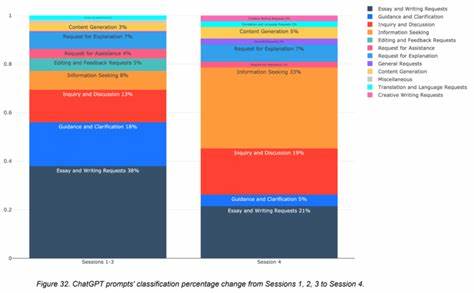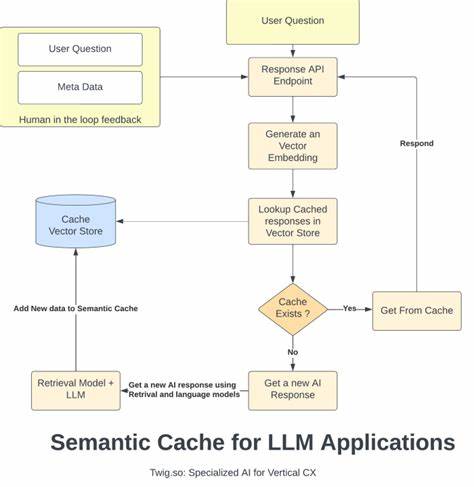
In der heutigen Zeit, in der große Sprachmodelle (Large Language Models, kurz LLMs) wie GPT-4, Anthropic oder Gemini eine immer wichtigere Rolle in verschiedenen Bereichen spielen, stehen Entwickler und Unternehmen vor der Herausforderung, die Kosten und die Latenzzeiten bei der Nutzung dieser Modelle effizient zu managen. Jedes einzelne LLM-Modell ist mit beträchtlichen Berechnungskosten verbunden, insbesondere bei der Wiederholung häufiger oder ähnlicher Anfragen. Hier setzt Semcache als bahnbrechendes Tool an, das die Antwortzeiten radikal verkürzt und gleichzeitig die Token-Nutzung deutlich reduziert. Semcache ist ein semantic caching System, das entwickelt wurde, um die wiederkehrenden Anfragen an LLMs durch intelligente semantische Übereinstimmung zu erkennen und bereits berechnete Antworten wiederzuverwenden. Im Gegensatz zu klassischen Cache-Methoden, die oberflächliche oder exakte Übereinstimmung prüfen, versteht Semcache den Kontext und kann sogar dann eine Antwort liefern, wenn die Suchanfrage sprachlich leicht variiert oder umgeschrieben wurde.
Semcache funktioniert als ein Drop-in-Proxy, der besonders einfach in bestehende Anwendungen integriert werden kann. Entwickler müssen lediglich eine minimale Änderung ihres API-Endpunkts vornehmen, indem sie die Anfragen an Semcache statt direkt an die LLM-API richten. Das System leitet dann semantisch relevante Anfragen sofort aus dem Cache weiter oder sendet neue, nicht gespeicherte Anfragen an die eigentlichen Modelle und speichert die Antwort für zukünftige Anfragen. Dieses Prinzip ermöglicht ein nahezu verzögerungsfreies Antwortverhalten bei wiederkehrenden Themen und sorgt gleichzeitig für eine erhebliche Senkung der Modellanfragen und damit verbundenen Kosten. Die Funktionalität von Semcache beschränkt sich nicht nur auf Text-basierte Interaktionen.
Es kann ebenso multimodale Inhalte wie Bilder und Audio als Antworten cachen, was es für vielfältige Anwendungen im Bereich der künstlichen Intelligenz enorm attraktiv macht. Unternehmen im Bereich Kundenservice profitieren besonders von der flexiblen Handhabung, da Kunden häufig ähnliche Fragen unterschiedlich formulieren. Semcache erkennt diese Variationen als semantisch gleichwertig und liefert konsistente Antworten, selbst wenn die Formulierung variiert. Dadurch erhöht sich nicht nur die Effizienz des Kundenservices, sondern auch die Kundenzufriedenheit durch schnellere Antworten. Neben der einfachen Integration und der Effizienz steht bei Semcache die Persistenz der gespeicherten Daten im Vordergrund.
Die gespeicherten Antworten bauen mit der Zeit eine ständig wachsende Wissensdatenbank auf, die individuell auf die Bedürfnisse der Anwendung zugeschnitten ist. Diese persistent gespeicherte Wissensbasis reduziert im Laufe der Zeit weiter den Bedarf an erneuten Modellanfragen, was wiederum Kosten reduziert und die Systemlatenz senkt. Semcache bietet die Möglichkeit, als Cloud-Service genutzt zu werden oder selbstgehostet zu werden, was Unternehmen volle Kontrolle und Flexibilität hinsichtlich Datenschutz und Infrastruktur ermöglicht. Für Anwendungsfälle wie dokumentenbasierte Frage-Antwort-Systeme oder Retrieval-Augmented-Generation (RAG) Applikationen ist Semcache besonders wertvoll. Gerade bei aufwendigen Dokumentenabfragen, bei denen das Abrufen und Verarbeiten von großen Datenmengen teuer und zeitintensiv sein kann, erlaubt Semcache eine semantische Vorverarbeitung und Wiederverwendung bereits beantworteter Fragen.
So erhalten Nutzer konsistent schnelle Antworten und Entwickler sparen signifikant bei den Nutzungskosten der LLMs. Ein weiterer bedeutender Vorteil von Semcache liegt in der umfassenden Observability und Monitoring-Funktionalität. Die Software liefert integrierte Prometheus-Metriken und ein Dashboard, das in Echtzeit Informationen über Cache-Hit-Raten, Latenzzeiten und Kosteneinsparungen ausgibt. Dieses Monitoring ermöglicht es Betreibern, den Einsatz des Tools transparent nachzuvollziehen und das System bei Bedarf zu optimieren. Darüber hinaus unterstützt Semcache eine breite Palette von gängigen LLM-Anbietern und Tools wie OpenAI, Anthropic, Gemini sowie SDKs wie LangChain oder LiteLLM.
Diese Kompatibilität erleichtert die Einführung in bestehende Infrastrukturumgebungen erheblich und macht die Lösung für eine Vielzahl von Branchen und Use Cases einsetzbar. Unternehmen mit hohem Volumen an Nutzerfeedback, Bewertungen oder Supportanfragen profitieren ebenfalls von Semcache. Indem häufig auftretende Feedbackthemen semantisch erkannt und im Cache gespeichert werden, lassen sich wiederholte, nahezu identische Analysen vermeiden. Die TIme-to-Insight wird dadurch deutlich verkürzt und die Kosten der Feedbackverarbeitung reduziert. Der Open-Source-Charakter von Semcache fördert zudem eine breite Entwicklercommunity, in der gemeinschaftlich an Verbesserungen und Erweiterungen gearbeitet wird.
Für Unternehmen, die nicht selbst hosten möchten, steht Semcache Cloud mit erweiterten Features wie SLAs, dediziertem Support und benutzerdefinierten Embedding-Modellen zur Verfügung. Semcache setzt neue Maßstäbe im Umgang mit den Herausforderungen moderner KI-Anwendungen und trägt entscheidend dazu bei, LLMs skalierbar, kosteneffizient und schnell nutzbar zu machen. Besonders in Zeiten stetig wachsender Nachfrage nach intelligenten Sprachmodellen ist semantisches Caching ein wichtiger Baustein, um die Vorteile von KI-Technologien ohne übermäßige Kostenbelastung auszuschöpfen. Für Entwickler, Unternehmen und Endnutzer bedeutet das bessere Performance, verbesserte Nutzererlebnisse und nachhaltigere Geschäftsmodelle. Insgesamt ist Semcache eine zukunftsweisende Technologie, die den Umgang mit großen Sprachmodellen grundlegend transformiert.
Die Kombination aus semantischer Intelligenz, einfacher Integration, persistenter Wissensspeicherung und umfassender Beobachtbarkeit macht es zu einem unverzichtbaren Werkzeug für jeden, der den geschäftlichen Einsatz von LLMs effizienter gestalten möchte. Die senkbaren Kosten bei gleichzeitig verbesserter Antwortgeschwindigkeit steigern die Attraktivität für vielfältige Einsatzszenarien – von Kundenservice über Dokumentenmanagement bis hin zur Feedbackanalyse und darüber hinaus. Schließlich ebnet Semcache mit seinem intelligenten Ansatz den Weg für eine neue Generation smarter Anwendungen, die nicht nur leistungsfähig, sondern auch wirtschaftlich optimal sind.