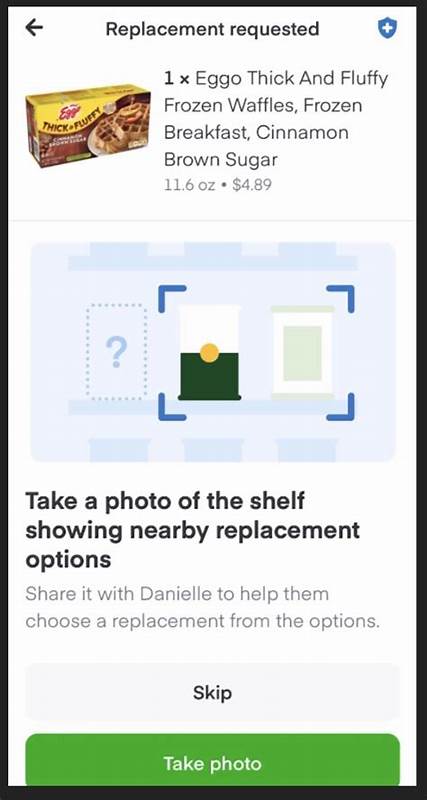
Im Zeitalter des E-Commerce und der Digitalisierung gewinnt der Online-Lebensmitteleinkauf immer mehr an Bedeutung. Besonders Plattformen wie Instacart machen es möglich, eine Vielzahl von Produkten mit nur wenigen Klicks zu bestellen und direkt nach Hause liefern zu lassen. Doch trotz modernster Logistik und großer Händlernetzwerke bleibt eine zentrale Herausforderung bestehen: Die Verfügbarkeit der gewünschten Produkte in Echtzeit ist oft nicht garantiert. Hier setzt Instacart auf wegweisende Technologien. Mit Hilfe von maschinellem Lernen entwickelt das Unternehmen ein intelligentes Ersatzempfehlungssystem, das Kunden alternative Produkte vorschlägt, wenn der ursprünglich gewünschte Artikel nicht vorrätig ist.
Dieses System hat das Potenzial, das Online-Shopping-Erlebnis maßgeblich zu verbessern und die Kundenzufriedenheit deutlich zu erhöhen. Die Problematik des fehlenden Lagerbestands stellt im Online-Handel einen der größten Stolpersteine dar. Während herkömmliche Geschäfte und auch viele Online-Shops auf manuelle oder einfache automatisierte Nachbestandsprozesse angewiesen sind, arbeitet Instacart daran, diesen Prozess durch künstliche Intelligenz deutlich effizienter und automatisch zu gestalten. Dabei geht es nicht nur darum, irgendeinen Ersatz zu finden, sondern einen Ersatz, der für den Kunden sinnvoll und akzeptabel ist. Die Vielfalt der Kundenwünsche und Produktmerkmale macht diese Aufgabe komplex.
Kunden legen Wert auf spezielle Marken, bestimmte Größen, organische oder diätetische Eigenschaften sowie Preisgrenzen. Instacarts Modell muss diese Faktoren genau berücksichtigen, um passende Produkte vorzuschlagen und damit Enttäuschungen zu vermeiden. Die Grundlage des Instacart-Ersatzempfehlungssystems bildet ein maschinelles Lernmodell, das anhand großer Datenmengen aus realen Kundenbestellungen trainiert wurde. Das Modell verarbeitet Produktattribute aus einem umfangreichen Katalog mit Tausenden von Artikeln und bewertet mögliche Ersatzprodukte nach Ähnlichkeit und Kundenzufriedenheit. Dabei kommen verschiedene Techniken zum Einsatz, um relevante Alternativen auszuwählen und zu bewerten.
Von entscheidender Bedeutung ist dabei die Balance zwischen sogenannten „Head“-Produkten, also oft gekauften und bekannten Artikeln, und „Tail“-Produkten, die weniger populär oder neu sind. Für etablierte Artikel steht eine Fülle von Daten zur Verfügung, wodurch Empfehlungen leicht personalisiert werden können. Hingegen erfordert die Strategie für weniger häufige Produkte ein stärker heuristisches Vorgehen basierend auf Produktattributen und semantischen Ähnlichkeiten. Instacart wählt potenzielle Ersatzprodukte über mehrere Kriterien aus. Zum Beispiel werden Produktempfehlungen auf Grundlage vergangener Ersatzkäufe generiert, die zeigen, welche Artikel Kunden bereits als Ersatz akzeptiert haben.
Ebenso spielen die Kategorisierung innerhalb des Sortiments, die Platzierung in bestimmten Ladenabschnitten oder Ähnlichkeiten in textuellen Produktbeschreibungen eine Rolle. Um die Berechnung effizient zu halten, begrenzt das System die Anzahl möglicher Ersatzkandidaten auf einen überschaubaren Pool von wenigen Hundert Artikeln pro Produkt. Für die finale Auswahl kommt eine tief lernende KI-Architektur, eine sogenannte zwei-türmige oder „Siamese“-Netzwerkstruktur, zum Einsatz. Diese verarbeitet gleichzeitig Eingabedaten des Originalproduktes und der Ersatzkandidaten, um deren Ähnlichkeit aus Kundensicht zu bewerten. Zu den bewerteten Merkmalen zählen neben dem Produktnamen auch Marken, Größenangaben und spezifische Ernährungsattribute wie „vegan“, „koscher“ oder „fettfrei“.
Durch die Kombination von Text-Embeddings, kategorischen und binären Merkmalen kann die KI komplexe Beziehungen erkennen und fundierte Wahrscheinlichkeitsschätzungen für die Eignung eines Ersatzprodukts liefern. Dabei wird das Modell kontinuierlich mit neuen Interaktionsdaten der Nutzer trainiert, um seine Vorhersagen zu verfeinern und den Wandel im Sortiment oder den Präferenzen abzubilden. Eines der größten Probleme im Ersatzempfehlungssystem ist der sogenannte „Head vs. Tail“ Effekt. Während populäre Produkte auf viele Nutzungsdaten zurückgreifen können, wodurch zuverlässige Empfehlungen einfach sind, fehlt bei selten bestellten oder neuen Produkten diese Grundlage.
Instacart begegnet dieser Herausforderung mit einem zweistufigen Ansatz: Eine tieflernende Komponente sorgt für allgemein gültige und verallgemeinerte Ersatzempfehlungen, während eine separate „Engagement“-Modellkomponente sich auf häufig nachgefragte Artikel spezialisiert und die Akzeptanz historisch bewerteter Ersatzoptionen nutzt. Dieses Zusammenspiel schafft eine ausgeglichene Empfehlungspalette, die sowohl bei bekannten als auch unbekannten Produkten hohe Kundenzufriedenheit erzielt. Ein weiterer entscheidender Fortschritt ist die Berücksichtigung der jeweiligen Händlerstruktur. Instacart stellt fest, dass ein globales Ersatzmodell für alle Partnerhändler oft suboptimale Ersatzvorschläge liefert. Unterschiedliche Einzelhändler führen eigene Sortimente und haben zum Teil exklusive Marken oder Preise.
Wenn das System nur auf allgemeine Produktschlüssel setzt, fehlen wichtige individuelle Händlerinformationen. Instacart hat das Modell daher erweitert und berücksichtigt nun neben dem Quell- und Ersatzprodukt auch den jeweiligen Händler. Diese Händlerspezifität verbessert nicht nur die Treffgenauigkeit der Ersatzempfehlungen, sondern verhindert auch teure oder unpassende Vorschläge, die Kunden irritieren könnten. So werden etwa bevorzugt Ladenmarken als Ersatz vorgeschlagen, wenn sie verfügbar sind und preislich fair bleiben. Neben der Modellarchitektur und der Datenbasis ist die fortlaufende Evaluation ein Kernstück des Systems.
Instacart bewertet seine Ersatzvorschläge sowohl offline mit statistischen Kennzahlen wie Log-Loss, AUC und Recall als auch online während A/B-Tests. Hier werden Faktoren wie Ersatzakzeptanzrate und Kundenzufriedenheit überwacht, um die Effektivität realitätsnah zu messen und kontinuierlich zu verbessern. Die Menge an Ersatzempfehlungen, die tatsächlich durch Shopper im Laden ausgewählt und vom Kunden akzeptiert werden, ist ein weiterer maßgeblicher Indikator. Die Implementierung dieser komplexen, aber effizienten Machine-Learning-Lösung bei Instacart bietet allen Beteiligten Vorteile. Für Kunden bedeutet dies weniger Frustration und mehr Vertrauen in die Plattform, da ausverkaufte Produkte schnell und zuverlässig durch vergleichbare Alternativen ersetzt werden.
Die Shopper profitieren von klaren Empfehlungen, die ihnen bei der Suche vor Ort Zeit sparen und Fehlkäufe durch unpassende Ersatzprodukte vermeiden helfen. Nicht zuletzt profitiert auch der Handelspartner, da verbindlichere und zufriedenstellendere Bestellungen die Kundenbindung stärken. Die Zukunft dieser Technologie bei Instacart sieht vielversprechend aus. Geplante Erweiterungen umfassen die Integration bildbasierter Daten aus Produktfotografien, um semantische Ähnlichkeit noch besser erfassen zu können. Ebenso sollen individuelle Kundenpräferenzen und situative Einkaufsumstände stärker berücksichtigt werden, etwa durch personalisierte Modelle, die das Einkaufsverhalten einzelner Nutzer oder ganzer Einkaufswagen analysieren.
Auch die Entwicklung eines einheitlichen Modells, das das Engagement der Nutzer und die tiefenstufigen Lernarchitekturen kombiniert, steht auf der Agenda. Diese Verfeinerungen könnten den Ersatzprozess noch weiter optimieren und die Online-Grocery-Erfahrung nahtlos und intelligent gestalten. Insgesamt zeigt Instacart, wie maschinelles Lernen und datengetriebene Innovationen im E-Commerce nicht nur die technischen Grenzen verschieben, sondern vor allem das Einkaufserlebnis von Millionen Kunden weltweit verbessern können. Der Einsatz von KI zur Problemlösung bei Produktersatz ist ein Paradebeispiel dafür, wie Technik und Kundennutzen synergistisch zusammenwirken können.