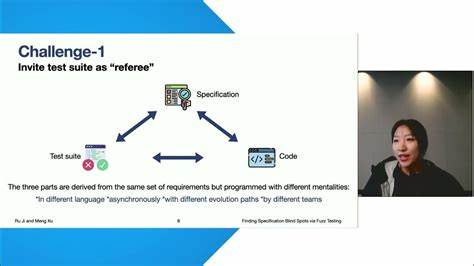
In der Welt der Softwareentwicklung nimmt das Testen eine zentrale Rolle ein, um die Zuverlässigkeit und Sicherheit komplexer Systeme zu gewährleisten. Besonders in der Systementwicklung, die auf verteilte Datenbanken und hochperformante Transaktionssysteme setzt, gewinnt das automatisierte Finden von Fehlern an Bedeutung. Hier kommen Fuzzer ins Spiel – Werkzeuge, die durch automatisierte und oft zufällig generierte Eingaben Fehlerzustände provozieren und somit potenzielle Schwachstellen aufdecken. Doch so mächtig diese Technik auch ist, auch sie hat ihre Grenzen, sogenannte Blindspots. Das jüngst veröffentlichte Beispiel aus dem TigerBeetle-Projekt illustriert eindrucksvoll, wie selbst intensive Fuzzer-Tests dennoch gravierende Fehler übersehen können und wie die jepsen-Analyse genau diese Problemfelder sichtbar macht.
TigerBeetle ist eine verteilte Transaktions-Engine, die sich durch starke Datenintegrität und hohe Parallelität auszeichnet. Aufgrund der Komplexität der beteiligten Komponenten wurde bereits einiges an Entwicklungsarbeit und Fuzzing in die verschiedenen Module investiert. Insbesondere der Abfrage-Engine wurde durch mehrere eigenständige Fuzzer große Aufmerksamkeit zuteil. Die Annahme war, dass durch solch breitflächige Testabdeckung kritische Fehler in diesem Teil des Systems kaum noch existieren sollten. Doch genau hier zeigte das unabhängige Testframework Jepsen überraschende Mängel auf.
Jepsen, bekannt für rigorose und tiefschürfende Tests verteilter Systeme, führte eine Reihe von Szenarien mit spezifischen Intersektionen von Abfragen im TigerBeetle-System durch. Dabei fiel auf, dass bestimmte Transfers, die zuvor erfolgreich erstellt und vom Cluster bestätigt wurden, in späteren Abfrageergebnissen fehlten. Dieses Verhalten war nicht nur inkorrekt, sondern auch schwer nachvollziehbar, da in der Vergangenheit ausführliches Fuzzing genau diese Komponente abgedeckt hatte. Wenn eine Komponente gleich von vier verschiedenen Fuzzern getestet wird, erwartet man eigentlich, dass solche Fehler entdeckt werden – aber das war in diesem Fall nicht so. Die Analyse zeigte, dass das Problem in der Art und Weise lag, wie die Fuzzer ihre Testinputs generierten beziehungsweise wie diese Inputs strukturiert waren.
Die Fuzzer verfolgten das Ziel, eine komplexe Arbeitslast mit vorgeplanten Abfragen zu erzeugen, wobei jede Transaktion genau einem vorab definierten Filterkriterium zugeordnet war. Diese Arbeitsteilung sollte die Komplexität der Testlogik reduzieren, indem sichergestellt wurde, dass Eingaben und erwartete Ausgaben zueinander passen, ohne eine umfassende Modellierung des Query-Systems vornehmen zu müssen. Doch genau hier wurde eine kritische Schwäche eingebaut: Die erzeugten Testdaten lagerten sich stets in klar getrennten, nicht überlappenden Zustandsräumen ab, was dazu führte, dass bestimmte Schnittmengen von Indexabfragen praktisch nie getestet wurden. Diese Strukturierung führte zu einem blinden Fleck in der Testabdeckung, da die scheinbar unabhängigen Abfragen, die eigentlich verschiedene Datenbereiche hätten überschneiden können, durch das feste Schema der Eingabeerstellung strikt voneinander getrennt blieben. Das bedeutet konkret, dass das Fuzzer-System keine Szenarien erzeugte, in denen mehrere Indexabfragen überlappend operierten und somit auch keine Tests durchzuführen, die das Identifizieren von Fehlern in der Schnittstellenlogik dieser Mehrfachabfragen begünstigen.
Dieser blinde Fleck wurde erst durch das unabhängige, modellbasierte und zufallsorientierte Vorgehen von Jepsen sichtbar. Nach der Aufdeckung dieses Problems wurde die Fuzzer-Strategie umgestellt. Anstelle vorher festgelegter, homogener Abfragen wurden nun zufällig generierte Transaktionen mit beliebigen Attributwerten erstellt. Darüber hinaus wurde das Modell zur Validierung der Ergebnisse erheblich detaillierter gestaltet, was nun alle relevanten Felder und deren Schnittmengen abdeckt und so präzisere Prüfungen ermöglicht. Erst durch diesen freien, weniger strukturierten und umfassenderen Ansatz konnten die Probleme zuverlässig reproduziert und somit adressiert werden.
Die eigentliche Ursache des Fehlers lag in der Implementierung des sogenannten Zig-Zag Merge Join Algorithmus, der für die effiziente Schnittmengenbildung bei mehreren Indexen verantwortlich ist. Bei dieser Methode wird zwischen mehreren Iteratoren synchronisiert, die jeweils einen Index abarbeiten und versuchen, gemeinsame Ergebnisse herauszufiltern. Kommt es zu einem Sprung einer Iteration über den anderen Iterator – das sogenannte Probing – ändern sich die Grenzen des zu durchsuchenden Wertebereichs dynamisch. Hier führte eine inkorrekte Randbedingungsprüfung dazu, dass der Algorithmus fälschlicherweise annahm, seine Suche bereits abschließen zu können, obwohl noch relevante Daten vorlagen. Dies resultierte in abgeschnittenen Ergebnismengen und damit in falschen Abfrageergebnissen.
Interessanterweise trat dieser Fehler nur in Situationen auf, in denen mehrere sekundäre Indexe kombiniert abgefragt und die Grenzen ihrer Iterationsbereiche verschoben wurden. Die durch die vorherigen Fuzzer erzeugten Teststellungen waren aber von vornherein so beschaffen, dass diese komplexen Szenarien nicht in Erscheinung traten. Das zeigt exemplarisch, wie wichtig es ist, nicht nur viele Tests, sondern vor allem auch diversifizierte und realitätsnahe Testszenarien in komplexen Systemen zu haben. Die Schlussfolgerungen aus dem TigerBeetle-Jepsen-Zusammenspiel sind weitreichend. Fuzzer sind mächtige Werkzeuge, die mit systematischer Inputerzeugung echte Fehler aufspüren können.
Doch sie sind auch Werkzeuge mit begrenztem Sichtfeld. Ihre Effizienz beruht häufig auf intelligentem Einschränken der möglichen Eingänge, um den state space sinnvoll zu durchforsten. Diese Einschränkungen können aber dazu führen, dass gerade die interessanten, fehlerverursachenden Zustände ungetestet bleiben. Der sogenannte Blindspot ist keine technische Schwäche der Fuzzer an sich, sondern eine Folge von Arbeitslast-Designentscheidungen und der zugrunde liegenden Testmodellierung. Eine wichtige Lehre ist deshalb, Testansätze zu kombinieren: Von gezieltem, strukturiertem Fuzzing, das bekanntes Risiko fokussiert, bis hin zu explorativem, breit gefächertem Zufallsfuzzing und modellbasierten Tests, die auf umfassender Simulation der Systemlogik beruhen.
Nur durch solche hybriden Ansätze kann man die tatsächliche Qualität und Sicherheit verteilter Systeme wirklich einschätzen und verbessern. Ein weiterer Aspekt ist die Rolle von unabhängigen, externen Prüfern und Tools wie Jepsen, die mit anderen Perspektiven und Methoden testen. Gerade in verteilten Systemen, in denen Nebenläufigkeiten, Timing und Failover komplexes Verhalten erzeugen, kann der frische Blick von außen und ein anderes Testkonzept entscheidende Fehlstellen aufzeigen. Die Zusammenarbeit von TigerBeetle mit Jepsen verdeutlicht, dass zusätzliche, analytische Testmethoden nicht nur Fehler finden, sondern auch dazu beitragen, das interne Testregime weiter zu verfeinern und die eigenen Blindspots zu erkennen. TigerBeetle hat nach der Fehlerbehebung die Fuzzer angepasst und die Testlandschaft mit neuen, weniger strukturierten Arbeitslasten ergänzt.
Die Abfragen wurden mit realistischeren Zufallswerten abgeglichen und die Genauigkeit der Referenzmodelle stetig erweitert. Gerade diese iterative Vorgehensweise – Test, Analyse, Modellanpassung, erneuter Test – ist Kennzeichen moderner Softwarequalitätssicherung in komplexen Systemen. Abschließend lässt sich sagen, dass Fuzzer Blindspots ein ganz natürlicher Teil moderner Testscapes sind, die jedoch mit Bedacht gehandhabt werden müssen. Entwickler und Tester sollten sich der Einschränkungen bewusst sein, die aus Designentscheidungen im Testumfeld erwachsen. Nur so können die Vorteile automatischer Fehlerfindung voll ausgeschöpft und schwer fassbare Fehler effektiv aufgedeckt werden.
Wer sich intensiv mit verteilten Systemen, Datenbanken oder Transaktions-Engines beschäftigt, dem sei empfohlen, Tools wie Jepsen nicht nur als „letzten Schritt“ zu betrachten, sondern als festen Bestandteil im Testprozess zu etablieren. Es sind gerade diese umfassenden, systematischen Prüfmethoden, die das Vertrauen in Systeme steigern und dabei helfen, greifbare Verbesserungen in Stabilität und Korrektheit zu erzielen. Die Geschichte von TigerBeetle und Jepsen erzählt somit nicht nur von einem gefundenen Fehler, sondern von einem ganzheitlichen Ansatz zur Fehlervermeidung und Qualitätssicherung, der in der heutigen Welt verteilter Systeme unverzichtbar ist. Fuzzer allein sind keine Zauberlösung – sie sind Teil eines Werkzeugkastens, der durch vielfältige Methoden und Perspektiven ergänzt werden muss, um den wachsenden Anforderungen an moderne Software gerecht zu werden.