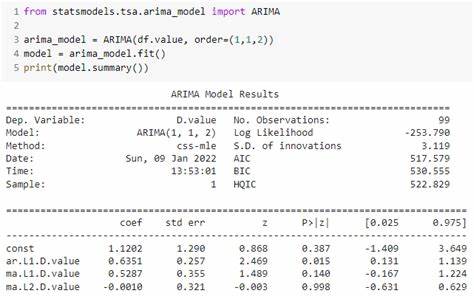
Die Arbeit mit Zeitreihenmodellen ist in vielen wissenschaftlichen und wirtschaftlichen Bereichen unverzichtbar geworden. Vor allem ARIMA-Modelle (Autoregressive Integrated Moving Average) haben sich seit Jahrzehnten als zuverlässiger Standard für Prognosen und Zeitreihenanalysen bewährt. In der Python-Welt bieten diverse Bibliotheken die Möglichkeit, ARIMA-Modelle zu implementieren und zu nutzen. Doch eine Frage beschäftigt viele Anwender: Sind all diese Pakete eigenständige Lösungen oder verbergen sie letztlich alle die bewährte statsmodels-Bibliothek unter der Haube?Die Antwort darauf ist keineswegs trivial, da das Python-Ökosystem für Zeitreihenanalyse eine Vielzahl an Optionen bereithält, die teilweise direkt auf statsmodels aufbauen oder diese sogar nur umhüllen. Statsmodels gilt als das Original für die schlichte und robuste Implementierung von ARIMA-Modellen und stellt seit vielen Jahren das Fundament der Zeitreihenanalyse in Python dar.
Mit Unterstützung für klassische (p,d,q) ARIMA-Modelle, saisonale Komponenten (P,D,Q) sowie die Einbeziehung exogener Variablen punktet statsmodels durch seine direkte Code-Basis, effiziente Berechnung mittels Cython sowie weitreichende diagnostische Werkzeuge.Versteht man die Bedeutung von statsmodels als Grundpfeiler, so eröffnet sich ein klareres Bild für die anderen Zeitreihenbibliotheken im Python-Universum. Beispielsweise bietet sktime eine vereinheitlichte API für maschinelles Lernen und künstliche Intelligenz mit Zeitreihen an. Doch bei genauerem Hinsehen zeigt sich, dass sktime diverse ARIMA-Funktionalitäten über Wrapper realisiert, die entweder direkt auf statsmodels oder auf pmdarima setzen. Letzteres wiederum ist selbst ein Wrapper, der statsmodels als interne Rechenbasis verwendet, allerdings ein schlankeres und an scikit-learn erinnerndes Interface bietet.
Durch diese Architektur legt sktime den Fokus auf Interoperabilität und Flexibilität innerhalb unterschiedlicher Zeitreihenansätze.Ein weiteres populäres Python-Paket, pmdarima, punktet mit der Fähigkeit, automatisch geeignete ARIMA-Parameter zu bestimmen. Trotz dieser erweiterten Funktionalität bleibt auch hier statsmodels der Kernmotor für die Modellschätzung. Pmdarima erleichtert durch seine Automatisierung insbesondere den Weg für Nutzer, die schnelle und unkomplizierte Modellierung anstreben, ohne tief in mathematische Details einzusteigen. Das macht es attraktiv für Anwender mit Fokus auf Effizienz und Nutzerfreundlichkeit.
Darts, eine weitere vielzitierte Bibliothek, stellt sich als anwenderfreundliche Lösung für das Zeitreihen-Forecasting dar und enthält sowohl eine ARIMA-Klasse als auch eine AutoARIMA-Implementierung. Die klassische ARIMA-Variante basiert wiederum auf statsmodels. Interessanterweise nutzt die autoARIMA-Funktion von Darts jedoch die statsforecast-Bibliothek, die sich durch eine eigenständige, in C++ implementierte ARIMA-Kernfunktion auszeichnet. Diese Besonderheit macht statsforecast besonders für Anwender attraktiv, die neben Python auch von der Performance einer performant kompilierten C++-Bibliothek profitieren möchten.Die statsforecast-Bibliothek ist tatsächlich die einzige in dieser Übersicht, die eine eigenständige ARIMA-Implementierung mit nativer C++-Unterstützung mitbringt.
Durch die native Implementierung erreicht sie deutlich höhere Geschwindigkeiten und ist laut Angaben der Entwickler etwa viermal schneller als statsmodels. Dies ist insbesondere in Szenarien relevant, in denen zahlreiche ARIMA-Modelle wiederholt trainiert und ausgewertet werden müssen, etwa in großen Unternehmensumgebungen oder bei komplexen maschinellen Lernpipelines. Dennoch bleibt auch hier ein kleiner Rückgriff auf statsmodels bestehen: Für die Behandlung exogener Regressoren nutzt statsforecast die Ordinary Least Squares-Funktionalität von statsmodels. So zeigt sich, dass gänzlich eigenständige Implementierungen im Python-Zeitreihenbereich nach wie vor bestimmte bewährte Werkzeuge ergänzend einsetzen.Autogluon schließlich hat sich zum Ziel gesetzt, automatisiertes Zeitreihen-Forecasting einfach zugänglich zu machen.
In seiner aktuellen Version verzichtet es auf direkte Abhängigkeiten von statsmodels und setzt in seinen ARIMA-Modellen stattdessen auf die statsforecast-Bibliothek. Dieses Vorgehen ist ein Beispiel für die zunehmende Bedeutung schneller und eigenständiger Kernimplementierungen im Zeitreihenbereich, die alte Abhängigkeiten Stück für Stück ablösen.Der Vergleich zwischen statsmodels und statsforecast offenbart zwei grundsätzlich verschiedene Strategien im Umgang mit ARIMA-Modellen. Während statsmodels die klassische, gut dokumentierte und breit akzeptierte Lösung darstellt, punktet statsforecast mit Geschwindigkeit und moderner Technik. Für Entwickler und Analysten ist es wichtig, diese Unterschiede zu kennen und je nach Anwendungsfall abzuwägen, ob ihnen Stabilität, Nachvollziehbarkeit und Kompatibilität wichtiger sind oder ob sie für massive Berechnungsaufgaben moderne Performancevorteile nutzen wollen.
Der wichtigste Erkenntnisgewinn liegt aber darin, dass Python-Zeitreihenpakete selten komplett „aus sich heraus“ funktionieren. Stattdessen entstehen häufig Schichten von Abstraktion, die in der Fachwelt als Wrapper bekannt sind, dabei auf das solide Fundament von statsmodels als Rechenwerk zurückgreifen. Für Anwender bedeutet das: Bevor man sich für eine Bibliothek entscheidet, sollte man verstehen, wie tief diese Integration geht und welche Mehrwerte das eigene Werkzeug gegenüber statsmodels tatsächlich bietet. Die meisten Pakete sind zwar transparent in ihren Abhängigkeiten, doch die Dokumentation oder Marketingaussagen lassen nicht sofort erkennen, ob man es mit nativen Implementierungen oder nur mit neu verpackten statsmodels-Aufrufen zu tun hat.Ein kurzes Studium der Quellcodes oder ein Blick auf die Importpfade kann daher viel Klarheit schaffen.
Manchmal ist es aus Gründen der Performance oder Wartbarkeit durchaus sinnvoll, direkt mit statsmodels zu arbeiten und zusätzliche Wrapper zu meiden. In anderen Fällen bieten die Wrapper zusätzliche Automatisierung, vereinfachte Schnittstellen oder harmonisierte APIs, die für das eigene Projekt wertvollen Zeitgewinn bedeuten können.Abschließend lässt sich sagen, dass in der Python-Welt der Mythos, dass ARIMA-Modelle vielfältig und unabhängig implementiert werden, so nicht ganz stimmt. Statsmodels bleibt zentrale Instanz, ob als direkte Bibliothek oder als Kernmotor hinter anderen Tools. Die wenigen Ausnahmen, die wie statsforecast auf native Umsetzung setzen, markieren den Fortschritt zu schneller und eigenständiger Modellierung.
Wer mit ARIMA-Modellen in Python arbeitet, sollte also seinen Werkzeugkasten genau kennen, um die passende Lösung für Anforderungen von Stabilität, Benutzerfreundlichkeit und Geschwindigkeit zu finden.