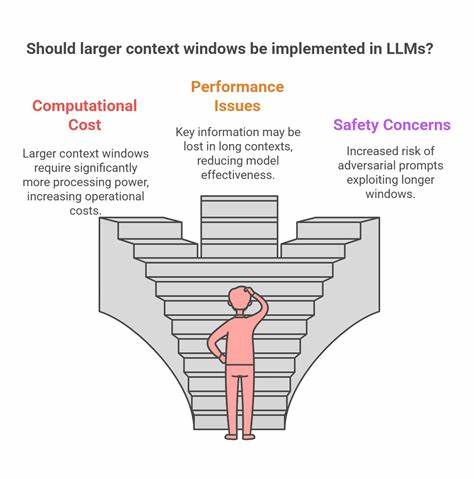
In der Welt der Künstlichen Intelligenz revolutionieren große Sprachmodelle (LLMs) zunehmend die Art und Weise, wie wir mit komplexen Daten und Programmcode interagieren. Besonders spannend ist die Weiterentwicklung der Kontextlänge, also die Menge an Information, die ein Modell in einem einzigen Durchgang verarbeiten kann – diese hat sich in den letzten Jahren von einigen Tausend auf nun erstaunliche eine Million Tokens ausgeweitet. Diese Entwicklung eröffnet völlig neue Möglichkeiten, stellt aber auch neue Herausforderungen dar, insbesondere wenn es darum geht, realistische und praxisnahe Testszenarien zu finden, die solche langen Kontextfenster wirklich benötigen. Genau hier setzt LongCodeBench an, ein innovativer Benchmark, der speziell zur Evaluierung von Coding LLMs mit extrem langen Kontexten konzipiert wurde.LongCodeBench wurzelt in einer einfachen, jedoch wichtigen Erkenntnis: Für viele Anwendungen ist das Verstehen und Reparieren von Programmcode ausgedehnter und komplexer Projekte eine natürliche Aufgabe, die große Kontextfenster sinnvoll nutzt.
Längere Kontextfenster ermöglichen es Modellen, nicht nur einzelne Funktionen oder Code-Snippets, sondern ganze Softwareprojekte oder umfangreiche Fehlermeldungen, Diskussionsprotokolle und Bug-Reports zu erfassen. Damit rückt LongCodeBench die Verbesserung der praktischen Leistungsfähigkeit von LLMs bei Softwareentwicklung und -wartung in den Fokus.Die Schaffung eines Benchmarks für eine Million Tokens Kontext stellt Forscher vor mehrere Hürden. Zum einen erfordert das Sammeln entsprechender Aufgaben und Daten einen enormen Aufwand, da reale Szenarien notwendig sind, um Übertragbarkeit und Anwendbarkeit sicherzustellen. Zum anderen gestaltet sich die technische Umsetzung anspruchsvoll, da die Rechenleistung und die Speicheranforderungen dramatisch ansteigen, wenn Modelle solch große Datenmengen gleichzeitig verarbeiten müssen.
LongCodeBench begegnet diesen Herausforderungen durch die Nutzung von GitHub als reichhaltige Datenquelle. GitHub-Issues und Bug-Reports bieten authentische, verlängerte Konversationen zwischen Entwicklern und Testergebnissen, die als natürliche Anwendungsfälle für langkontextuelle Analyse gelten.Ein besonderes Merkmal von LongCodeBench ist die Zweiteilung in Langzeit-Codefragen (LongCodeQA) und Langzeit-Softwareentwicklungsbenchmarks (LongSWE-Bench). LongCodeQA fokussiert auf die Fähigkeit von Modellen, umfangreiche Fragen zu einem gegebenen Codeprojekt zu beantworten, wobei das Kontextfenster sämtliche relevanten Code-Teile und Dokumentationen abdeckt. LongSWE-Bench ist auf die Bugbehebung spezialisiert: Modelle müssen mühselig Fehler im Kontext eines großen Softwareprojekts lokalisieren und reparieren.
Beide Aufgaben stellen hohe Anforderungen an das Modellverständnis und die gedankliche Kombination von Informationen über weite Textabschnitte hinweg.Die Vielschichtigkeit des Benchmarks erlaubt es, Modelle unterschiedlicher Größe und Architektur gegeneinander antreten zu lassen. So wurden beispielsweise Modelle wie Qwen2.5 mit 14 Milliarden Parametern und Googles Flaggschiff Gemini auf ihre Performance getestet. Die Ergebnisse zeigen klare Schwächen selbst bei modernsten LLMs, sobald die Kontextgröße exponentiell wächst.
Leistungsabfälle von bis zu 70,2 Prozent auf 40 Prozent bei Qwen2.5 oder von 29 auf nur noch 3 Prozent bei Claude 3.5 Sonnet demonstrieren, wie anspruchsvoll die Aufgabe langer Kontextbehandlung ist. Trotz dieser Rückschläge ist die Forschungsrichtung vielversprechend, da die Verbesserung der Kontextlänge für zukünftige KI-Anwendungen im Softwarebereich essenziell ist.Die Bedeutung dieser Forschung liegt nicht nur in der reinen Skalierung von Kontextfenstern.
Vielmehr geht es um die praktische Einsetzbarkeit von Künstlicher Intelligenz in der Softwareentwicklung. Lange Kontexte bedeuten, dass Modelle komplexe Projekte in einem Schritt überblicken können, was die Effizienz bei Codeüberprüfung, Fehlersuche und Codegewinnung markant verbessern könnte. Gleichzeitig wird die Fähigkeit gestärkt, vergangene Diskussionen, Benutzeranfragen und Codeänderungen kontextsensitiv zu berücksichtigen. Diese Entwicklung könnte die Zusammenarbeit zwischen Entwicklerteams und Automatisierungstools auf eine neue Ebene heben.Darüber hinaus wirft LongCodeBench auch ein Licht auf die zukünftigen Forschungsfelder.
Beispielsweise stellt sich die Frage, wie Speicher- und Rechenressourcen optimiert werden können, um solche extrem langen Kontexte handhabbar zu machen. Oder wie man Modelle trainiert, die trotz riesiger Datenmengen präzise und effizient bleiben. Ebenso interessant ist die Untersuchung von Strategien zur Segmentierung oder Priorisierung von Kontextabschnitten, um irrelevante Informationen zu filtern und den Fokus auf tatsächliche Problembereiche zu richten.Der Anspruchssprung im Bereich der Coding LLMs durch LongCodeBench ist sowohl für Entwickler als auch für KI-Forscher von enormer Bedeutung. Für Unternehmen bedeutet dies, dass die Integration solcher Modelle in Entwicklungszyklen noch besseren Support bei der Bewältigung komplexer Projekte bieten kann, insbesondere wenn es um das Verständnis historischer Codebasis, das Beheben von tiefsitzenden Fehlern oder das Management großer, verteilter Codesysteme geht.
Für Forschungseinrichtungen und Modellbauer bietet der Benchmark eine standardisierte Möglichkeit, Fortschritte transparent zu messen und gezielt an Schwachstellen zu arbeiten.LongCodeBench verdeutlicht letztlich, dass das Zeitalter der extrem langen KI-Kontexte neue Herausforderungen, aber auch enorme Chancen mit sich bringt, besonders im Bereich der Softwareentwicklung und des Programmierens. Modelle, die das volle Potenzial von Kontextlängen im Millionenbereich ausschöpfen, könnten den Arbeitsalltag von Entwicklern revolutionieren, indem sie komplexe Codestrukturen schneller durchdringen, präzisere Diagnosen liefern und dynamischere Lösungen vorschlagen. Die Zukunft von Coding LLMs ist eng mit dieser Skalierung von Kontextfenstern verbunden, und LongCodeBench leistet einen wichtigen Beitrag, um diesen Wandel methodisch und praxisorientiert voranzutreiben.