Linux ist weit mehr als nur ein Betriebssystem – es ist eine mächtige Plattform, die vor allem durch ihre vielseitige Kommandozeile, die sogenannte Shell, begeistert. Wer sich intensiv mit Linux beschäftigt, kommt früher oder später nicht um das Thema Shell und Shell-Skripte herum. Diese sind essenziell, um Aufgaben zu automatisieren, Systemprozesse zu steuern und komplexe Abläufe auf einfache Weise zu bewerkstelligen. Dabei geht es nicht nur um die reine Bedienung eines Terminals, sondern um das Verständnis einer ganzen Welt aus Befehlen, Variablen, Signalen und Prozessen, die das Herzstück eines jeden Linux-Systems bilden. In diesem ausführlichen Leitfaden werden die Grundlagen der Linux Shell, wichtige Konzepte rund um Shell-Skripte sowie praktische Anwendungen vorgestellt, mit denen Nutzer ihren Umgang mit Linux deutlich verbessern können.
Im Fokus steht dabei die Bash Shell, die am weitesten verbreitete und vielseitigste Shell-Variante, doch viele der Konzepte lassen sich auch auf andere Shells übertragen. Die Shell ist im Grunde eine Schnittstelle zwischen dem Nutzer und dem Betriebssystem. Sie nimmt Eingaben entgegen, führt Kommandos aus und zeigt die Ergebnisse an. Bash steht für „Bourne Again SHell“ und ist eine Weiterentwicklung der klassischen Bourne Shell. Sie bietet umfangreiche Möglichkeiten, Befehle zu kombinieren, Eingaben und Ausgaben umzuleiten und komplexe Abläufe zu automatisieren.
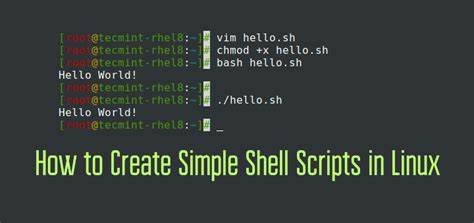
Eine ihrer größten Stärken ist die Fähigkeit, sogenannte Shell-Skripte zu erstellen – also Dateien, in denen eine Reihe von Shell-Befehlen nacheinander ausgeführt werden. Das ermöglicht die Automatisierung von Routineaufgaben und die Wiederverwendung von Abläufen ohne manuelles Eingreifen. Ein Shell-Skript besteht aus ganz normalen Linux-Kommandos, die man auch direkt im Terminal eingibt. Was es von der Eingabe an der Kommandozeile unterscheidet, ist, dass diese Befehle in einer Datei gespeichert und dann automatisch ausgeführt werden können. Das spart Zeit, minimiert Fehlerquellen und sorgt für eine saubere Strukturierung von Arbeitsabläufen.
Bash-Skripte starten meistens mit dem Shebang-Header, der mit „#!“ beginnt und den Pfad zum Interpreter angibt, beispielsweise „#!/bin/bash“. Dadurch weiß das System, wie es das Skript ausführen soll. Vor der ersten Ausführung muss das Skript mit „chmod a+x <skriptname>“ ausführbar gemacht werden. Elektronische Dokumente enthalten dabei unterschiedliche Arten von Zeichenketten, die in Shell-Skripten oft verwendet werden. Bash unterstützt single-quoted und double-quoted Strings.
Der bedeutende Unterschied liegt darin, dass Variablen, die mit einem „$“ beginnen, in double-quoted Strings interpretiert und durch ihren Wert ersetzt werden, in single-quoted Strings dagegen unverändert bleiben. Das ermöglicht eine flexible und kontextsensitive Verarbeitung von Zeichenfolgen. Die Organisation von Ein- und Ausgaben während der Skriptausführung ist für das korrekte Funktionieren von Shell-Skripten zentral. Linux-Prozesse haben standardmäßig drei wichtige Kommunikationskanäle, auch bekannt als Standardstreams. Der Standardinput (STDIN) dient als Eingabekanal, die Standardausgabe (STDOUT) übermittelt die hauptsächlichen Ergebnisse, und die Standardfehler-Ausgabe (STDERR) ist für Fehlermeldungen und Diagnosedaten reserviert.
Diese klare Trennung hilft dabei, die Ausgabe systematisch zu verarbeiten und Fehler leichter zu identifizieren. Wenn beispielsweise ein Programm sowohl reguläre Ergebnisse als auch Fehlermeldungen produziert, können diese voneinander getrennt und individuell weiterverarbeitet oder umgeleitet werden. Eine der mächtigsten Funktionen der Shell ist der Einsatz des Pipe-Operators „|“. Dieser verknüpft die Standardausgabe eines Befehls mit dem Standardeingang eines anderen, sodass mehrere Kommandos zu einer Befehlsfolge kombiniert werden können. Dadurch lassen sich komplexe Datenverarbeitungsprozesse in übersichtliche kleine Schritte zerlegen, die jeweils eine klare Aufgabe übernehmen.
Dieses Konzept hat sich als einer der Grundpfeiler der UNIX-Philosophie und der effizienten Nutzung von Linux etabliert. Shell-Skripte bieten darüber hinaus die Möglichkeit, Programme dynamisch zu gestalten, denn sie unterstützen das Übergeben von Argumenten. Über Variablen wie „$1“ oder „$2“ können Werte in ein Skript hinein übergeben und dort flexibel verwendet werden. Das macht Skripte wiederverwendbar und vielseitig einsetzbar. Des Weiteren stehen Variablen wie „$#“ für die Anzahl der übergebenen Argumente oder „$0“ für den Skriptnamen selbst zur Verfügung, was die Interaktion mit Kommandozeilenparametern erleichtert.
Neben der Eingabe via Kommandozeilenparameter kann auch die Eingabe über Standardinput erfolgen. Manchmal ist es notwendig, mehrere Argumente für einen Befehl zu generieren, die dynamisch aus Datenflüssen stammen. Hier hilft das Kommando „xargs“, das die Daten aus einem Stream aufnimmt und als Argumente für einen Befehl übergibt. Das erweitert die Fähigkeiten der Shell beträchtlich und macht sie noch flexibler in der Verarbeitung von Daten. Die Handhabung von Ausgaben in Shell-Skripten ist ebenfalls vielfältig.
Der größte Vorteil liegt in der Umleitung von Ein- und Ausgaben in Dateien oder zu anderen Befehlen. Dabei werden Operatoren wie „>“ verwendet, um die Standardausgabe in eine Datei zu schreiben, wobei bestehende Dateien überschrieben werden. Mit „>>“ hingegen können Ausgaben an eine bestehende Datei angehängt werden. Für die Eingabe aus Dateien kommt der Operator „<“ zum Einsatz. Bei komplexeren Szenarien kann man auch Standardfehler separat umleiten, meist durch „2>“ für die Fehlerausgabe.
Auch die Kombination beider Ausgaben in eine Datei ist möglich, etwa mit „&>“. Diese Werkzeuge ermöglichen es, die Datenflüsse innerhalb von Skripten perfekt zu steuern und Fehler leichter zu diagnostizieren. Für Situationen, in denen die Ausgabe von Befehlen ignoriert werden soll, bietet Linux den speziellen Null-Gerät-Dateipfad „/dev/null“. Er fungiert als Datenversenker für alle Arten von Ausgaben und Fehlern und befreit so das Terminal und Logs von unnötigen Informationen. Die Verwaltung von Prozessen zählt ebenfalls zu den Kernkompetenzen, die man im Umgang mit Linux Shell und Shell-Skripten lernen sollte.
Jedes laufende Programm erhält eine eindeutige Prozess-ID (PID). Über diese PID lassen sich Prozesse gezielt ansprechen, überwachen oder beenden. Bash stellt dazu besondere Variablen wie „$$“ für die PID des aktuellen Skripts und „$!“ für die PID des zuletzt gestarteten Hintergrundprozesses bereit. Prozesse können im Vordergrund (foreground) oder im Hintergrund (background) laufen. Während der Vordergrundprozess den Benutzer an die Shell bindet, wird bei Hintergrundprozessen die Kontrolle über die Shell sofort wieder freigegeben.
Hintergrundprozesse werden mit dem Anhängen eines „&“ am Befehl gestartet und können mit Befehlen wie „jobs“, „bg“ und „fg“ überwacht und gesteuert werden. Auf diese Weise lassen sich vielfältige Arbeitsabläufe gleichzeitig steuern – eine Fähigkeit, die bei administrativen Aufgaben und automatisierten Abläufen von unschätzbarem Wert ist. Signale sind ein weiteres zentrales Konzept im Linux-Prozessmanagement. Sie dienen dazu, Prozesse zu beeinflussen oder zu steuern, beispielsweise um sie zu unterbrechen oder zum Beenden zu bewegen. Das bekannte Beispiel ist das Beenden eines Programms mit Strg+C, das in Wirklichkeit ein SIGINT-Signal an das Programm sendet.
Mit dem Kommando „kill“ lassen sich ebenfalls Signale an Prozesse senden, um sie kontrolliert zu terminieren oder besondere Aktionen auszuführen. Für eine noch feinere Steuerung gibt es speziell definierte Signals wie SIGUSR1 und SIGUSR2, die Entwickler für individuell anpassbare Aufgaben in ihren Programmen verwenden können. Shell-Skripte können Signalisierung und Reaktion auf Signale mit dem „trap“-Befehl nutzen. Dadurch kann ein Skript beispielsweise auf bestimmte Signale reagieren und eigene Funktionen ausführen, was die Kontrolle und Flexibilität von Skripten enorm erhöht. Ein weiterer wichtiger Aspekt der Arbeit in der Shell sind Umgebungsvariablen.
Sie werden verwendet, um Konfigurationen und Informationen an Programme und Skripte weiterzugeben. Umgebungsvariablen haben üblicherweise Großbuchstaben und Unterstriche im Namen, wie etwa HOME für das Benutzerverzeichnis oder SHELL für die aktuell verwendete Shell. Shell-Variablen, die ohne „export“ definiert werden, bleiben auf die aktuelle Session beschränkt, während exportierte Variablen auch von Subprozessen verwendet werden können. Alternativ lassen sich Variablen für einzelne Befehle dynamisch setzen, ohne die Umgebung dauerhaft zu beeinflussen. Die Kombination all dieser Konzepte macht die Linux Shell zu einem flexiblen und mächtigen Werkzeug.
Für Anfänger scheint die Arbeitsweise der Shell anfangs möglicherweise verwirrend, doch je mehr man sich mit den einzelnen Bausteinen auseinandersetzt, desto leichter fällt die Nutzung. Shell-Skripte eröffnen Wege zur Automation, Effizienz und Systemsteuerung, die ohne die Kommandozeile schlichtweg nicht möglich wären. Wer Shell-Skripte schreibt, sollte sich außerdem die Mühe machen, die Skripte mit Tools wie ShellCheck zu überprüfen. Diese helfen dabei, Fehler und Stilprobleme früh zu erkennen und bewahren dadurch vor unerwarteten Problemen im Einsatz. Zusammenfassend lässt sich sagen, dass die Linux Shell und die damit verbundenen Skriptmöglichkeiten eine unverzichtbare Grundlage für die Arbeit mit GNU/Linux darstellen.
Indem man das Zusammenspiel von Befehlen, Variablen, Ein-/Ausgaben, Prozessen und Signalen beherrscht, steigt die Produktivität enorm. Diese Grundlagen sind der Schlüssel, um das volle Potenzial des Systems auszuschöpfen – egal, ob man Administrator, Entwickler oder Hobby-Nutzer ist. Es lohnt sich, Zeit in das Lernen dieser Fähigkeiten zu investieren, um langfristig zeitsparende und effiziente Workflows zu gestalten und Linux umfassend zu verstehen.