In der Welt der Datenbanken spielen Indexes eine zentrale Rolle für die Performance von SQL-Abfragen. Sie sind unverzichtbare Werkzeuge, um den Zugriff auf Daten zu beschleunigen und die Effizienz von Suchanfragen zu verbessern. Dabei stellt sich für Entwickler, Administratoren und Datenbankexperten oft die Frage, ob sie besser mehrere einzelne Indexes auf einzelne Spalten anlegen oder einen zusammengesetzten Index auf mehrere Spalten nutzen sollten. Diese Entscheidung ist nicht banal, denn sie hat tiefgreifende Auswirkungen auf die Ausführungszeiten von Abfragen und die Skalierbarkeit von Systemen. Zunächst einmal ist es wichtig, die Funktionsweise von Indexes in relationalen Datenbanken zu verstehen.
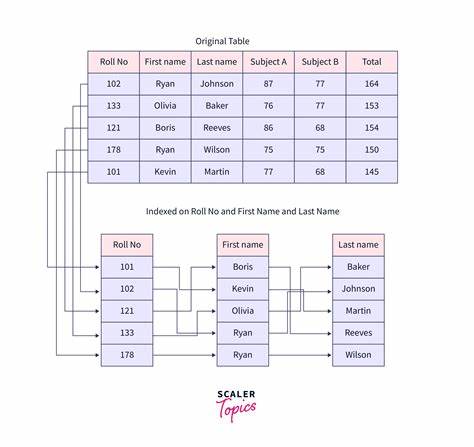
Ein Index verhält sich ähnlich wie ein Inhaltsverzeichnis in einem Buch: Er ermöglicht es dem Datenbanksystem, gezielt auf gewünschte Datensätze zuzugreifen, ohne die gesamte Tabelle durchsuchen zu müssen. Die gebräuchlichste Form in der Praxis ist der B-Baum-Index, der eine sortierte Struktur darstellt. Diese Struktur erlaubt schnelle Suchvorgänge, indem sie die Menge der zu durchsuchenden Einträge massiv reduziert. Ein zusammengesetzter Index, auch als Multi-Spalten- oder Verketteter Index bekannt, kombiniert mehrere Spalten in einer einzigen Indexstruktur. Das bedeutet, dass die Datensätze entlang dieser Spalten in einer bestimmten Reihenfolge sortiert sind.
Diese Art des Indexes bietet besonders dann Vorteile, wenn Abfragen in der WHERE-Klausel mehrere Kriterien kombinieren, die exakt oder teilweise mit den indexierten Spalten übereinstimmen. So kann die Datenbank effizient eine Schnittmenge der Indexeinträge finden und damit die Anzahl der zu lesenden Datensätze minimieren. Ein häufiger Irrglaube ist, dass es immer besser sei, mehrere einzelne Indexes zu legen, gerade weil dies auf den ersten Blick flexibler erscheint. Zwar ist es möglich, bei solchen separaten Indexes über sogenannte Index-Merge-Verfahren Teilresultate aus verschiedenen Indexes zu kombinieren, jedoch ist dieser Vorgang unter der Haube mit einem höheren Rechenaufwand verbunden. Die Datenbank muss die Ergebnisse aus mehreren Indexstrukturen zusammenführen, wodurch mehr Speicherbedarf und CPU-Zeit entstehen.
Dies kann bei komplexen oder sehr großen Datenmengen die Performance erheblich beeinträchtigen. Ganz entscheidend ist die Reihenfolge der Spalten im zusammengesetzten Index. Sie bestimmt, welche Abfragekriterien idealerweise unterstützt werden. Die Sortierung erfolgt immer in der Reihenfolge der im Index definierten Spalten, was bedeutet, dass die erste Spalte eine besonders wichtige Rolle spielt. Abfragen, die mit Bedingungen zur ersten Spalte starten, profitieren am meisten von dem Index.
Definierte Filter auf die nachfolgenden Spalten werden dagegen erst wirksam, wenn die erste Spalte bereits in der Suche verwendet wird. Dies erklärt, warum der häufig empfohlene Ansatz lautet, die selektivste, also die am stärksten einschränkende Spalte, an erster Stelle des Index zu platzieren. Es gibt jedoch Ausnahmen von der Regel. Ein typisches Beispiel sind Abfragen mit mehreren unabhängigen Bereichsbedingungen, etwa wenn mit weniger-als-Vergleichen ( < ) oder größeren-als-Vergleichen ( > ) mehrere Spalten betreffen. Die Struktur eines B-Baum-Indexes erlaubt es nicht, zwei unabhängige Bereichssuchen effektiv gleichzeitig zu unterstützen.
Da die Einträge linear und entlang einer Dimension geordnet sind, kann der Index nur eine Bereichssuche gut abdecken. Wird der Index auf eine Spalte mit einem Bereichsfilter und auf eine zweite Spalte ebenfalls mit einem Bereichsfilter angewendet, muss die Datenbank den Filter auf die zweite Spalte als zusätzlichen Filter nachträglich anwenden, was wieder mehr Rechenaufwand bedeutet. In solchen Fällen könnte der Ansatz, zwei separate Indexes zu verwenden und deren Ergebnisse mit Hilfe der Abfrageoptimierung zusammenzuführen, eine Alternative sein. Dennoch ist dieser Weg nicht optimal. Die Kombination von zwei Index-Suchen erfordert häufig mehr Zeit als ein gezielter Zugriff über einen gut definierten zusammengesetzten Index.
Die sogenannte Index-Merge-Strategie wird meist nur eingesetzt, wenn kein passender zusammengesetzter Index existiert. Eine technische Besonderheit stellen sogenannte Bitmap-Indexes dar, die häufig in Data-Warehouse-Umgebungen Verwendung finden. Diese Index-Typen sind speziell für Spalten mit geringer Kardinalität geeignet und ermöglichen eine effiziente Kombination von Einzelindexes, da sie bitweise Verknüpfungen der Ergebnisse erlauben. Allerdings sind Bitmap-Indexes für Onlinetransaktionsverarbeitungssysteme (OLTP) wegen ihrer schlechten Skalierbarkeit bei Schreiboperationen kaum geeignet. Sie führen bei vielen gleichzeitigen Einfügungen, Aktualisierungen oder Löschungen zu erheblichen Performanceproblemen.
Darüber hinaus bieten einige moderne Datenbanksysteme hybride Ansätze an. Dabei werden aus Ergebnissen mehrerer B-Baum-Scans temporär bitbasierte Strukturen im Speicher generiert, um eine effizientere Kombination der Zwischenergebnisse zu ermöglichen. Diese Technik nutzt zwar einen hohen Arbeitsspeicher und kann die CPU stärker beanspruchen, ist aber ein Kompromiss, wenn ein optimierter zusammengesetzter Index nicht verfügbar ist. Ein weiterer wichtiger Aspekt ist die Wartung von Indexes. Zusammengesetzte Indexes belegen mehr Speicherplatz und verursachen bei Schreiboperationen höheren Aufwand als einzelne Indexes, da mehrere Spaltenindexwerte aktualisiert werden müssen.
Dies kann sich insbesondere bei stark schreiblastigen Anwendungen negativ auswirken. Daher sollte die Entscheidung für einen Mehrspaltenindex wohl überlegt sein und auf den typischen Abfragemustern basieren. Die Wahl zwischen einzelnen und zusammengesetzten Indexes sollte stets vom Abfrageverhalten und von der Datenstruktur abhängig gemacht werden. Für häufig vorkommende Abfragen, die bestimmte Spaltenkombinationen in der WHERE-Klausel verwenden, sind zusammengesetzte Indexes nahezu immer die bessere Wahl. Sie reduzieren die Anzahl der notwendigen Dateneingriffe und ermöglichen schnelleres Auffinden passender Datensätze.
Wenn hingegen die Filterungen immer nur auf einzelnen, unterschiedlichen Spalten erfolgen und das kombinierte Abfrageverhalten nur selten eine Rolle spielt, kann es sinnvoller sein, einzelne Indexes zu erstellen. Aber selbst dann ist die Leistungsfähigkeit von Index-Merge-Strategien begrenzt und ein genaues Monitoring der Abfragepläne empfiehlt sich. Ein praxisnahes Vorgehen zur Indexoptimierung beginnt mit der Analyse der häufigsten und wichtigsten Abfragefälle. Die Verwendung von EXPLAIN- oder ähnlichen Tools liefert wertvolle Einblicke in die tatsächlichen Zugriffspläne. Anhand dieser Erkenntnisse können dann gezielt zusammengesetzte Indexes für die am häufigsten kombinierten Spalten definiert werden.
Gleichzeitig sollten einzelne Indexes für Spalten bleiben, die isoliert häufig abgefragt werden. Fazit ist, dass zusammengesetzte Indexes in der Regel eine effektivere und effiziente Lösung sind, um mehrere Spalten in Abfragen zu unterstützen. Sie bieten optimale Performance, wenn sie passend zu den Abfragebedingungen angelegt werden. Einzelindexe haben ihre Berechtigung vor allem, wenn unabhängige Suchkriterien häufig und variantenreich vorkommen. Die Kenntnis der Datenbankstruktur, der Abfragen und der Indexfunktionsweise ist unerlässlich, um die richtige Balance zu finden und Spitzenleistungen bei der Datenabfrage zu erzielen.
Insgesamt ist das Thema Indexierung in SQL-Datenbanken ein komplexes Feld und geht weit über einfache Regeln hinaus. Es erfordert ein tiefes Verständnis der Daten, Abfragemuster und der internen Abläufe der Datenbanksysteme. Wer hier die richtigen Entscheidungen trifft, sichert sich entscheidende Wettbewerbsvorteile durch schnellere Datenverarbeitung und eine bessere Skalierbarkeit seiner Anwendungen.