Das Voynich-Manuskript zählt seit Jahrhunderten zu den faszinierendsten ungelösten Rätseln der Welt. Dieses mysteriöse mittelalterliche Dokument, dessen Inhalt weder entschlüsselt noch verstanden wurde, stellt Forscher, Kryptographen und Sprachwissenschaftler gleichermaßen vor große Herausforderungen. Die einzigartige Beschaffenheit der Schrift, der unverständliche Text und die rätselhaften Illustrationen haben zahlreiche Theorien entstehen lassen. Von einer natürlichen, aber unbekannten Sprache über eine künstliche oder verschlüsselte Botschaft bis hin zu einem wissentlich erstellten Schwindel – die Bandbreite der Annahmen ist enorm. In jüngster Zeit hat die Anwendung moderner Techniken des Natural Language Processing (NLP) die Untersuchung des Voynich-Manuskripts revolutioniert.
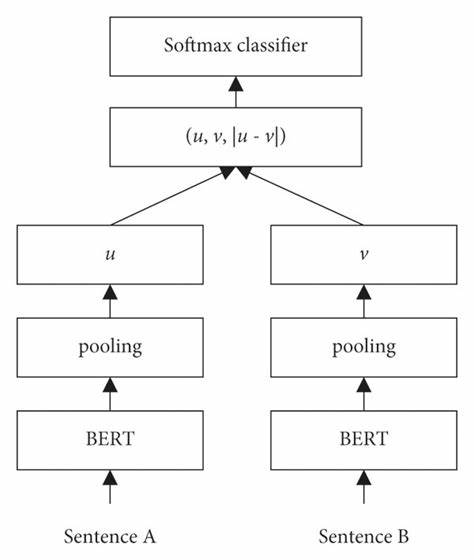
Insbesondere die Einbindung von SBERT (Sentence-BERT), eine fortschrittliche Methode der Sprachmodellierung, bietet faszinierende Möglichkeiten, Muster und Strukturen aufzudecken, ohne dabei auf spekulative Übersetzungen zurückzugreifen. Im Kern verfolgt dieser Ansatz die Frage, ob das Manuskript trotz seiner Unverständlichkeit echte, sprachähnliche Eigenschaften besitzt oder ob es sich lediglich um zufällige oder absichtlich verschleierte Zeichenfolgen handelt. Die Anwendung von SBERT ermöglicht eine semantische Einbettung der Worte im Text, sodass deren Beziehungen zueinander mathematisch erfasst und analysiert werden können. Durch das Clustern dieser Einbettungen lassen sich Muster erkennen, die auf wiederkehrende Wortstämme, Satzstrukturen oder grammatikalische Muster hinweisen könnten. Ein entscheidender Schritt in der Verarbeitung des Manuskripts war die Vorverarbeitung der Wörter.
Dabei wurden wiederkehrende Suffixe, also Endungen wie 'aiin', 'dy' oder 'chy', systematisch entfernt. Dieser Prozess dient dazu, vermeintliche Wortstämme freizulegen und sprachliche Variationen, die durch grammatikalische oder phonologische Anhängsel entstehen, auszublenden. Diese Maßnahme ist nicht unumstritten, da sie einerseits die Klarheit der Clusterbildung erleichtert, andererseits aber auch potenzielle morphologische Informationen verlieren könnte. Dennoch konnte mit dieser Methodik eine verbesserte Gruppierung ähnlicher Wortformen erzielt werden, was wichtige strukturelle Hinweise lieferten. Das Ergebnis der SBERT-basierten Analyse zeigt, dass das Voynich-Manuskript klare Strukturen aufweist.
Die Cluster weisen unterschiedliche Charakteristika auf: Einige Gruppen enthalten häufig verwendete Wörter mit geringer Variabilität, die sich oft am Anfang von Zeilen finden lassen. Dies erinnert an Funktionswörter in natürlichen Sprachen, wie z.B. Artikel oder Präpositionen. Andere Cluster zeigen eine hohe Diversität und flexible Positionierung im Text, was auf Inhaltswörter oder Wurzeln hinweisen könnte.
Zusätzlich wurde eine Markov-Ketten-Analyse durchgeführt, die Übergangsregeln zwischen den Wortclusterfolgen im Manuskript untersucht. Dabei bestätigte sich, dass die Wortfolgen keineswegs zufällig sind, sondern klare Übergangswahrscheinlichkeiten besitzen, die auf eine interne Grammatik oder Syntax hindeuten. Besonders interessant ist die Beobachtung, dass verschiedene Manuskriptabschnitte – wie botanische, biologische oder astronomische Kapitel – unterschiedliche Muster in der Nutzung und Positionierung der Wortcluster aufweisen. Dies legt nahe, dass das Manuskript nicht nur strukturell konsistent, sondern auch thematisch differenziert aufgebaut ist. Die Kombination aus SBERT-Clustering, morphologischer Vorverarbeitung und Übergangsmodellierung eröffnet somit eine neue Sicht auf das Voynich-Manuskript.
Es stützt die Hypothese, dass trotz der fehlenden Übersetzung eine konstruierte oder mnemonische Sprache vorliegt, die sich durch eine systematische Syntax und einen Unterschied zwischen Funktions- und Inhaltsworten auszeichnet. Diese Annahme widerspricht der Vorstellung, dass der Text reine Zufallsfolge oder ein historischer Scherz sei. Stattdessen sprechen die gesammelten Beweise für eine komplexe, regelbasierte Kodierung, die anhand moderner linguistischer Werkzeuge untersucht werden kann. Die offene Natur dieser Forschungsarbeit – frei zugänglicher Code, transparente Methodik und die Möglichkeit zur Reproduktion der Ergebnisse – animiert Wissenschaftler aus den Bereichen Kryptoanalyse, Linguistik und Informatik zur Mitarbeit. Die Herausforderung liegt weiterhin darin, den Code hinter dieser Struktur zu entschlüsseln.
Doch selbst ohne eine direkte Übersetzung beweisen die Analysen, dass das Manuskript erhebliches sprachliches Potenzial besitzt. Zudem eröffnet der Einsatz von nichtlinearen Dimensionsreduktionen wie UMAP oder PaCMAP zusätzliche Wege, um die Daten in neue Formen der Visualisierung und Interpretation zu überführen. Die Zukunft der Voynich-Forschung ist damit nicht mehr ausschließlich eine Suche nach einer abschließenden Entschlüsselung, sondern ein interdisziplinäres Feld, in dem moderne Algorithmen helfen, Muster zu entdecken, die menschlichem Auge und traditionellen Analyseansätzen verborgen bleiben. Die vorgestellte Methode ist ein Beispiel dafür, wie Künstliche Intelligenz sinnvoll eingesetzt werden kann, um jahrhundertealte Geheimnisse zu beleuchten. Für interessierte Forscher bietet das Projekt eine solide Basis, um alternative Hypothesen zu testen, weitere linguistische Modelle anzuwenden und die Balancen zwischen systematischer Datenanalyse und historischer Kontextualisierung zu erkunden.
Zusammenfassend lassen sich mit SBERT und den begleitenden linguistischen Verfahren wertvolle Einsichten in die Struktur des Voynich-Manuskripts gewinnen. Es handelt sich um ein komplexes sprachähnliches System mit differenzierten Wortklassen und klarer interner Organisation. Die Analyse zeigt, dass moderne NLP-Ansätze weit über reine Übersetzungsversuche hinaus gehen und stattdessen auf das Erkennen von Sprachmustern und struktureller Kohärenz setzen. Diese Entwicklung könnte nicht nur das Verständnis des Voynich-Manuskripts vertiefen, sondern auch neue Perspektiven für die Untersuchung anderer unentschlüsselter Texte eröffnen.