In der heutigen Datenlandschaft sind flexible, skalierbare und schnelle Datenmanagementsysteme essenziell für Unternehmen, die große Datenmengen effizient verarbeiten möchten. DuckLake tritt als bahnbrechende Innovation in die Szene, welche das klassische Lakehouse-Prinzip gewaltig erweitert. Während viele Systeme auf komplexe Dateiorganisationen und teilweise schwierige Konsistenzgarantien setzen, verfolgt DuckLake einen klaren und zugleich radikal einfachen Ansatz. Die Lösung basiert darauf, dass sämtliche Metadaten in einer herkömmlichen, aber ACID-fähigen SQL-Datenbank verwaltet werden, während die eigentlichen Daten in offenen und bewährten Formaten wie Parquet in einem Blob-Speicher abgelegt werden. Diese Trennung, kombiniert mit der Leistungsfähigkeit moderner SQL-Datenbanken, schafft eine neue Stufe von Verlässlichkeit, Geschwindigkeit und Einfachheit, die bislang bei Lakehouses fehlte.
Die Entstehungsgeschichte von DuckLake ist eng mit den Herausforderungen verbunden, die in der Datenverarbeitung von Data Lakes und Lakehouses zu bewältigen sind. Data Lakes, die große Mengen an Rohdaten in offenen Formaten speichern, erlauben grundsätzlich uneingeschränkten Zugriff, bergen jedoch erhebliche Schwierigkeiten, wenn es um Änderungen und Transaktionssicherheit geht. Traditionelle Ansätze, wie reines Ablegen von Dateien in Verzeichnissen, ermöglichen zwar das Hinzufügen von Daten durch bloßes Anfügen von Dateien, aber komplexere Operationen wie Updates oder Löschungen wurden mit aufwändigen und fehleranfälligen Skripten umgesetzt. Zur Bewältigung dieser Probleme wurden Formate wie Apache Iceberg und Delta Lake entwickelt. Sie bieten Strukturen, um Änderungen korrekt zu verwalten, Snapshots zu erzeugen und eine Art Transaktionsmechanismus auf Dateiebene zu erfinden.
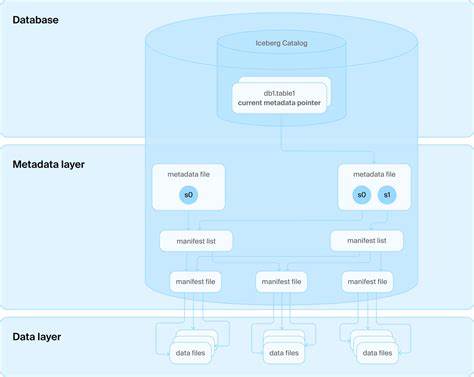
Doch auch diese Formate stehen vor großen Hürden, denn das Blob-Storage-Systems mit seiner eventual consistency erschwert atomare Operationen und sorgt für Inkonsistenzen und komplizierte Lock-Mechanismen. Zudem ist die Metadataverwaltung in diesen Systemen äußerst komplex und verlangt häufig den Einsatz zusätzlicher Katalogdienste, die wiederum auf einer Datenbank basieren müssen. Die ursprüngliche Vision, ganz ohne Datenbanken auszukommen, wird so widerlegt – ohne jedoch die Designs dieser Formate grundlegend zu überarbeiten. DuckLake setzt genau an dieser Stelle an und nimmt die Datenbank als Leitprinzip ernst. Statt Metadaten über mehrere JSON- oder Avro-Dateien verstreut im Blob-Speicher abzulegen, werden alle diese Informationen in relationalen SQL-Tabellen in einer Datenbank abgelegt.
Dies umfasst sowohl die Verwaltung von Schemata, Tabellenstrukturen, Snapshots als auch der Datenänderungen selbst. Dadurch ergeben sich mehrere Vorteile. Die Metadatenverwaltung wird nicht nur erheblich erleichtert, sondern auch stark beschleunigt. Die Verwendung einer ACID-fähigen Datenbank garantiert atomare Operationen und bietet eine stabile Grundlage für vielfältige Datenänderungen mit mehreren Schemata und Tabellen auf einmal. Der Dateninhalt verbleibt weiterhin in offenen Formaten wie Parquet, wodurch Skalierbarkeit und Kompatibilität mit bestehenden Datenökosystemen erhalten bleibt und Speicher-Vendor-Lock-ins vermieden werden.
Auf diese Weise vereint DuckLake die besten Eigenschaften klassischer Data Lakes mit den Merkmalen leistungsfähiger relationaler Datenbanken zu einem schlüssigen Gesamtsystem. Die so erzielte Trennung von Speicher, Metadatenmanagement und Rechenleistung entspricht modernen Architekturideen von Cloud-Datenplattformen und ermöglicht enorme Skalierungsmöglichkeiten. Ein entscheidender Vorteil von DuckLake liegt darüber hinaus in der extremen Einfachheit der Verwaltung. Die Metadatenbank lässt sich mit jeder beliebigen, halbwegs fähigen SQL-Datenbank umsetzen, solange diese grundlegende Funktionen wie ACID-Transaktionen und Primary-Key-Unterstützung bietet. Das eröffnet völlig neue Optionen im Betrieb, da Anwender auf eine bewährte Infrastruktur zurückgreifen können, die vielfach bereits im Unternehmen existiert.
Die Metadaten sind dabei stets in einem einzigen einheitlichen SQL-Schema gespeichert – ganz ohne unübersichtlichen Katalogserver, JSON-Snippets oder Aufbereitungsschichten. SQL-Standardwissen reicht aus, um die Datenhierarchien zu verstehen und zu verwalten. Die DuckLake-Architektur nutzt auch die Fähigkeiten moderner Cloud-Umgebungen bestmöglich. Daten werden auf Objektspeichern wie Amazon S3, Azure Blob Storage oder Google Cloud Storage abgelegt. Die Metadatenbank kann zentralisiert betrieben und hochverfügbar skaliert werden, während beliebig viele Rechenknoten gleichzeitig auf dieselben Daten und Metadaten zugreifen und parallele Transaktionen ausführen können.
Selbst bei hoher Konkurrenz um Schreibaktionen muss nur die Metadatenbank diese Synchronisierung bewältigen, was bei gutem Datenbankmanagement in PostgreSQL, Spanner oder ähnlichen Systemen problemlos funktioniert. Die Trennung beseitigt damit die bisherigen Performance-Bremser und Komplexitätsquellen vieler Lakehouse-Umgebungen. Neben Skalierbarkeit und Einfachheit besticht DuckLake vor allem durch seine enorme Geschwindigkeit. Die Nutzung einer einzigen SQL-Datenbank für alle Metadaten halbiert die Anzahl erforderlicher HTTP-Anfragen an den Speicher drastisch und reduziert Latenzen beim Planen von Abfragen deutlich. Typische Engpässe, die bei anderen Lakehouse-Systemen durch viele kleine Dateizugriffe und Manifest-Manipulationen entstehen, entfallen.
Zudem ist das Schreiben von Datenänderungen in einem atomaren Transaktionsblock möglich, wodurch selbst kleine Änderungen von Daten extrem performant verarbeitet werden können. Die Option, kleine Datenänderungen sogar gänzlich im Metadaten-Store in der Datenbank abzuspeichern, macht die Bearbeitung von häufig erfolgenden Updates noch schneller und reduziert die Anzahl zu verwaltender Dateien drastisch. Dies wiederum erleichtert Aufräum- und Kompaktierungsprozesse erheblich. Die Möglichkeiten von DuckLake sind umfassend und modern. Neben den klassischen Funktionen wie Einfügen, Aktualisieren und Löschen von Daten unterstützt das Format auch komplexe Datentypen, die beliebig verschachtelt werden können.
Mehrschematische Umgebungen und Mehrtabellentransaktionen sind ebenso möglich wie vollständige zeitbasierte Datenversionierungen mit Zeitreisen. So kann man jederzeit historische Zustände des Datenbestands abfragen oder zum Beispiel Änderungen inkrementell nachvollziehen. Das macht DuckLake auch für Anwendungen mit höchsten Anforderungen an Datenintegrität und Nachvollziehbarkeit höchst attraktiv. Die Integration von DuckLake in praxisnahe Workflows gelingt durch die DuckDB DuckLake Extension. Diese Erweiterung verwandelt die bewährte Single-Node-Analysedatenbank DuckDB in ein Lakehouse-Format, das sowohl lokal als auch in verteilten Clients zusammenarbeitet.
Der DuckLake-Katalog kann lokal in einer DuckDB-Datei oder in gängigen Datenbanken wie PostgreSQL, SQLite oder MySQL betrieben werden. Das ermöglicht sowohl den Einsatz auf dem Laptop für Entwicklung und Prototyping als auch in großen Cloud-Umgebungen mit mehreren Hundert oder Tausend Compute-Knoten. Hat man beispielsweise eine lokale DuckLake-Datenbank über die DuckDB-Erweiterung angelegt, zeigt sich das Prinzip schnell: Nach dem Anlegen von Tabellen und Einfügen von Daten werden Parquet-Dateien im Dateiordner abgelegt, während das Metadaten-Schema alle nötigen Informationen zu Snapshots, Datenstatistiken und Änderungen enthält. Änderungen werden in SQL-Transaktionen verwaltet, was jedem Anwender die gewohnte Transaktionssicherheit und Fehlerbehandlung eines relationalen Datenbanksystems bietet. Benutzer können per SQL zeitbasierte Abfragen durchführen, etwa eine Tabelle vor oder nach bestimmten Änderungen abfragen, und sich Tabellenänderungen zwischen zwei Versionen anzeigen lassen.
Selbst komplexere Operationen wie Rollbacks oder das parallele Arbeiten mehrerer Nutzer sind problemlos umsetzbar. Dadurch eignet sich DuckLake hervorragend für moderne Data-Warehouse- und Data-Lake-Anwendungsfälle, bei denen viele Nutzer und Anwendungen gleichzeitig auf große Datenmengen zugreifen, diese verändern und ausgewertet werden sollen. Im Vergleich zu bestehenden Lakehouse-Lösungen reduziert es die Betriebskomplexität deutlich und nutzt bekannte Werkzeuge und Konzepte. Das erleichtert nicht nur den Einstieg, sondern steigert auch die Zuverlässigkeit und Wartbarkeit der gesamten Plattform. Abschließend lässt sich sagen, dass DuckLake ein neues Kapitel im Lakehouse-Design aufschlägt.
Die clevere Kombination aus bewährtem SQL-Datenbankmanagement für Metadaten mit der Offenheit von Parquet als Datenspeicher punktet in vielerlei Hinsicht. Sie löst die bestehenden Schwachstellen klassischer Data-Lake- und Lakehouse-Konzepte auf natürliche Weise, verbessert Performance und Skalierung drastisch und macht das System durch ein einfach nachvollziehbares Metadatenmodell sehr benutzerfreundlich. Für Unternehmen, die große Datenmengen mit hoher Agilität, Sicherheit und Performance verwalten wollen, ist DuckLake eine spannende und zukunftssichere Alternative. Mit der Verfügbarkeit der DuckLake-Erweiterung für DuckDB und dem modularen Aufbau kann die Akzeptanz dieses Formats stark wachsen – gerade auch, weil es sich nahtlos in existierende SQL-Datenbanken integrieren lässt und viele Probleme traditioneller Lakehouse-Architekturen löst. Interessierte sollten einen genaueren Blick auf DuckLake werfen, um von den Vorteilen einer modernen, datenbankgestützten Lakehouse-Implementierung zu profitieren.
Die Zukunft des Datenmanagements könnte so einfach, schnell und skalierbar werden, wie es der Name DuckLake verspricht.



![Joint Industry Call on the European Internal Security Strategy [pdf]](/images/38929889-0749-463C-AAA3-94E686E7FA3F)