In den letzten Jahren hat die künstliche Intelligenz (KI) enorme Fortschritte gemacht, insbesondere im Bereich der natürlichen Sprachverarbeitung (NLP). Um die Leistungsfähigkeit von Sprachmodellen zu steigern, spielen effizientere Algorithmen und optimierte Speicherstrukturen eine entscheidende Rolle. Während Modelle wie GPT, BERT und nun auch spezialisierte Implementierungen wie Llama.cpp immer größere Aufgaben bewältigen, stellt der hohe Speicherbedarf eine der größten Herausforderungen dar. Ein zentraler Faktor, der in diesem Kontext häufig diskutiert wird, ist der Einsatz von Attention-Mechanismen – insbesondere die Lösung durch Sliding Window Attention, die jetzt für Gemma 3 vorgestellt und umgesetzt wird.
Llama.cpp ist eine Open-Source-Implementierung, die sich durch ihre Effizienz und Flexibilität auszeichnet. Sie wurde entwickelt, um große Sprachmodelle auf breiten Plattformen lauffähig zu machen, einschließlich Ressourcen-limitierter Umgebungen. Mit der Integration der Sliding Window Attention wird der Speicherverbrauch signifikant reduziert, ohne dabei die Modellgenauigkeit und Leistung zu beeinträchtigen. Diese Methode erlaubt es, langanhaltende Abhängigkeiten und Kontextinformationen auf intelligente Weise zu verarbeiten, ohne dass der gesamte Kontext auf einmal gespeichert werden muss.
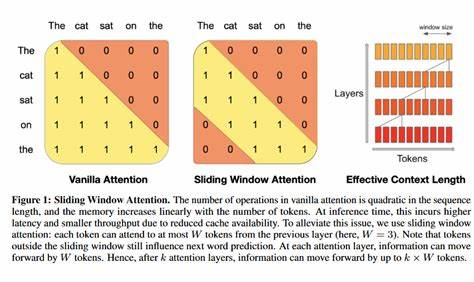
Das Grundproblem bei traditionellen Attention-Mechanismen liegt in ihrer Speicherkomplexität, die quadratisch mit der Länge der Eingabesequenz wächst. Das bedeutet, dass längere Texte oder größere Datenmengen exponentiell mehr Arbeitsspeicher benötigen. Für Anwendungen, die auf mobilen Geräten oder kleineren Servern laufen müssen, stellt dies eine erhebliche Einschränkung dar. Gemma 3, eine spezialisierte Plattform, die für effiziente KI-Berechnung entwickelt wurde, profitiert enorm von Speicherreduzierungen, um mehr Modellkapazität auf weniger Hardware zu realisieren. Sliding Window Attention löst dieses Problem, indem sie den Kontext nicht global, sondern lokal betrachtet.
Statt alle Positionen eines Textes gleichzeitig zu analysieren, fokussiert sie jeweils auf ein Fenster einer definierten Größe, das über die Sequenz gleitet. Durch diesen Ansatz verringert sich die Komplexität auf eine lineare Abhängigkeit zur Eingabelänge. Dadurch wird der Speicherbedarf erheblich reduziert und die Verarbeitungsgeschwindigkeit verbessert. Gleichzeitig ermöglicht die Methode, weiterhin relevante Kontextinformationen eines Textes zu erfassen, da sich die Fenster überlappen und zusätzliche Mechanismen zur Verknüpfung der einzelnen Segmente eingesetzt werden. Innerhalb von Llama.
cpp wurde Sliding Window Attention so implementiert, dass sie die spezifischen Anforderungen von Gemma 3 erfüllt. Die Optimierung berücksichtigt sowohl die Hardwarearchitektur als auch die programmatische Effizienz, sodass die Speicherallokation besser verteilt und Zugriffe minimiert werden. Dies führt nicht nur zu geringeren Latenzzeiten, sondern auch zu einer gesteigerten Skalierbarkeit bei variierenden Datenmengen. Entwickler und Forscher profitieren somit von einer stabileren Plattform, die sowohl hohe Rechenleistung als auch niedrigen Speicherverbrauch bietet. Ein weiterer Vorteil der Kombination von Llama.
cpp mit Sliding Window Attention besteht darin, dass es die Tür zu Echtzeitanwendungen öffnet. Sprachmodelle können schneller auf Eingaben reagieren, was das Nutzererlebnis in Chatbots, Übersetzungssoftware und interaktiven Assistenten deutlich verbessert. In einer Welt, die ständig nach schnelleren und effizienteren Lösungen verlangt, stellt diese Entwicklung einen bedeutenden Fortschritt dar. Die Speicherung und Verarbeitung großer Modelle für gemischte Anwendungsbereiche war lange Zeit ein Hindernis für die breite Adoption von KI-Technologien. Mit der neuen Methode zeigt sich, dass innovative Ansätze wie Sliding Window Attention nicht nur theoretische Vorteile bringen, sondern direkt in der Praxis überzeugen.
Somit wird die Anwendung moderner Sprachmodelle in Bereichen wie Medizintechnik, Bildung oder automatisierter Kundenbetreuung deutlich realistischer und zugänglicher. Die Entwicklung in Llama.cpp passt sich den ständig wachsenden Anforderungen an KI und maschinellem Lernen an. Durch kontinuierliche Forschung und Implementation von Techniken wie Sliding Window Attention können Entwickler kosteneffizient und ressourcenschonend leistungsstarke Lösungen schaffen. Dies ist vor allem für Regionen und Industrien wichtig, die nicht über die größte Hardwareinfrastruktur verfügen.
Gemma 3 profitiert dabei von der Kombination aus Hard- und Softwareoptimierung, die genau auf die Bedürfnisse moderner KI-Modelle zugeschnitten ist. Die Effektivität der Sliding Window Attention zeigt sich auch in seiner verbesserten Energieeffizienz, wodurch das Gesamtökosystem nachhaltiger wird und ökologische Auswirkungen minimiert werden. Für Unternehmen und Organisationen, die zunehmend auf KI setzen, sind diese Fortschritte ein großer Vorteil. Zusätzlich zur Speicherersparnis ermöglicht Sliding Window Attention in Llama.cpp eine flexiblere Handhabung von Eingaben.
Die Fenstergröße kann dynamisch angepasst werden, um auf unterschiedliche Textlängen und Anwendungsprofile zu reagieren. Dadurch lässt sich das Modell individuell auf spezifische Einsatzgebiete zuschneiden, was die Anpassungsfähigkeit und Performance weiter steigert. Insbesondere in der Forschung eröffnet diese Flexibilität neue Möglichkeiten, um Sprachmodelle besser auf verschiedene Domänen zu trainieren und anzuwenden. Die Kombination aus anpassbarer Ressourcenverwaltung, reduziertem Speicherbedarf und verbesserter Verarbeitungsgeschwindigkeit macht Llama.cpp mit Sliding Window Attention zu einer idealen Lösung für moderne KI-Anwendungen auf Gemma 3.
Entwickler erhalten damit ein mächtiges Werkzeug, um komplexe Sprachmodelle auch in ressourcenbegrenzten Umgebungen effizient einzusetzen und die Vorteile neuster KI-Technologien zu nutzen. Schlussendlich verdeutlicht die Umsetzung der Sliding Window Attention in Llama.cpp den Paradigmenwechsel in der KI-Entwicklung: Weg von immer größeren und schwerfälligen Modellen hin zu intelligenten, skalierbaren und ressourcenschonenden Lösungen. Für die Zukunft verspricht diese Technik eine neue Generation von Anwendungen, die schneller, präziser und zugänglicher sind als je zuvor. Gemma 3 als Plattform profitiert dadurch nicht nur in der Leistung, sondern auch in der Nachhaltigkeit und Wirtschaftlichkeit.
Entwickler, Forscher und Anwender sollten daher die Möglichkeiten von Llama.cpp und der Sliding Window Attention für Gemma 3 genau im Blick behalten. Es handelt sich um eine Innovation, die das Potenzial hat, den Einsatz von KI in zahlreichen Branchen grundlegend zu verändern und auf eine neue Ebene zu heben. Die Reduktion der Speicheranforderungen ist dabei nur der erste Schritt einer vielversprechenden Entwicklung in der KI-Welt.