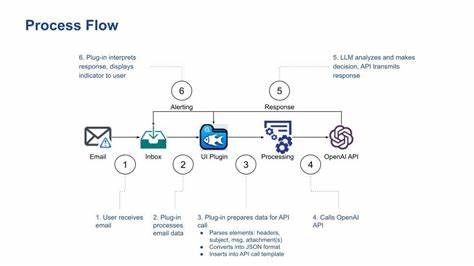
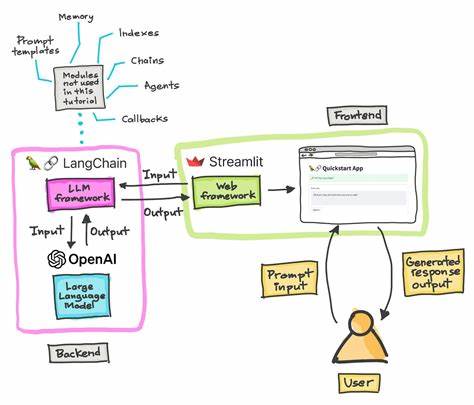
In den letzten Jahren hat die Entwicklung von generativen KI-Sprachmodellen wie GPT-3, ChatGPT und anderen Transformer-basierten Systemen die Art und Weise revolutioniert, wie wir mit digitalen Texten interagieren und kommunizieren. Ein zentrales Element dieser Systeme ist die sogenannte Tokenisierung, die eine ideale Brücke zwischen rohem Text und maschinenverarbeitbaren Einheiten bildet. Doch hinter der scheinbar simplen Zerlegung von Sprache in Token kommt eine komplexe Verbindung zur Informationstheorie zum Vorschein – insbesondere zur Entropie. Die Frage nach dem optimalen Umgang mit Entropie im Kontext von Sprachmodellen und wie sie die Tokenisierung beeinflusst, bleibt bis heute ein spannendes und teilweise unbeantwortetes Thema, das sowohl Entwickler als auch Wissenschaftler beschäftigt. Tokenisierung ist der Prozess, bei dem ein Text in kleinere bedeutungstragende Einheiten zerlegt wird.
Anders als bei der herkömmlichen Betrachtung von Text auf Wort- oder Buchstabenebene verfolgt die Tokenisierung in modernen Sprachmodellen einen Mittelweg. Dabei werden Subworteinheiten gebildet, die häufige Wortteile oder Kombinationen darstellen. Dieses Vorgehen ist deshalb sinnvoll, weil die englische oder deutsche Sprache eine schier unerschöpfliche Vielfalt an Wörtern hat, sich aber aus einer viel kleineren Anzahl von Bausteinen zusammensetzt. Modelle wie GPT-3 basieren auf Tokenisierungsmethoden, die Wörter in Token zerlegen, die weder reine Buchstaben noch vollständige Worte sind, sondern eine Art Zwischending darstellen. Ein Vorteil dieser Subwort-Tokenisierung liegt darin, dass auch neue oder seltene Worte, die der Trainingsdatensatz nicht umfasst, sinnvoll verarbeitet werden können.
Wenn zum Beispiel ein Wort wie „overpythonized“ auftaucht, was ein erfundenes oder sehr seltenes Wort ist, zerlegt die Tokenisierung es in bekannte Bestandteile wie „over“, „python“ und die Endung „ized“. So kann das Modell trotz fehlender direkter Trainingsdaten einen Kontext ableiten. Der Begriff „Entropie“ stammt aus der Informationstheorie und beschreibt die durchschnittliche Informationsmenge – oder Unsicherheit – die in einer Quelle von Daten steckt. Einfach gesagt, gibt die Entropie an, wie viel Information pro Symbol übertragen werden muss, um eine Nachricht optimal zu codieren. Je höher die Entropie einer Datenquelle, desto mehr Bits werden im Durchschnitt benötigt, um diese Information verlustfrei darzustellen.
Ein gut bekanntes Beispiel ist die Kodierung von Text mithilfe von Algorithmen wie Huffman-Codierung. Hier werden häufig auftretende Zeichen mit kürzeren Bitfolgen dargestellt, während seltenere Zeichen längere Codes erhalten. Auf diese Weise wird im Durchschnitt der benötigte Speicherplatz bzw. die Übertragungszeit minimiert. Doch wie hängt das mit der Tokenisierung in GPT-Modellen und der Sprachverarbeitung zusammen? Die Tokenisierung stellt im Grunde eine Art Codierung des Textes dar.
Im Gegensatz zu einfachen Algorithmen zur Kompression zielt die Tokenisierung aber darauf ab, das Sprachmodell beim nächsten Token vorherzusagen zu unterstützen. Das bedeutet, dass die Tokenisierung nicht nur aus Kompressionssicht optimiert ist, sondern vor allem für Vorhersagegenauigkeit und Effizienz im Trainingsprozess entwickelt wurde. Das Ergebnis ist, dass Tokenisierung nicht immer die minimal mögliche Anzahl von Token pro Wort erzeugt, was letztlich auch Einfluss auf die Kosten bei der Nutzung von GPT-Modellen nimmt, da Abrechnung oft pro Token erfolgt. Die Frage nach der optimalen Tokenisierung für ein gegebenes Sprachmodell ist ein sehr anspruchsvolles Problem. Man könnte sich vorstellen, dass es eine Methode geben müsste, die gemeinsame Optimierung von Tokenisierung und Modelltraining erlaubt.
So käme man theoretisch zu einer Tokenisierung, die genau auf die Bedürfnisse des Modells zugeschnitten ist und dabei maximale Effizienz und Präzision garantiert. In der Praxis ist dies jedoch äußerst komplex, weil die Tokenisierung als externer Schritt vor dem Modelltraining erfolgt und nicht gemeinsam gelernt wird. Darüber hinaus müsste die Tokenisierung differenzierbar sein, um in den Optimierungsprozess eingebunden zu werden, was technisch eine große Herausforderung darstellt. Ein weiterer faszinierender Aspekt ist die Untersuchung, wie einzelne Token oder Symbole zum Gesamtwert der Entropie einer Sprachquelle beitragen. Entropie wird durch Summierung des Produkts von Symbolhäufigkeit und dem negativen Logarithmus dieser Häufigkeit berechnet.
Interessanterweise liegt die maximale Beitragsleistung eines einzelnen Symbols zur Entropie bei etwa 36,79 % – ein Wert der exakt mit 1 geteilt durch die eulersche Zahl e zusammenfällt. Die Zahl e spielt eine zentrale Rolle in diversen mathematischen Kontexten, bis heute ist jedoch eine intuitive Erklärung für diesen Zusammenhang im Bereich der Sprach- und Informationsmodellierung offen. Dieses Ergebnis wirft eine grundsätzliche Frage auf, die viele Forscher und Entwickler beschäftigt: Weshalb ist gerade dieser Wert maßgeblich, und was sagt er über die Struktur und Dynamik von Informationsquellen aus? Die Entropie und Kodierung hängen auch eng mit der Art und Weise zusammen, wie Sprache auf unterschiedliche Sprachen und Dialekte abgestimmt wird. Die Tokenisierung, die primär für Englisch entwickelt wurde, weist Einschränkungen auf, wenn sie auf andere Sprachen angewandt wird. Ein Beispiel hierfür ist die polnische Sprache, bei der übliche Wortbestandteile anders segmentiert werden als im Englischen.
Dies führt dazu, dass wichtige Bedeutungsträger wie „python“ nicht als Token erkannt werden, was wiederum negative Folgen für die Modellleistung hat, wenn es um das Verstehen von Texten in anderen Sprachen geht. Folglich ist eine sprachspezifische Tokenisierung oder adaptive Methoden wünschenswert, um Effizienz und Kontextverständnis zu verbessern. Es zeigt sich, dass die Verbindung von Entropie und Tokenisierung in KI-Sprachmodellen ein Gebiet von großer Bedeutung und Komplexität darstellt. Gute Tokenisierung beeinflusst die Fähigkeit des Modells, natürliche Sprache effizient zu verstehen und zu erzeugen. Gleichzeitig kann ein tieferes Verständnis der Entropie dazu beitragen, diese Tokenisierung zunehmend zu optimieren und auch Kosten bei der Nutzung entsprechender KI-Modelle zu reduzieren.
Ein praktischer Ansatz, um die Tokenisierung zu verbessern, liegt in der Analyse von realen Textquellen und deren Tokenisierungskosten. Textsorten, die dem Modell vertrauter sind, neigen dazu, weniger Token pro Wort zu benötigen. So sind beispielsweise englische Wikipedia-Artikel, Reden oder rechtliche Dokumente vergleichsweise effizient kodiert, während Übersetzungen oder Texte in anderen Sprachen oft mehr Token pro Wort benötigen. Die Kosten auf Tokenbasis sind somit eng mit der Übereinstimmung zwischen dem Trainingskorpus und dem Eingabetext verbunden. Allerdings löst die Suche nach der perfekten Tokenisierung allein nicht alle Herausforderungen.
Auch wenn man eine optimale Aufteilung der Texte in Token findet, bleibt die zugrunde liegende Modellarchitektur und deren Fähigkeit, den Kontext zu verstehen, entscheidend. Dort setzt Forschung an, die nicht nur die Anzahl der benötigten Token, sondern auch deren inhaltliche Qualität und Repräsentation neu denkt. Zudem könnte die Integration von Kompressionstechniken mit lernfähigen Tokenisierungssystemen in der Zukunft leistungsfähigere und kosteneffizientere Sprachmodelle hervorbringen. Ein weiterer spannender Ansatz ist die Erforschung von adaptiven Tokenisierungssystemen, welche sich dynamisch an verschiedene Sprachen, Textsorten oder sogar individuelle Nutzer anpassen können. Diese könnten Entropie und Kontextwissen nutzen, um die Tokenlänge und -struktur intelligent anzupassen und so eine noch bessere Balance zwischen Informationsgehalt, Modellfähigkeit und Rechengeschwindigkeit zu erreichen.
Die tiefere Analyse der Entropie in Verbindung mit der Tokenisierung eröffnet auch philosophische Fragestellungen zur Natur von Sprache und Information. Sprache ist kein statisches System, sondern entwickelt sich ständig weiter. Die Verteilung von Symbolen und deren Bedeutung ändern sich mit gesellschaftlichen und kulturellen Wandlungen. Die Herausforderung für KI besteht darin, trotz dieser Dynamik stabile und vorausschauende Modelle zu bauen, was über reine mathematische Optimierung hinausgeht. Abschließend zeigt die bisherige Entwicklung, dass das Verhältnis zwischen Entropie, Tokenisierung und Sprachmodellierung viele faszinierende Aspekte beinhaltet, die weit über reine technische Fragestellungen hinausgehen.
Trotz großer Fortschritte gibt es weiterhin offene Fragen, die tiefere theoretische sowie praktische Forschung benötigen. Der Wunsch, die optimale Frequenz von Symbolen zu verstehen, die den größten Beitrag zur Entropie leisten, ist nur ein Beispiel dafür, wie grundlegende Konzepte der Mathematik und Informationstheorie immer noch neue Einsichten und Herausforderungen im Bereich der künstlichen Intelligenz bringen. Damit bleibt das Thema Entropie im Kontext von KI-Sprachmodellen ein aufregendes Forschungsfeld, das das Potenzial hat, unsere Verständigung mit Maschinen grundlegend zu verbessern und die Kosten sowie Effizienz von KI-Systemen nachhaltig zu optimieren. Unternehmen wie Quickchat, die an der Spitze dieser Entwicklungen stehen, zeigen, dass der Weg von rein theoretischen Überlegungen hin zu realen Anwendungen und Innovationen spannende Perspektiven eröffnet und die technische Zukunft prägt.


![2014 Eugene Jarvis describes Robotron 2084 in detail [video]](/images/9FBF9D69-EEA4-4C57-A683-7713CEEDEB04)