Die Welt der Betriebssysteme und insbesondere von Linux beruht auf der Fähigkeit, mehrere Prozesse gleichzeitig auszuführen. Dabei ist die effiziente Erzeugung und Verwaltung von Prozessen und Threads ein zentrales Element. Der traditionelle Weg zur Erstellung neuer Prozesse unter Unix-artigen Systemen erfolgt meist über den fork-Systemaufruf. Zwar ist fork in der Lehre weit verbreitet, doch in Linux selbst läuft die Prozessgenerierung intern meist über den leistungsfähigeren Clone-Systemaufruf. Dieser zeichnet sich durch eine enorme Flexibilität aus, da er dem Programmierer erlaubt, genau zu bestimmen, welche Ressourcen zwischen dem Eltern- und Kindprozess geteilt werden.
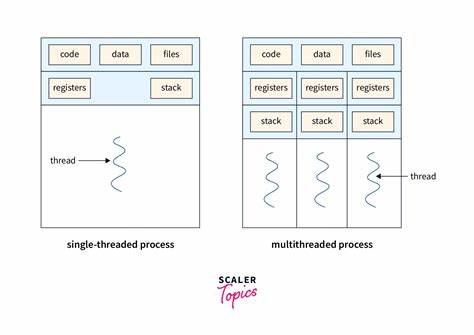
So bildet Clone nicht nur die Grundlage für Prozesse, sondern auch für Threads und Container. Das Verständnis dieses Mechanismus ist daher von großer Bedeutung für Systementwickler, Administratoren und alle, die tiefer in die Linux-Architektur eintauchen möchten. Fork erzeugt eine exakte Kopie des aufrufenden Prozesses in einem separaten Adressraum. Dies bedeutet, dass beide Prozesse eigene Speicherbereiche, Dateideskriptor-Tabellen und Signalbehandlungsmechanismen besitzen. Eine Modifikation einer Variablen im Kindprozess beeinflusst nicht den Wert derselben Variablen im Elternprozess, da beide unterschiedliche Speicherumgebungen besitzen.
Dies illustriert sehr anschaulich die Trennung von Prozessen. Im Gegensatz dazu stellt Clone die gleiche Funktionalität bereit, bietet aber zusätzlich granulare Kontrolle darüber, welche Teile der Ausführungsumgebung geteilt werden sollen. Der syscall erwartet unter anderem Flags, die definieren, ob der Speicher, die geöffneten Dateien, Signalhandler oder sogar die Thread-Gruppen gemeinsam genutzt werden. Darüber hinaus ermöglicht Clone die Erzeugung neuer Namespaces, wodurch Prozesse in völlig isolierten Umgebungen laufen können – eine Grundvoraussetzung moderner Container-Technologien. Die Funktionsweise von Clone unterscheidet sich in einem wesentlichen Punkt von Fork darin, dass der Kindprozess nicht einfach an derselben Stelle wie der Elternprozess weiterläuft, sondern an einem spezifisch definierten Funktionszeiger startet.
Zudem verlangt Clone, dass ein eigener Stack für den Kindprozess bereitgestellt wird, was eine explizite Kontrolle über den Stacksspeicher erlaubt. Das ist besonders relevant bei der Erzeugung von Threads, die im selben Adressraum laufen sollen und daher gemeinsame Ressourcen teilen. Kleinigkeiten wie die Richtung, in der der Stack wächst, müssen beim Zuweisen des Stacks beim Aufruf von Clone berücksichtigt werden. Wird bei Clone das Flag CLONE_VM gesetzt, so teilen sich Eltern- und Kindprozess denselben Speicherbereich. Änderungen an Variablen in einem Thread sind damit im anderen sichtbar.
Dies ist das grundlegende Verhalten von Threads, wie es auch in Pthreads realisiert ist. Die Thread-basierten Flags setzen zudem die gemeinsame Nutzung von Thread-spezifischen Ressourcen wie Dateisysteminformationen, Deskriptoren, Signalhandlern und vielen weiteren. Dabei spielen Flags wie CLONE_FILES für die gemeinsamen Datei-Deskriptoren oder CLONE_THREAD, das den gemeinsam genutzten Threadgruppen-Status definiert, eine wichtige Rolle. Insbesondere CLONE_THREAD bewirkt, dass die erzeugten Threads in derselben Threadgruppe sind und dieselbe PID als Threadgruppen-ID besitzen. Dies führt dazu, dass sie vom System aus als ein Prozess mit mehreren Ausführungseinheiten erscheinen.
Ein wichtiger Nebeneffekt ist, dass das Warten auf den Abschluss eines Child-Prozesses mittels wait() für Threads mit CLONE_THREAD nicht funktioniert, da sie nicht als Kindprozesse angesehen werden. Synchronisation zwischen Threads erfolgt daher über andere Mechanismen wie Semaphore, Futex oder andere primitive Mittel. Das klassische Beispiel hierfür ist pthread_join, welches intern solche Synchronisationsmechanismen nutzt. Clone bildet durch seine Flexibilität auch die Grundlage für die Erstellung von Containern in Linux. Container sind isolierte Umgebungen, die in vielerlei Hinsicht wie eigenständige Systeme wirken.
Um Prozesse so zu isolieren, dass sie wie eigenständige Systeme agieren, werden Namespaces verwendet. Diese stellen unterschiedliche Sichtweisen auf Systemressourcen bereit. Eine Prozessgruppe im neuen PID-Namespace etwa sieht nur die Prozesse im eigenen Namespace, nicht aber die des Hosts. Netzwerk-Namespaces sorgen dafür, dass die Prozesse nur die für sie definierten Netzwerkschnittstellen sehen. Dazu gehören Schnittstellen, Routingtabellen und Portbereiche.
Das bedeutet, dass mehrere Container denselben Port auf demselben Host binden können, ohne Konflikte, da sich ihre Netzwerkbereiche strikt trennen. Um die Ressourcennutzung zu kontrollieren, werden zusätzlich cgroups (Control Groups) verwendet. Mit cgroups kann man Prozesse hinsichtlich CPU-Zeit, Speicherverbrauch, I/O-Bandbreite und anderen Ressourcen einschränken und überwachen. Der Zusammenschluss von Clone-Systemaufruf, Namespaces und cgroups bildet somit die Grundlage moderner Containertechnologien wie Docker und Kubernetes. Ein praktisches Beispiel zeigt, wie mit Clone ein neuer Prozess in einem eigenen Netzwerknamespace erzeugt wird.
Dabei wird das Flag CLONE_NEWNET gesetzt. Nach der Erzeugung kann in diesem isolierten Netzwerk einer Terminalapplikation wie xterm gestartet werden. In dieser Umgebung ist der Zugriff auf Netzwerkinterfaces auf die virtuelle Loopback-Schnittstelle beschränkt. Das Ausführen von Befehlen wie ip addr offenbart die eingeschränkte Sicht. Um dem Container dennoch Internetzugang zu ermöglichen, müssen benutzerdefinierte virtuelle Netzwerkschnittstellen eingerichtet und verbindende Brücken konfiguriert werden.
Dies geschieht häufig über zusätzliche Skripte, da die Komplexität der Netzwerkverwaltung die reine Programmierung in C oft übersteigt. Ein solcher Aufbau garantiert, dass Containerprozesse sicher und stabil im isolierten Umfeld agieren können. Die Ressourcenbegrenzung über cgroups ergänzt die Namespace-Isolation durch Kontrolle über die Hardware- und Systemressourcen. Hierdurch ist sichergestellt, dass einzelne Container nicht das komplette System durch übermäßige Ressourcennutzung blockieren können. Die Verwendung von cgroups ist dabei nicht auf Container beschränkt, sie können auch für andere isolierte Prozessgruppen eingesetzt werden.
Zusammenfassend ist der Clone-Systemaufruf ein fundamentaler Bestandteil moderner Linux-Systeme. Er übertrifft Fork in Flexibilität und Funktionalität und ist essenziell für die Konstrukte von Multithreading und Containerisierung. Die feingranulare Kontrolle, welche Ressourcen geteilt oder isoliert werden, lässt Entwickler maßgeschneiderte Ausführungsumgebungen erstellen. Die Kombination mit Namespaces und cgroups revolutioniert die Art und Weise, wie Software heute deployt und betrieben wird. Wer ein tiefes Verständnis über Linux-Prozessverwaltung und moderne Infrastruktur anstrebt, sollte die Mechanismen und Einsatzmöglichkeiten von Clone detailliert kennen und nutzen.
Nur so lässt sich das volle Potenzial von Linux im Kontext von paralleler Verarbeitung, isolierten Anwendungen und sicheren Containern erschließen.