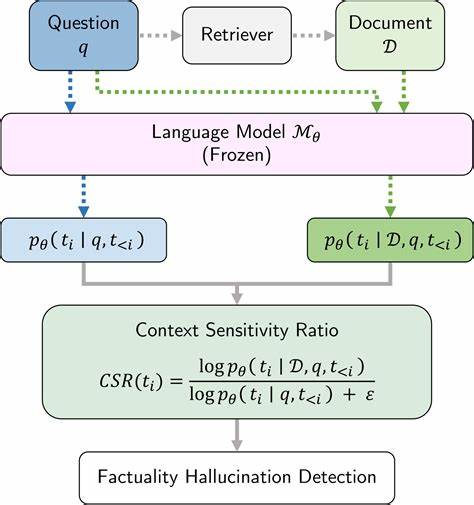
PostgreSQL ist seit jeher eine der beliebtesten relationalen Datenbanken weltweit. Viele Entwickler und Unternehmen schätzen sie für ihre Stabilität, Flexibilität und den Open-Source-Charakter. Doch wie verhält sich PostgreSQL in Szenarien mit extrem hohen Anforderungen und Millionen von aktiven Nutzern? OpenAI, das Unternehmen hinter ChatGPT und anderen revolutionären KI-Technologien, gewährt nun einen seltenen Einblick in die Architektur und die Best Practices, mit denen sie PostgreSQL auf ein völlig neues Skalierungsniveau heben. OpenAI setzt bei seinem Backend konsequent auf PostgreSQL, obwohl sie eine riesige Nutzerbasis bedienen. Dabei folgt das Unternehmen einem klassischen Prinzip: eine primäre Datenbankinstanz, auf die sämtliche Schreiboperationen geleitet werden, und zahlreiche Replikate, die vor allem Leseoperationen übernehmen.
Dieses sogenannte Primary-Replica-Setup verzichtet bewusst auf Sharding, was bei anderen Systemen oft als unverzichtbar gilt, wenn es um enorme Skalierung geht. Die Architektur verdeutlicht, dass PostgreSQL durchaus in der Lage ist, auch unter massiven Lasten effizient zu skalieren, wenn die richtigen Optimierungen vorgenommen werden. Erfahrungsgemäß lassen sich besonders Schreibvorgänge nicht grenzenlos skalieren, denn hier ist stets die primäre Instanz involviert, die als potenzieller Flaschenhals fungieren kann. OpenAI begegnet dieser Herausforderung mit gezielten Maßnahmen, um die Belastung auf den Primärserver zu reduzieren und die Leistungsfähigkeit auf einem konstant hohen Niveau zu halten. Eines der Kernprobleme in PostgreSQL stellt der Umgang mit Schreiboperationen dar.
Dank Multi-Version Concurrency Control (MVCC) werden bei jeder Änderung neue Versionen von Datensätzen erzeugt, was zu sogenannten Bloat-Problemen bei Tabellen und Indizes führen kann. Diese Bloat-Problematik kann sich negativ auf Performance und Speicherplatz auswirken, wenn sie nicht adäquat adressiert wird. OpenAI optimiert daher intensiv den VACUUM-Prozess, welcher automatisiert diese alten Versionen bereinigt. Dabei ist es entscheidend, lange laufende Transaktionen zu vermeiden, da sie das Freigeben von Speicher verzögern und die Vacuumeffizienz einschränken. Neben der technischen Infrastruktur ist auch das designte Verhalten auf Anwendungsebene ein entscheidender Faktor.
OpenAI strebt danach, unnötige Schreiboperationen direkt in der Applikationslogik zu vermeiden. Beispielsweise werden Schreibspitzen durch sogenannte Lazy Writes geglättet, um Lastspitzen zu verteilen und damit Engpässe zu minimieren. Zusätzlich weist das Unternehmen darauf hin, dass komplexe ORM-Abfragen oft ineffizient sind und zu langen Laufzeiten führen können. Ein sorgsamer und bewusster Umgang mit der Datenbankabfrage ist daher ein Schlüssel zum Erfolg. Im Bereich der Skalierung legt OpenAI besonderen Wert auf das Ausbalancieren der Last zwischen Primärinstanz und Replikaten.
Während mehr als ein Dutzend Replikate verteilt in verschiedenen geografischen Regionen für schnelle Lesezugriffe sorgen, bleibt die primäre Instanz ausschließlich für Schreibprozesse verantwortlich. Dadurch lässt sich die Last effektiv aufteilen und gleichzeitig Ausfälle einzelner Replikate abfedern, denn solange die Primärinstanz verfügbar ist, können diese parallel Leseanfragen übernehmen. Ein weiterer interessanter Punkt ist die Unterscheidung zwischen hoch priorisierten und weniger dringlichen Anfragen. Für kritische Lesezugriffe stellt OpenAI eigens reservierte Replikate bereit, um sicherzustellen, dass Leistungsbeeinträchtigungen durch weniger wichtige Queries vermieden werden. Dieses Priorisierungskonzept unterstützt die Verfügbarkeit wichtiger Services auch unter hohem Traffic und großen Belastungen.
Schemaänderungen, die in relationalen Datenbanken für gewöhnlich zu erheblichen Überschreibungen und temporären Sperren führen können, werden bei OpenAI gezielt eingeschränkt. Nur leichte Änderungen wie das Hinzufügen oder Entfernen von Spalten in Tabellen sind auf der primären Datenbank erlaubt, während aufwändige Operationen, die eine vollständige Neuschreibung der Tabelle erfordern, vermieden werden. Um Konflikte mit langen Abfragen zu verhindern, werden komplexe oder langlaufende Queries nach Möglichkeit auf Replikate verlagert. Auf diese Weise ist es OpenAI gelungen, eine PostgreSQL-Umgebung auf Azure mit mehreren Dutzend Replikaten zu betreiben, die zusammen Millionen von Abfragen pro Sekunde abwickeln können. Dabei konnten sie den Replicationslag gering halten und die Verfügbarkeit auf einem sehr hohen Level sichern.
Über einen Zeitraum von neun Monaten gab es lediglich einen einzigen schwerwiegenden Fehler (SEV0), der mit PostgreSQL zusammenhing – ein bemerkenswert guter Wert angesichts der Belastung. Während der Präsentation auf der PGConf.dev 2025 äußerte OpenAI auch konkrete Wünsche an die PostgreSQL-Community. Beispielsweise wünschen sie sich eine Möglichkeit, ungenutzte Indizes temporär zu deaktivieren, um deren Auswirkungen besser überwachen zu können, bevor sie endgültig gelöscht werden. Außerdem sind verbesserte Metriken für die Beobachtung von Latenzen, insbesondere Histogramme und Perzentile wie p95 oder p99, stark gefragt.
Diese Kennzahlen ermöglichen es, Performanceprobleme viel präziser zu erkennen. Im Hinblick auf Schema-Veränderungen wünschen sich die OpenAI-Architekten eine native Historienfunktion für DDL-Operationen, sodass Änderungen nachvollziehbar, auditierbar und besser steuerbar sind. Aktuell ist dies oft nur über umfangreiche Log-Analysen realisierbar. Ein weiteres Anliegen betrifft die Überwachung von Sessions mit ungewöhnlichem Status, etwa wenn eine Verbindung trotz Idle-In-Transaction-Timeouts lange aktiv bleibt und nicht beendet werden kann. Hier sieht OpenAI Potenzial für verbesserte Alarme und Eingriffsmöglichkeiten.
Abschließend kritisieren sie die konservativen Standardparameter von PostgreSQL. Diese gehen zwar auf Nummer sicher, sind aber selten für moderne Hardware und Cloud-Umgebungen optimiert. Dynamische, heuristisch gesteuerte Einstellungsprofile oder zumindest ein intelligenterer Initialisierungsprozess wären wünschenswert, um die Performance von Anfang an zu maximieren. Interessanterweise ist ein großer Teil der limitierenden Faktoren bei OpenAIs Setup nicht PostgreSQL selbst, sondern die Restriktionen des Managed Database Service von Azure. Obwohl dieser erstklassigen Support und Infrastruktur bietet, fehlen teilweise administrative Rechte für tiefgreifende Eingriffe, die bei self-hosted Lösungen möglich wären.
Für einen noch größeren Feinschliff empfiehlt sich aus Expertensicht eventuell eine eigenständige PostgreSQL-Installation auf leistungsstarken NVMe-Instanzen im IaaS-Modell. Schon heute gibt es Open-Source-Projekte wie Pigsty, die genau solche Herausforderungen adressieren und eine flexible, skalierbare Verwaltung von PostgreSQL-Clustern ermöglichen. Solche Lösungen könnten auch OpenAI helfen, noch effizienter und unabhängiger von Cloud-Service-Limitationen zu operieren. Allerdings hat OpenAI aufgrund des rasanten Wachstums und der Komplexität der Infrastruktur verständlicherweise andere Prioritäten und setzt auf ihre erfahrenen DBA-Teams. Der Einblick von OpenAI liefert nicht nur wertvolle Erkenntnisse für Unternehmen mit vergleichbaren Herausforderungen, sondern setzt auch ein starkes Signal für die Leistungsfähigkeit und Anpassungsfähigkeit von PostgreSQL in hochskalierbaren Umgebungen.
Die Kombination aus durchdachter Architektur, gezielter Optimierung und einem geschärften Verständnis der Grenzen des Systems zeigt, wie es gelingen kann, selbst Millionen von Nutzern mit einem einzigen Datenbanksystem zu bedienen. Zusammenfassend lässt sich sagen, dass OpenAI mit ihrem Ansatz die gängigen Vorstellungen, dass verteilte oder fragmentierte Datenbanken unvermeidbar sind, herausfordert. Stattdessen vertrauen sie auf das bewährte PostgreSQL-Ökosystem – dank moderner Hardware, strategischem Design und umfangreichem Know-how. Diese Perspektiven eröffnen neue Horizonte für Skalierbarkeit und Effizienz, denen auch andere Unternehmen folgen können, die auf robuste, relationale Datenbankarchitekturen setzen.