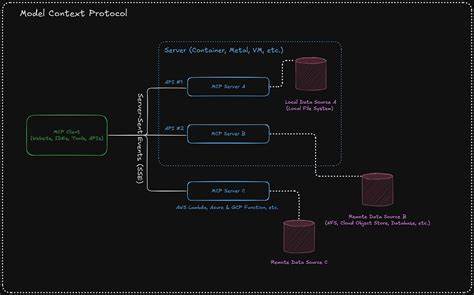
In der heutigen Zeit, in der künstliche Intelligenz und große Sprachmodelle (LLMs) immer stärker in den Alltag und in professionelle Anwendungen integriert werden, gewinnt die effiziente Verwaltung von Daten und Ressourcen zunehmend an Bedeutung. Eine der wichtigsten Herausforderungen besteht darin, den Kontext und die Token-Budgets optimal zu nutzen, ohne dabei unnötig Kapazitäten zu verschwenden. Genau hier spielt das Thema MCP Ressourcen als Mittel zum Caching eine entscheidende Rolle und sorgt für eine völlig neue Effizienzstufe in der Implementierung von KI-gestützten Systemen. MCP, kurz für Model-Centered Protocol, ist ein Protokoll, das vor allem dazu dient, eine standardisierte Schnittstelle für den Umgang mit Tools und deren Ergebnissen im KI-Kontext zu schaffen. Dabei steht keineswegs die reine Lesbarkeit durch das Sprachmodell im Vordergrund, sondern vielmehr die strukturierte und effiziente Kommunikation zwischen Tools, Datenquellen und dem LLM.
Das bedeutet, dass MCP die Grundlage bildet, um Werkzeuge so zu integrieren, dass die Ausgabe nicht nur für die Maschine verständlich ist, sondern auch optimal auf das jeweilige Sprachmodell abgestimmt wird. Ein fundamentaler Bestandteil dieses Protokolls sind die sogenannten MCP Ressourcen. Diese Ressourcen dienen vor allem als Cache für große Dokumente und Datensätze, die bei komplexen Abfragen, beispielsweise in Retrieval-Augmented Generation (RAG), immer wieder benötigt werden. Ohne eine effiziente Nutzung dieser Ressourcen wäre die Token-Budgetierung eines LLMs schnell ausgelastet, was dazu führt, dass die Modelle entweder ungenaue Antworten liefern oder schlichtweg nicht performant genug sind. RAG-Methoden nutzen in der Regel umfangreiche Dokumente, die über verschiedene Tools oder Datenquellen abgefragt werden.
Dabei ist es nicht ungewöhnlich, dass sich dieselben Inhalte mehrfach im Kontext wiederholen. Wenn ein Client die MCP Ressourcen nicht unterstützt und stattdessen jede Textpassage komplett neu in den Kontext einfügt, verursacht das eine erhebliche Verschwendung von Token. Diese unnötigen Redundanzen führen zu längeren Bearbeitungszeiten, höheren Kosten und letztlich zu einem schlechteren Benutzererlebnis. Die Kunst und Herausforderung liegt darin, diese RAG-Ergebnisse so zu verwalten, dass Duplikate vermieden werden und das System mit bereits geladenen Inhalten arbeiten kann. MCP Ressourcen stellen dafür eine Art Inhaltsverzeichnis mit Verweisen dar, das eine schnelle Wiederverwendung bereits geladener Dokumente erlaubt.
Durch Verwendung von URI-basierten Schlüsseln kann genau protokolliert werden, welche Dokumente bereits im Cache liegen und müssen nicht erneut an das Modell übergeben werden. Das steigert nicht nur die Effizienz enorm, sondern sorgt auch für eine deutlich bessere Skalierbarkeit komplexer Anwendungen. Was bedeutet das konkret für die Entwicklung von MCP-Clients? Ein leistungsfähiger Client muss in der Lage sein, eine Liste von bereits verwendeten Ressourcen zu verwalten. Wenn neue Tool-Aufrufe erfolgen, werden nur die IDs der Ressourcen als Ergebnis zurückgegeben und nicht der komplette Textblock. Dieser kann separat, beispielsweise in einem zusätzlichen Prompt oder Backend-System, vorgehalten werden und bei Bedarf zu Informationszwecken abgerufen werden.
Dieses Vorgehen ähnelt einem sorgfältig gepflegten Cache, der die Netzwerk- und Rechenressourcen schont. Ohne diese ressourcenorientierte Architektur sind Anwendungen gezwungen, große Datenmengen immer wieder neu in das Modell einzuspeisen. Das nicht nur erhöht die Latenzzeiten deutlich, es führt auch zu einem sehr ineffizienten Verbrauch des Token-Kontingents – eine bedeutsame Limitierung bei der Arbeit mit vielen aktuellen Dienstleistern und Anbietern von LLMs. Darüber hinaus verdeutlicht die Tatsache, dass einige der großen Anbieter wie Anthropic oder OpenAI in ihren APIs keine Unterstützung für MCP Ressourcen implementiert haben, wie wichtig es ist, dass Entwickler selbst in die mittlere Schicht eingreifen und smarte Clients bauen, die diese Funktion aktiv integrieren und nutzen. Wer auf vollständige MCP-Unterstützung verzichtet, riskiert nicht nur Performance-Einbußen, sondern häufig auch eine mangelnde Produktreife, die im professionellen Umfeld zu einem Ausschlusskriterium werden kann.
Ein weiterer spannender Aspekt ist die Trennung zwischen der Darstellbarkeit der MCP-Daten durch das LLM und der internen Prozesslogik des Clients. MCP ist nicht dazu da, vom LLM direkt interpretiert oder verstanden zu werden. Vielmehr übernimmt der MCP-Client die Aufgabe, die standardisierten Datenobjekte des Protokolls in ein Format zu übersetzen, das das jeweilige Modell möglichst effizient und zielgerichtet verarbeiten kann. Es reicht also nicht aus, rohe MCP Daten einfach in einen Prompt zu werfen – der Client muss die Schnittstelle zwischen Toolausgaben und Modell optimal gestalten, um den größtmöglichen Nutzen aus der Investition in hochwertige Trainingsdaten und Modelle zu ziehen. In der Praxis bedeutet das eine klare Rollenverteilung: MCP definiert, wie Daten und Tools miteinander kommunizieren, der Client optimiert diese Kommunikation und das Modell liefert letztlich die Ergebnisse.
Dies ermöglicht eine flexible, aufbauende Architektur, die sich an die Bedürfnisse verschiedener Anwendungsfälle anpassen lässt und gleichzeitig eine sehr hohe Effizienz hinsichtlich der Token-Nutzung sicherstellt. Die Bedeutung von MCP Ressourcen für das Caching spiegelt sich auch in der vermehrten Nutzung minimalistischer Client-Implementierungen wider, die genau dieses Prinzip verfolgen. Sie bieten oft eine schlanke, aber hochfunktionale Referenzbasis, um nicht nur Protokollkonformität herzustellen, sondern vor allem eine spürbare Verbesserung der Anwendungsperformance zu erzielen. Insbesondere für Entwickler, die mit komplexen Retrieval-Mechanismen und großen Datensätzen arbeiten, stellen solche Lösungen eine wertvolle Grundlage dar. Zusammengefasst zeigt sich, dass MCP Ressourcen unverzichtbar sind, um die Token-Budgets moderner Sprachmodelle optimal auszunutzen und redundante Datenübertragungen zu vermeiden.
Für Nutzer und Entwickler von KI-Anwendungen bedeutet das einen nachhaltigen Leistungsschub und eine verbesserte Skalierbarkeit. Wer hier den Einsatz von MCP Ressourcen vernachlässigt, verschenkt nicht nur wertvolle Rechenzeit und Ressourcen, sondern verhindert auch die reibungslose Integration von Retrieval-Methoden, die für viele produktive KI-Anwendungen unverzichtbar geworden sind. Die Zukunft der KI-gesteuerten Anwendungen liegt deshalb untrennbar in der intelligenten Nutzung von Protokollen wie MCP mit Fokus auf effizientes Caching. Wer seine Systeme zukunftssicher und performant gestalten will, sollte also unbedingt auf die Unterstützung und Umsetzung von MCP Ressourcen setzen und somit den Grundstein für smarte, ressourcenschonende KI-Prozesse legen.