizienter zu gestalten, etwa durch gezielte Bündelung von Pods und damit verbundenen Volumes auf ausgewählten Knoten, um Stromkosten oder Lizenzgebühren zu reduzieren. Darüber hinaus erleichtert die feine Steuerbarkeit der Speicherpriorisierung neue Betriebsmodelle, etwa hybride Cloud-Szenarien, bei denen lokale Ressourcen optimal ausgenutzt werden müssen, bevor auf externe Speicher oder zusätzliche Nodes zugegriffen wird. Die dadurch mögliche bessere Auslastung reduziert nicht nur Kosten, sondern trägt auch zur Umweltverträglichkeit bei.
Der Einsatz von Storage Capacity Scoring erfordert ein gewisses Verständnis der Kubernetes-Scheduler-Konfiguration sowie der aktuellen Kapazitätsdaten der Nodes. Letztere werden durch das Kubernetes-Storage-System erfasst und bereitgestellt. Dabei ist es wichtig, dass die zugrundeliegenden Metriken aktuell und korrekt sind, damit die Scoring-Entscheidungen valide bleiben. Deshalb ist die Integration mit Storage Capacity API und Monitoring-Tools entscheidend für den Erfolg. Abschließend lässt sich sagen, dass Kubernetes mit Storage Capacity Scoring einen weiteren wichtigen Schritt in Richtung intelligentere, ressourceneffizientere Speicherverwaltung macht.
Die Funktion bietet flexiblen Spielraum für verschiedene Betriebsanforderungen und ist damit zukunftssicher aufgestellt. Speziell für Organisationen, die dynamische Provisionierung mit node-lokalen Volumes und unterschiedlichen Nutzungsszenarien betreiben, stellt Storage Capacity Scoring ein mächtiges Werkzeug dar, um agile und kosteneffiziente Infrastruktur zu realisieren. Mit der fortschreitenden Stabilisierung dieser Funktion und zunehmender Verbreitung in produktiven Umgebungen wird sich der Nutzen von Storage Capacity Scoring weiter manifestieren und die Speicherverwaltung in Kubernetes nachhaltig verbessern. Das Verständnis und die richtige Konfiguration dieses Features können damit maßgeblich zum Erfolg moderner Cloud-nativer Anwendungen beitragen.