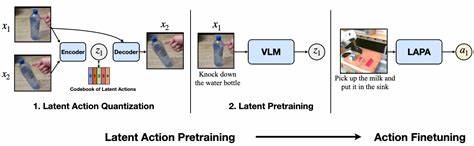
Die Entwicklung von KI-Compilern steht im Zentrum der modernen künstlichen Intelligenz, da sie den Weg für effizientere Modelle und bessere Hardware-Nutzung ebnet. In den letzten Jahren haben sich insbesondere zwei Frameworks hervorgetan: MLIR (Multi-Level Intermediate Representation) und TVM (Tensor Virtual Machine). Beide bieten durch ihre Architektur und Funktionen spannende Ansätze für Entwickler, insbesondere für jene mit einem Verständnis von LLVM, das als weit verbreitete Compiler-Infrastruktur eine wichtige Rolle spielt. Doch welches dieser beiden Frameworks ist populärer, besser geeignet für das Lernen und wo liegen die jeweiligen Stärken in der Praxis? Darüber hinaus stellt sich die Frage, welche Plattform mehr in der AI-Chip-Industrie genutzt wird und welche Lernressourcen sinnvoll sind, um fundiertes Wissen zu erlangen. MLIR wurde ursprünglich von Google entwickelt und ist faktisch eine Erweiterung der LLVM-Infrastruktur, die eine flexible und erweiterbare Abstraktionsschicht für verschiedene Repräsentationen innerhalb von Compilern bietet.
Hierbei werden verschiedene Abstraktionsebenen und Dialekte unterstützt, die eine nahtlose Kombination von hoch- bis niederniveaum Transformationsschritten ermöglichen. Gerade in der KI-Domäne erlaubt MLIR das Verarbeiten von Tensoroperationen über unterschiedliche Hardwarearchitekturen hinweg, was eine bessere Optimierung und Portabilität ermöglicht. Die Tatsache, dass MLIR eng mit LLVM verbunden ist, macht es besonders attraktiv für Entwickler, die bereits mit LLVM vertraut sind und ihr Wissen auf KI-bezogene Anwendungen übertragen möchten. Im Gegensatz dazu setzt TVM, eine Open-Source-Initiative, stärker auf End-to-End Optimierungen für Deep Learning Modelle. Es bietet umfangreiche Werkzeuge zur Beschreibung der Modellinetermediären Repräsentationen, die anschließende Optimierung und für das Zusammenführen der Codegenerierung, die auf eine Vielzahl von Hardwareplattformen zugeschnitten ist.
TVM zeichnet sich insbesondere durch seinen Fokus auf Acceleratoren und spezialisierte Hardware aus, wobei automatische Tuning-Mechanismen wie AutoTVM und AutoScheduler integriert sind, die für optimale Performance sorgen. Aufgrund dieser Optimierungen ist TVM oft die erste Wahl, wenn es um die Kompilierung und Ausführung von Deep Learning Workloads auf neuen AI-Chips oder eingebetteten Systemen geht. Bei der Frage der Popularität lässt sich beobachten, dass beide Frameworks in unterschiedlichen Communities hohe Beachtung genießen. MLIR gewinnt zunehmend an Bedeutung nicht nur wegen seiner Flexibilität, sondern auch durch die Integration in diverse große Projekte wie TensorFlow und PyTorch. Seine modulare Struktur erleichtert die Erweiterung auf neue Hardware und bietet eine solide Basis für Compilerentwicklung im KI-Bereich.
TVM wiederum verzeichnet hohe Popularität vor allem in der Forschung und bei Unternehmen, die sich auf die Optimierung von Trainings- und Inferenzmodellen konzentrieren, wie diverse AI-Chip-Hersteller und Cloud-Anbieter. Die aktive und lebendige Community von TVM entwickelt kontinuierlich neue Features und unterstützt zahlreiche Hardwarearchitekturen, was für viele Praktiker ein großer Vorteil ist. Für Einsteiger oder Entwickler mit LLVM-Erfahrung ist MLIR besonders attraktiv, weil die Konzepte und der Aufbau nahe an bekannten Compiler-Strukturen sind. Das Lernen von MLIR bietet langfristige Vorteile, da man sich mit einem Framework auseinandersetzt, das nicht nur im KI-Bereich, sondern generell in Compilerentwicklung Anwendung findet. Außerdem sind die vorhandenen Dokumentationen und Tutorials stetig in Entwicklung, wobei Google und die LLVM-Community kontinuierlich Ressourcen veröffentlichen.
Auf der anderen Seite ist TVM dank seines praxisbezogenen Fokus und der zahlreichen Workflows für Deep Learning Modelle ein hervorragender Einstieg, wenn das Ziel darin besteht, Performance-Optimierungen auf tatsächlichen Hardwareplattformen unmittelbar umzusetzen. Die recht aktive Community, inklusive vieler Foren und GitHub-Aktivitäten, erleichtert zudem die Kommunikation mit anderen Nutzern und die schnelle Lösung von Problemen. In der KI-Chip-Industrie setzen viele Unternehmen auf beide Frameworks, je nach Anwendungsfall. Viele Chiphersteller profitieren von TVM, um ihre Hardware für bekannte Deep Learning Modelle optimal zu unterstützen und Modelle auf ihre speziellen Beschleuniger zu übertragen. Der Einsatz von TVM bietet ihnen meist eine schnellere Markteinführung und verbesserte Performance, besonders bei Embedded-Systemen oder neuen AI-Beschleunigern.
Parallel dazu nutzt ein wachsender Kreis von Firmen MLIR als Grundlage, insbesondere bei komplexen Compilerprojekten, die sich nicht ausschließlich auf Deep Learning beschränken, sondern auch andere compute-intensive Anwendungen umfassen. Google selbst verwendet MLIR intensiv für TensorFlow, was die relevanten Industrienachfrage weiter befeuert. Wer sich für das Lernen von MLIR entscheidet, findet derzeit mehrere zentrale Ressourcen hilfreich. Die offizielle LLVM-Projektseite bietet eine Einführung in MLIR sowie umfassende Dokumentationen zur Architektur und Programmierung. Zusätzlich existieren verschiedene Tutorials und Workshops, die zunehmend im Rahmen von Konferenzen wie LLVM DevSummit oder AI-Entwickler-Konferenzen angeboten werden.
Für ein tieferes Verständnis sind Arbeiten von Experten und Open-Source-Beispiele eine gute Möglichkeit, um den Umgang mit Dialekten sowie der Erweiterbarkeit praktisch zu erlernen. Im Fall von TVM sorgen die offizielle Website und GitHub-Repositorien für einen direkt praxisbezogenen Einstieg. Diese Plattformen bieten Schritt-für-Schritt Anleitungen, die das Kompilieren eigener Deep Learning Modelle erlauben. Zudem gibt es mittlerweile Bücher und Online-Kurse, die speziell TVM und Optimierungstechniken behandeln. Für Entwickler, die möglichst schnell Ergebnisse bei der Performance-Optimierung sehen wollen, sind diese Ressourcen äußerst wertvoll.
Außerdem existieren Community-Foren wie das TVM-Forum oder Discord-Kanäle, wo Fragen direkt diskutiert werden können. Letztendlich hängt die Wahl zwischen MLIR und TVM stark von den eigenen Zielen und Vorerfahrungen ab. Wer im Bereich Compiler-Infrastruktur mit einem Blick auf langfristige Weiterentwicklung und vielseitige Anwendung interessiert ist, findet mit MLIR einen idealen Einstieg. Für Praktiker, die schnell und gezielt Deep Learning Modelle optimieren und auf vielfältigen Hardwareplattformen lauffähig machen wollen, bietet TVM unmittelbare Vorteile. Beide Frameworks entwickeln sich rasant und gegenseitige Ergänzungspotenziale sind in vielen Fällen präsent, sodass ein grundlegendes Verständnis beider Systeme von Vorteil sein kann.
Zusammenfassend lässt sich festhalten, dass MLIR durch seine Verbindung zu LLVM und seine flexible Struktur in der Compiler-Community stark an Zugkraft gewinnt, während TVM im Deep Learning Umfeld durch Performance- und Hardwareoptimierungen überzeugt. Die Auseinandersetzung mit beiden Frameworks ermöglicht ein tieferes Verständnis moderner KI-Compiler-Technologie und bereitet optimal auf die Herausforderungen und Chancen im Bereich der künstlichen Intelligenz vor.