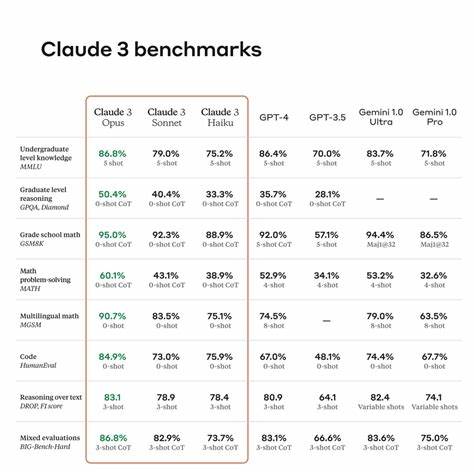
Sprachmodelle spielen eine immer wichtigere Rolle in der Entwicklung moderner Softwarelösungen. Sei es zur Automatisierung von Kundenservice, zur Erstellung von Textinhalten oder zur Unterstützung bei der Softwareentwicklung – die Auswahl des richtigen Modells beeinflusst entscheidend die Qualität und Effizienz der Anwendung. Dabei greifen Entwickler häufig auf Benchmarks zurück, um zu evaluieren, welches Modell sich am besten eignet. Doch was viele nicht wissen: Sprachmodell-Benchmarks erzählen nur die halbe Geschichte. Sie liefern zwar wichtige Vergleichswerte, sind aber häufig nicht repräsentativ für die individuellen Anforderungen und konkreten Einsatzszenarien.
Wer eine wirklich passende Lösung finden will, muss deutlich tiefer gehen und eigene, maßgeschneiderte Tests aufsetzen. Der erste Fehler ist, sich allein auf veröffentlichte Benchmark-Ergebnisse zu verlassen. Denn die Standardszenarien, auf denen diese Resultate basieren, sind oft generalisiert und für breit gefächerte Anwendungsfälle konzipiert. Tatsächlich variieren viele Faktoren je nach Einsatzgebiet. Welche Texte sollen generiert werden? Welche Qualität und welchen Stil erwartet der Nutzer? Gibt es besondere Anforderungen wie Geschwindigkeit oder Ressourcenverbrauch? Ohne diese Kontextbetrachtung kann ein Benchmark kaum die tatsächliche Leistungsfähigkeit eines Modells widerspiegeln.
Beispielsweise zeigte eine Evaluation mit dem Sprachmodell Phi-3 im Rahmen der Entwicklung einer Proxy-Anwendung zur automatischen Generierung von OpenAPI-Spezifikationen, dass das laut Benchmark leistungsstarke Modell für diese spezielle Aufgabe ungeeignet war. Obwohl Phi-3 auf dem Papier schnell und kompetent schien, passte es in der Praxis nicht zur geforderten Präzision der API-Operationen, die für automatisierte Dokumentationen entscheidend sind. Dieses Beispiel verdeutlicht, wie essenziell es ist, die Modellleistung nicht nur anhand von verallgemeinerten Scores zu beurteilen, sondern im Rahmen des eigenen Anwendungsfalls zu testen. Eine der Herausforderungen bei der Bewertung von Sprachmodellen ist die naturgemäße Variabilität ihrer Ausgaben. Sprachmodelle sind generativ und produzieren bei wiederholter Eingabe desselben Prompts oft verschiedene Antworten.
Somit kann eine einfache Einzelauswertung keine zuverlässige Aussage gewährleisten. Stattdessen sollten Tester jeden Fall mehrfach durchspielen und die Ergebnisse mitteln, um eine repräsentative Wertung zu erzielen. Darüber hinaus existieren meist mehrere korrekte oder akzeptable Lösungen für eine Fragestellung oder Aufgabe. Dies erschwert das direkte Vergleichen mit vorgegebenen Referenzantworten, die nicht alle möglichen Varianten abdecken. Ein reines String-Matching führt hier schnell zu falschen Negativergebnissen und verzerrten Bewertungen.
Es ist daher sinnvoll, für jeden Testfall mehrere mögliche Antworten als Referenz einzubinden und dann das beste Matching-Ergebnis für die Bewertung heranzuziehen. Zur objektiveren Bewertung der Sprachmodellausgaben haben sich verschiedene Bewertungsmetriken etabliert. Unter diesen sind BLEU, ROUGE, BERTScore und der Editierabstand (Edit Distance) besonders verbreitet. Jede dieser Metriken betrachtet die Qualität anders: BLEU und ROUGE messen den Grad der Wörter- oder Phrasen-Übereinstimmung, Edit Distance misst die Anzahl der erforderlichen Änderungen, um zwei Texte anzugleichen, und BERTScore analysiert die semantische Ähnlichkeit auf Basis neuronaler Repräsentationen. Für eine realistische Gesamtbewertung ist häufig eine Kombination mehrerer Metriken sinnvoll, wobei jede mit einem Gewicht versehen wird, das ihrer Bedeutung für den jeweiligen Anwendungsfall entspricht.
In der Praxis kann man so beispielsweise beim Generieren von API-Operationen dem BERTScore das höchste Gewicht geben, um die semantische Genauigkeit zu priorisieren. ROUGE-Werte ergänzen die Bewertung durch die Betrachtung der Wort- und Phrasenüberlappung, während der Edit Distance sicherstellen soll, dass die erzeugte Antwort nicht zu stark von den Erwartungen abweicht. Welches Gewicht welchem Kriterium zugewiesen wird, hängt von den persönlichen Präferenzen und Anforderungen ab und sollte begründet und transparent festgelegt werden. Ein weiterer wichtiger Aspekt besteht darin, dass Metriken wie BERTScore aufgrund ihrer Skalenverteilung speziell normalisiert werden müssen, um das Gesamtergebnis nicht zu verfälschen. Schwache BERTScore-Ergebnisse können sonst zu hoch bewertet und damit andere Qualitätseinschätzungen verzerrt werden.
Eine lineare Skalierung oder eine Schwellenwertbehandlung sorgt für eine fairere Einbindung in die Gesamtbewertung. Für Entwickler, die ihre Sprachmodelle selbst testen wollen, ist es ratsam, individuelle Benchmarks zu erstellen. Diese sollten auf realen Anwendungsfällen basieren und klar definierte Testfälle mit präzisen erwarteten Ergebnissen umfassen. Das ermöglicht nicht nur den Vergleich verschiedener Modelle, sondern auch die kontinuierliche Verbesserung der eingesetzten Prompts. Denn oft beeinflussen Kleinigkeiten im Prompt-Design die Modellperformance stärker als der Wechsel des Modells selbst.
Technisch bieten Jupyter Notebooks eine hervorragende Plattform, um solche Benchmarks aufzubauen. In Python können die vielfältigen Bibliotheken zur Textbewertung genutzt, Testläufe automatisiert, Modellantworten zwischengespeichert und Ergebnisse visuell dargestellt werden. Interaktive Ausführung und die Kombination von Code mit erklärendem Text ermöglichen ein tiefes Verständnis der Resultate. So entstehen transparente und reproduzierbare Evaluationsumgebungen. Für viele Anwender ist es zudem sinnvoll, eine solche Testplattform mit Schnittstellen zu unterschiedlichen Modellen zu gestalten.
Dazu gehören lokale Sprachmodelle genauso wie Cloud-Services. So lassen sich deren Ergebnisse direkt gegenüberstellen. Je nach verwendetem Szenario – ob das Erstellen von API-Beschreibungen, Chatbots oder automatisierten Zusammenfassungen – kann so das jeweils beste Modell ihres Fachbereichs optimal identifiziert werden. Am Ende lohnt es sich, Sprachmodelle stets mit Skepsis und kritischem Blick zu betrachten. Selbst die besten Benchmarks allgemeiner Art helfen nur, die grundsätzlichen Fähigkeiten einzuschätzen.
Die wirklichen Unterschiede zeigen sich erst in praxisnahen Tests. Sich auf externe Rankings zu verlassen, birgt die Gefahr, Modelle einzusetzen, die im eigenen konkreten Einsatz versagen. Durch eigene Benchmarks erkennen Entwickler ihre Stärken und Schwächen besser und gewinnen zudem Erkenntnisse, wie bestehende Prompts verbessert werden können. Die Suche nach dem besten Sprachmodell ist kein statischer Prozess. Die Modelle entwickeln sich ständig weiter, neue Modelle kommen hinzu, und auch die Anforderungen der Anwendungen ändern sich.
Regelmäßige Tests und Anpassungen sind daher Pflicht. Wer kontinuierlich misst, optimiert und vergleicht, stellt sicher, dass seine Lösung dauerhaft auf höchstem Niveau arbeitet und den Anforderungen der Nutzer gerecht wird. Ein bewusster und methodischer Umgang mit Sprachmodell-Benchmarks schützt vor Fehlentscheidungen und führt zu nachhaltigem Erfolg bei KI-basierten Anwendungen. Die Investition in eigene Evaluationssysteme zahlt sich langfristig aus – denn so findet jeder das Sprachmodell, das wirklich zu seiner individuellen Aufgabe passt.








