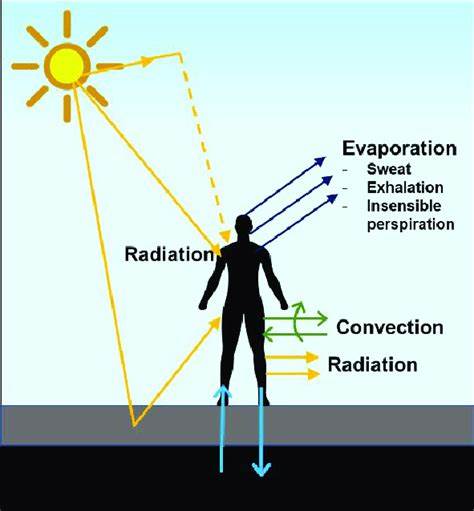
Mit dem rasanten Fortschritt der Künstlichen Intelligenz, insbesondere der generativen Modelle, verändert sich die Art und Weise, wie Software entwickelt wird, grundlegend. Large Language Models (LLMs) werden immer häufiger nicht nur als Werkzeuge, sondern als aktive Mitautoren im Entwicklungsprozess eingesetzt. Doch dieser Wandel wirft nicht nur technische Fragen auf, sondern auch tiefgreifende philosophische und epistemologische Fragestellungen darüber, wie wir Fehler verstehen, bewerten und kontrollieren – sowohl in Code, der von Menschen als auch von Maschinen generiert wurde. Ein zentrales Konzept, das in diesem Kontext besondere Aufmerksamkeit verdient, ist die Unterscheidung zwischen den verschiedenen "Architekturen des Fehlers". Während menschliche Fehler im Code vor allem auf kognitive Prozesse, Erfahrung, Intuition und kreatives Denken zurückzuführen sind, ergeben sich Fehler in KI-generiertem Code aus stochastischen Prozessen und statistischer Mustererkennung.
Diese Grundverschiedenheit beeinflusst maßgeblich die Struktur, Art und Behebbarkeit von Fehlern. Die menschliche Programmierung ist durch intentionale Planung geprägt. Entwickler denken über Anforderungen, mögliche Szenarien und logische Strukturen nach. Fehler entstehen dabei häufig aus Übersehen, Verständnislücken oder bewussten Abkürzungen – also aus mentalen und sozialen Faktoren. Dagegen beruht KI-generierter Code auf Trainingsdaten und Wahrscheinlichkeitsmodellen, die Verbindungen zwischen Sprachelementen und Programmierkonzepten herstellen.
Fehler können hierbei als Stochastische Inkohärenzen oder fehlerhafte Generalisierungen auftreten, was es manchmal schwierig macht, die Ursache sauber zu identifizieren. Aus philosophischer Sicht stützt sich diese Analyse auf Konzepte wie Dennetts mechanistischer Funktionalismus, der beschreibt, wie mentale Prozesse durch mechanische Abläufe ersetzt oder simuliert werden können, und Reschers methodologischen Pragmatismus, der Wissen als ein nutzorientiertes Verfahren versteht. In Kombination helfen diese Theorien, die unterschiedlichen Fehlertypen und deren epistemische Implikationen besser zu fassen und zu differenzieren. Der menschliche Fehler ist hier im Kontext von intentionalem Wissen und bewusster Kontrolle verortet, der KI-Fehler dagegen innerhalb eines probabilistischen, datengetriebenen Rahmens. Eine weitere wichtige Dimension in der Diskussion liefert Floridis Konzept der Abstraktionsebenen.
Er zeigt auf, wie verschiedene Betrachtungsweisen und Interpretationsrahmen sowohl auf der menschlichen als auch auf der maschinellen Seite Einfluss auf das Verständnis von Fehlern nehmen. Während ein Entwickler auf einer höheren Abstraktionsebene das große Ganze im Blick hat, arbeitet die KI auf niedrigeren Ebenen, in denen konkrete Datenmuster verknüpft werden. Dieses Ungleichgewicht beeinflusst, wie Fehler wahrgenommen und behandelt werden. Die praktischen Konsequenzen dieser theoretischen Unterscheidungen sind enorm. In der noch jungen Ära der Mensch-KI-Kollaboration in der Softwareentwicklung stellen sich Fragen nach Sicherheit, Robustheit und Kontrolle fundamentaler denn je.
Menschliche Programmierer sind es gewohnt, Fehler durch Tests, Reviews und bewusste Reflexion zu minimieren oder zu korrigieren, während KI-generierter Code oft unerwartete Schwachstellen aufweist, die sich aus unsichtbaren Trainingsdatenabhängigkeiten ergeben. Diese Situation erfordert neue Strategien und Werkzeuge, um Risiken zu managen und Vertrauen in die Software zu gewährleisten. Die epistemischen Grenzen bei der Arbeit mit KI-codiertem Programmcode sind ebenfalls erheblich. Da die KI keine echte Intentionalität oder Verständnis besitzt, sondern auf Wahrscheinlichkeiten basiert, führt dies oft zu sogenannten "Halluzinationen" – fehlerhaften oder inkonsistenten Ausgaben, die plausibel erscheinen, aber inhaltlich falsch sind. Das stellt Entwickler und Unternehmen vor Herausforderungen, da die Validierung und Verifikation solcher Codes umfassender und kritischer erfolgen müssen.
Gleichzeitig zwingt uns der Einsatz von KI-generiertem Code zu einer Neubewertung menschlicher Programmierrollen. Der tradierten Vorstellung des Programmierers als alleinigen Schöpfer und Wächter des Codes tritt das Bild einer symbiotischen Zusammenarbeit mit maschinellen Akteuren gegenüber. Dabei wird die Verantwortung für Fehler nicht einfach geteilt, sondern es entsteht eine komplexe Dynamik, in der sowohl die technische Architektur der Systeme als auch ethische und rechtliche Fragestellungen berücksichtigt werden müssen. Philosophisch gesprochen fordert die Maschine das menschliche Wissen heraus und eröffnet dabei auch einen kritischen Blick auf die Grenzen unserer Erkenntnis und Kontrolle. Developer müssen lernen, die Fehlerarchitekturen der KI zu verstehen, um sie produktiv zu nutzen und zugleich zu beherrschen.
Nur so kann eine nachhaltige und sichere Softwareentwicklung gelingen, die die Vorzüge beider Welten – menschliche Kreativität und maschinelle Effizienz – miteinander verbindet. Abschließend lässt sich festhalten, dass die Unterscheidung der Fehlerarchitekturen zwischen menschlich und KI-generiertem Code weit mehr als eine technische oder organisatorische Frage ist. Sie führt uns in den Kern epistemologischer Herausforderungen, die das Zeitalter der generativen KI prägen. Sie laden sowohl Philosophen als auch Techniker ein, neue Modelle des Verstehens, Operation und der Verantwortung zu entwickeln, die der tiefgreifenden Transformation der Softwareentwicklung gerecht werden. Diese Debatte ist ein bedeutender Schritt hin zu einer fundierten, kritischen und reflektierten Nutzung von Künstlicher Intelligenz im Programmieralltag.
Nur durch sorgfältiges Nachdenken und methodisches Vorgehen können wir die komplexen Wechselwirkungen von menschlichem und maschinellem Wissen beherrschen und die Sicherheit, Qualität sowie Transparenz der erzeugten Software nachhaltig sichern.