Amazon Web Services (AWS) hat mit der Einführung der neuen Amazon EC2 P6-B200 Instanzen eine bedeutende Innovation im Bereich Cloud-Computing und künstliche Intelligenz (KI) vorgestellt. Diese Instanzen sind mit den neuesten Nvidia Blackwell GPUs ausgestattet und richten sich an anspruchsvolle Anwendungen wie groß skalierte KI-Trainings, Multimodal-Modelle, Reinforcement Learning sowie verschiedene High Performance Computing (HPC)-Szenarien. Die Kombination aus leistungsfähiger Hardware und AWS-eigenen Technologien verspricht maximale Performance, verbesserte Skalierbarkeit und erweiterte Sicherheitsfunktionen – ideal für Unternehmen, Forschungsinstitute und Entwickler, die in der heutigen datengetriebenen Welt mit komplexen KI-Modellen arbeiten möchten. Nvidia Blackwell GPUs repräsentieren die nächste Generation grafikprozessorbasierter Beschleuniger und überzeugen mit einem erheblichen Leistungszuwachs im Vergleich zu Vorgängern. Die P6-B200 Instanzen bieten eine deutliche Steigerung der Rechenleistung dank acht Nvidia Blackwell Grafikprozessoren mit insgesamt 1440 Gigabyte High-Bandwidth GPU-Speicher, was die Verarbeitung großer Datenmengen für AI-Modelle deutlich effizienter und schneller gestaltet.
Ergänzt wird die GPU-Power durch modernste 5. Generation Intel Xeon Scalable Prozessoren der Emerald Rapids-Serie, 2 Terabyte Systemspeicher sowie 30 Terabyte lokalem NVMe-Speicher – eine Ausstattung, die auf intensive Rechenanforderungen optimiert ist. Besonders hervorzuheben ist die Speicherbandbreite und Kapazität der GPUs, die um 60 Prozent höhere Bandbreite und 27 Prozent größeren Speicher als die Vorgänger P5en Instanzen bieten. Das unterstützt komplexe Trainingsprozesse von Foundation Models, die zunehmend multimodale Daten aus Bildern, Text und anderen Quellen analysieren und lernen. Neben reiner Hardware leistet auch die Verbindung zwischen den Instanzen einen entscheidenden Beitrag zur Performance.
Die P6-B200 Instanzen nutzen das Elastic Fabric Adapter (EFAv4) Netzwerk, das hohe Bandbreiten bei gleichzeitig geringer Latenz erlaubt. Diese Netzwerktechnologie ist maßgeblich, wenn es darum geht, mehrere Instanzen in sogenannten UltraClusters effizient zu koppeln und nahtlos als großer Verbund zusammenzuarbeiten. Forschungsteams und Entwickler können so ihre KI-Trainings auf mehrere GPUs und Instanzen ausdehnen, ohne Performanceverluste hinnehmen zu müssen. Der AWS Nitro System, bekannt für Virtualisierung und Sicherheitsfeatures, stellt auf den P6-B200 Instanzen eine besonders robuste Umgebung bereit. Er gewährleistet nicht nur Isolation und Schutz der Daten, sondern optimiert gleichzeitig die Ressourcennutzung, was die Gesamteffizienz der Workloads erhöht.
Dies ist insbesondere in Branchen mit höchsten Sicherheitsanforderungen wie Gesundheitswesen, Finanzwesen oder Versicherungen von großer Bedeutung. Die Anwendungsbereiche der P6-B200 Instanzen sind vielfältig: Sie reichen von der großen Verteilung der KI-Modelltrainings über multimodale Modelle bis hin zu HPC-Anwendungen, wie etwa Klimasimulationen, Medikamentenentwicklung, seismischer Analyse oder Risiko-Berechnungen in der Versicherungswirtschaft. Die Leistungsvorteile gegenüber der Vorgängergeneration umfassen eine bis zu doppelte Beschleunigung der Trainingszeit sowie verbesserte Tokenverarbeitungsgeschwindigkeiten bei der Inferenz. Für Unternehmen bedeutet dies eine deutliche Senkung der Kosten für KI-Operationen und eine beschleunigte Time-to-Market ihrer Innovationen. Um die P6-B200 Instanzen effektiv zu nutzen, stellt AWS spezielle Deep Learning AMIs zur Verfügung, welche Entwicklern und Forschern eine vorgefertigte Umgebung mit allen notwendigen Frameworks und Tools bieten.
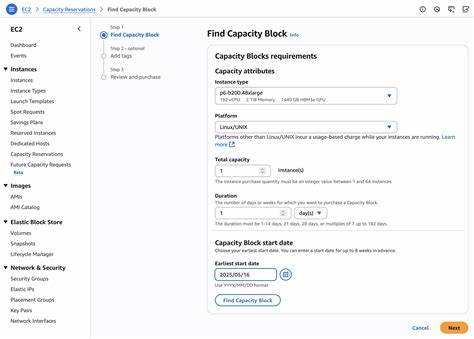
Dies erleichtert den Einstieg und die schnelle Umsetzung von Projekten erheblich. Zugleich unterstützt AWS verschiedene Zugangswege für die Instanzerstellung und -verwaltung, inklusive der AWS Management Console, AWS Command Line Interface und diversen SDKs, was die Integration in bestehende Workflows flexibel gestaltet. AWS bietet die neuen Instanzen zunächst in der Region US West (Oregon) als EC2 Capacity Blocks für maschinelles Lernen an. Kunden können hier Kapazitäten für variable Zeiträume reservieren, was Planungssicherheit schafft und eine optimale Ressourcennutzung ermöglicht. Diese Flexibilität ist gerade für Forschungs- und Entwicklungsprojekte interessant, die oft auf temporäre Hochleistungsrechner angewiesen sind.
Darüber hinaus arbeitet AWS kontinuierlich daran, die Integration der P6-B200 Instanzen mit weiteren Cloud-Diensten auszubauen, darunter Amazon Elastic Kubernetes Services (EKS), Amazon Simple Storage Service (S3) und Amazon FSx for Lustre. Die baldige Unterstützung durch Amazon SageMaker HyperPod verspricht zusätzlich eine noch effizientere Handhabung verteilter Trainingsjobs. Der Einsatz der P6-B200 Instanzen hilft Unternehmen und Wissenschaftlern, die Grenzen ihrer aktuellen Infrastruktur zu überwinden. Mit den verbesserten Rechenressourcen lassen sich komplexe KI-Modelle schneller trainieren, Multimodalität durch bessere Netzwerk und Speicherleistung abdecken sowie HPC-Anforderungen in verschiedenen Industrien erfüllen – sei es Klima, Gesundheit, Finanzen oder andere. Der Schritt zur nächsten Blackwell-Generation auf der AWS-Cloud-Plattform zeigt, wie stark die Zusammenarbeit zwischen Branchengrößen wie Nvidia und Amazon ist, um die Anforderungen einer KI-getriebenen Zukunft abzufedern.