Endliche Zustandsautomaten (Finite State Machines, FSM) sind ein bewährtes Modell der Berechnung, das in vielen Bereichen Anwendung findet. Besonders in der Umsetzung komplexer Geschäftslogik bieten FSMs eine klare und strukturierte Herangehensweise, um Geschäftsprozesse nachvollziehbar und sicher zu gestalten. Ein herausragendes Einsatzgebiet für FSMs stellt das Order-Management in Unternehmen dar. Dort ergeben sich Anforderungen, die ohne ein klares Modell leicht zu Fehlern oder unerwünschtem Verhalten führen können. Beispielsweise müssen Bestellungen nicht vor der Zahlung versandt werden, sie können nur dann storniert werden, wenn noch kein Versand erfolgt ist, und außerdem erfordern bezahlte aber stornierte Bestellungen eine Rückerstattung.
Das Abbilden dieser Vorgaben in klassische Datenbanklogik kann schnell komplex und fehleranfällig werden. Hier ermöglicht die FSM-Implementierung in PostgreSQL eine elegante Lösung, die Geschäftslogik nicht nur robust abbildet, sondern auch die Analyse und Performance steigert. Grundsätzlich basiert ein FSM auf der Definition von Zuständen, Ereignissen sowie Übergangsregeln, die den Wechsel von einem Zustand in einen anderen bei bestimmten Ereignissen erlauben. In einem Bestellprozess könnte der Anfangszustand beispielsweise „start“ sein, gefolgt von Zuständen wie „awaiting_payment“ (wartend auf Zahlung), „awaiting_shipment“ (wartend auf Versand), „shipped“ (versandt), „canceled“ (storniert) und „awaiting_refund“ (wartend auf Rückerstattung). Ereignisse wie „create“, „pay“, „cancel“, „ship“ und „refund“ lösen diese Übergänge aus.
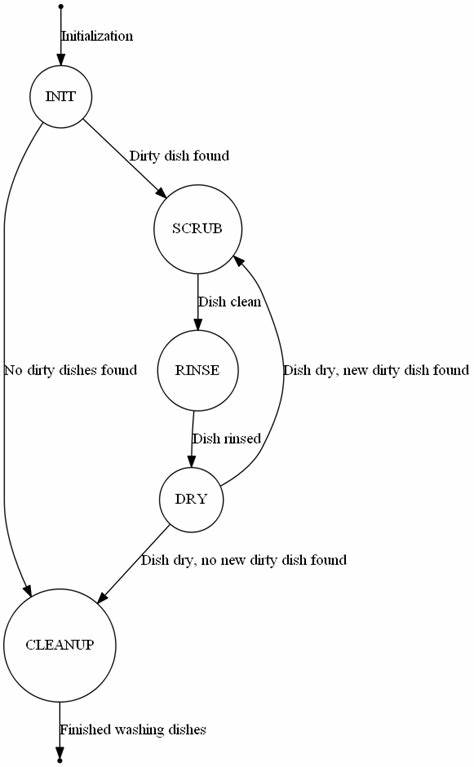
Wenn ein Ereignis in einem Zustand nicht erlaubt ist, führt dies zu einem Fehlerzustand. Die übersichtliche Visualisierung eines FSM erfolgt meist durch gerichtete Graphen, in denen die Zustände als Knoten fungieren und die Übergänge durch Ereignisse als gerichtete Kanten dargestellt werden. Diese Darstellung fördert das gemeinsame Verständnis zwischen technischen Teams und den Fachabteilungen und verhindert Mehrdeutigkeiten in der Umsetzung. Zudem können so sofortige Einsichten gewonnen werden, zum Beispiel dass eine Rückgabe nach Versand ausgeschlossen ist, was für Kundenkommunikation und Prozessgestaltung essenziell ist. Im Kontext von PostgreSQL wird diese Logik direkt in der Datenbank verankert.
Das ist einerseits unüblich, da Geschäftslogik häufig in der Anwendungsschicht bleibt, andererseits eröffnet diese Methode wichtige Vorteile im Hinblick auf Konsistenz, Performance und Analysefreundlichkeit. Ein wesentlicher Baustein hierfür ist eine Tabelle, die alle Ereignisse zu einer Bestellung festhält. In der Praxis wird dafür eine Tabelle namens „order_events“ mit den Spalten für eindeutige IDs, Order-IDs, Ereignisbezeichnungen und Zeitstempeln angelegt. Hier fließen alle relevanten Aktionen ein, um den Status eines Auftrags im zeitlichen Verlauf abzubilden. Im Anschluss steht die Implementierung der Übergangsfunktion im Vordergrund.
Diese nimmt einen aktuellen Zustand und ein Ereignis entgegen und liefert den neuen Zustand zurück. Ein Beispiel in PostgreSQL zeigt, wie dies mit SQL CASE-Statements in einer Funktion gemanagt wird. Die Funktion definiert klare Regeln für jeden Zustand, welche Ereignisse gültig sind und zu welchem Folgezustand sie führen. Ein nicht erlaubtes Ereignis bewirkt die Rückgabe eines sogenannten Fehlerzustands, der später für Validierung und Fehlerbehandlung ausschlaggebend ist. Es ist sinnvoll, diese Funktion zunächst zu testen, um sicherzustellen, dass alle Erwartungshaltungen erfüllt werden.
Beispielsweise lassen sich alle erlaubten Übergänge mit Beispielzuständen und Ereignissen abfragen. Das liefert wertvolles Feedback, bevor die Logik in den produktiven Betrieb geht. Eine große Herausforderung besteht darin, eine Reihe von Ereignissen sequenziell auf einen Zustand anzuwenden, um den aktuellen Status einer Bestellung bestimmen zu können. Im klassischen SQL fehlen hierfür häufig geeignete Mittel, weshalb eine Aggregatfunktion zur Anwendung kommt. PostgreSQL erlaubt die Definition benutzerdefinierter Aggregate, die eine interne Zustandsvariable führen und für jeden Datensatz eine Übergangsfunktion aufrufen.
Mit einem initialen Zustand beginnend lässt sich so nacheinander jeder Event verarbeitet und der finale Zustand ermitteln. Diese Idee passt ideal zu FSMs und sorgt für effiziente und übersichtliche Abfragen. Die praktische Umsetzung sieht vor, die Übergangsfunktion als State-Transition-Funktion (SFUNC) zu definieren und eine Aggregate namens „order_events_fsm“ zu deklarieren, die diese übernimmt. Dabei ist zu beachten, dass das Startkriterium für Zustände mit „start“ beginnt. Wird nun in einer Bestellung die Kette aller Ereignisse aggregiert, erhält man exakt den aktuellen Zustand – oder eben einen Fehlerzustand, falls eine ungültige Ereignisfolge eingetreten ist.
Um die Datenintegrität sicherzustellen, wird empfohlen, diese Aggregate-Berechnung als Triggerfunktion zu verwenden, die vor dem Einfügen neuer Ereignisse ausgelöst wird. Diese Triggerfunktion wertet die bisher vorhandenen Ereignisse der betreffenden Bestellung plus das neue Ereignis aus und berechnet den daraus resultierenden Zustand. Führt das zu einem Fehlerzustand, so wird eine Ausnahme ausgelöst, die das Einfügen verhindert. Diese Herangehensweise schützt vor inkonsistenten Zustandsübergängen bereits auf Datenbankebene und vermeidet somit potenzielle Fehler und Race-Conditions. Bei der Anwendung dieser Technik werden sowohl valide als auch invalide Ereignisfolgen erfolgreich erkannt.
So kann man beispielhaft sehen, dass eine Bestellung mit den Ereignissen „create“, „pay“, „ship“ erfolgreich bearbeitet wird, während der Versuch, direkt von „create“ auf „ship“ zu springen, wegen fehlender Zahlung fehlschlägt. Dies illustriert anschaulich den Mehrwert der FSM-Strategie in der Datenbank. Ein weiterer bemerkenswerter Vorteil besteht in den erweiterten Analyse-Möglichkeiten. Die Datenbank hält nicht nur valide Zustandsübergänge sicher fest, sondern erlaubt auch detaillierte Auswertungen über Verlaufszeitpunkte und Statusverteilungen. Mit Beispieldaten von mehreren Bestellungen und Zeitstempeln lassen sich so Verlaufshistorien einzelner Aufträge über zeitliche Fenster nachvollziehen.
Dabei bietet sich die FSM-Aggregatfunktion auch als Window-Function an, um schrittweise Zustände zu einzelnen Events darzustellen. Dies erleichtert tiefgreifende Einsichten in das Verhalten von Kunden oder Prozessen. Die Vorteile reichen noch weiter: Beispielsweise erlaubt die Kombination von zeitlichen Serien und lateral join-Abfragen die Analyse von Zustandsverteilungen auf Tagesbasis über alle Bestellungen hinweg. So kann man sehen, wie viele Aufträge an einem bestimmten Tag sich im Zustand „awaiting_payment“, „canceled“ oder „shipped“ befanden. Diese Arten von Echtzeit-Analysen sind sehr wertvoll für Dashboards und operative Entscheidungen.
Natürlich hat das Verlegen von Geschäftslogik in eine Datenbank auch seine Herausforderungen. Es erfordert ein Umdenken hin zu einer datenbankzentrierten Architektur und den Umgang mit möglichen Nebenwirkungen wie Skalierbarkeit, Wartbarkeit und Komplexität. Gerade in sehr großen Systemen mit massiven Ereignisströmen sind zusätzliche Maßnahmen wie Materialisierung, Partitionierung oder höhere Isolationstufen notwendig, um gleichzeitig Performance und Datenintegrität zu gewährleisten. Dennoch hat dieser Ansatz bereits in Großprojekten seine Praxistauglichkeit bewiesen. Techniken zur Vermeidung von Concurrency-Anomalien, etwa durch die Nutzung des SERIALIZABLE Isolationslevels oder durch gezielte Sperren, können die Zuverlässigkeit weiter erhöhen.
Die Kombination mit PostgreSQLs leistungsfähigen Features für Indizes, Trigger und erweiterbare Datentypen macht das Datenbankmanagementsystem zu einer idealen Plattform für FSMs. Abschließend lässt sich sagen, dass die Implementierung endlicher Zustandsautomaten in PostgreSQL eine mächtige Methode ist, um komplexe Geschäftsprozesse transparent, sicher und effizient abzubilden. Sie bringt nicht nur eine klare Struktur in die Abläufe, sondern ermöglicht auch erweiterte Analysen und verbessert die Gesamtqualität der Daten. Für Unternehmen, die großen Wert auf Datenintegrität und Echtzeit-Insights legen, stellt dieser Ansatz eine äußerst attraktive Alternative zu klassischen Anwendungsschichten dar. Wer sich für moderne Datenbankarchitekturen interessiert und neue Wege in der Geschäftslogik-Implementation sucht, findet in der FSM-Implementierung mit PostgreSQL eine innovative und bewährte Lösung, die nachhaltige Vorteile bietet.
Die Kombination aus einfacher Modellierbarkeit, eingebauter Validierung und fortschrittlichen Analysefunktionen macht sie zu einem spannenden Werkzeug im Arsenal moderner Datenbankentwickler und Business-Analysten.



![Rapid accumulation of [trash] on most pristine islands (2017)](/images/40E19B40-BE91-4745-9680-483B3FA5B9A1)