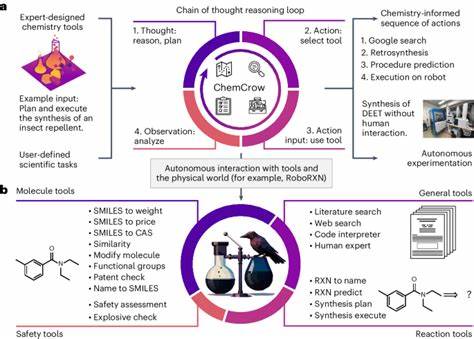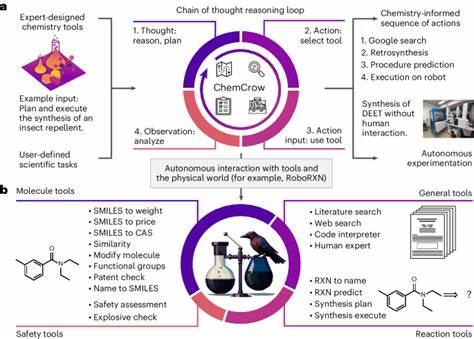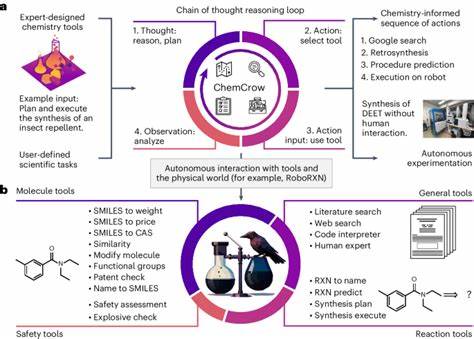
In jüngster Zeit haben große Sprachmodelle, auch bekannt als Large Language Models (LLMs), die öffentliche Aufmerksamkeit auf sich gezogen. Ihre Fähigkeit, natürliche Sprache zu verarbeiten und komplexe Aufgaben zu lösen, die nicht explizit in ihrem Training vorgesehen waren, hat Erwartungen und Diskussionen gleichermaßen angefacht – insbesondere in wissenschaftlichen Disziplinen wie der Chemie. Es stellt sich die Frage: Sind diese KI-Systeme in der Lage, die Expertise menschlicher Chemiker zu erreichen oder sogar zu übertreffen? Und falls ja, welche Implikationen ergeben sich daraus für Forschung, Lehre und den praktischen Einsatz in Laboren? Die Antwort darauf ist weder simpel noch eindeutig, doch ein neuer systematischer Ansatz gibt spannende Einblicke. Die Chemie als Forschungsfeld lebt von der Interpretation, Analyse und Synthese von komplexen Informationen. Obwohl viele chemische Daten in strukturierten Datenbanken vorliegen, sind die meisten Erkenntnisse und Wissensfortschritte in Textform verfasst – in Fachartikeln, Lehrbüchern oder Laborprotokollen.
Große Sprachmodelle, die auf umfangreichen Textkorpora trainiert werden, verfügen daher über ein enormes Potenzial, um diese Wissensbasis umfassend zu verstehen und zu nutzen. Doch bisher gab es wenig systematische Vergleiche zwischen der Leistungsfähigkeit von LLMs und der von menschlichen Experten in der Chemie. Im Mai 2025 wurde das ChemBench-Projekt vorgestellt – ein eigens entwickeltes Benchmarking-Framework, das die chemischen Kenntnisse und das logische Denken moderner Sprachmodelle mit denen professioneller Chemiker vergleicht. Die Grundlage des Projekts bildet eine umfassende Sammlung von mehr als 2.700 Frage-Antwort-Paaren, die zu Themen aus verschiedenen Bereichen der Chemie entwickelt und kuratiert wurden.
Diese Fragen reichen von grundlegenden Kenntnissen über analytische und technische Chemie bis hin zu komplexen Aufgaben, die chemische Intuition erfordern. Interessanterweise zeigte die Auswertung mit ChemBench, dass die besten getesteten Modelle in der Lage sind, durchschnittlich besser als die besten menschlichen Experten abzuschneiden. In bestimmten Bereichen wie technischen und allgemeinen Chemiethemen liefern sie sogar sehr beeindruckende Ergebnisse. Modelle wie das proprietäre „o1-preview“ und das Open-Source-Modell „Llama-3.1-405B-Instruct“ erzielten Resultate, die teilweise nahezu doppelt so gut waren wie jene der professionellen Chemiker, die im Rahmen der Studie Fragebögen beantworteten – teilweise sogar unter Nutzung von unterstützenden Werkzeugen wie Websuchen und chemischer Zeichensoftware.
Trotz dieser Fortschritte offenbaren die Modelle zugleich signifikante Schwächen. Wissensintensive Aufgaben, die genaue Fakten oder tiefgreifende wissenschaftliche Details erfordern, fallen den LLMs schwer, selbst wenn diese mit externen Informationsquellen ausgestattet sind. Die Ursache liegt darin, dass manche wichtigen Daten nur in spezialisierten Datenbanken und nicht frei zugänglich in der wissenschaftlichen Literatur zu finden sind. Während menschliche Experten oft auf solche Ressourcen zugreifen, bleiben LLMs derzeit limitiert, wenn sie nicht speziell darauf trainiert oder entsprechend integriert werden. Auch komplexere chemische Aufgaben, wie die Analyse von Molekülstrukturen zur Bestimmung von Kernspinresonanz-Signalen oder die Anzahl möglicher Isomere, stellen für die Modelle eine Herausforderung dar.
Dies liegt häufig daran, dass viele LLMs nicht über eine intrinsische, strukturverständige Repräsentation von Molekülen verfügen, sondern eher auf Mustern aus ihrer Trainingsmenge reagieren. Dadurch ist ihre Fähigkeit, über reine Daten hinaus chemisches Reasoning zu leisten, eingeschränkt. Ein weiteres bedeutendes Problem ist die Tendenz der Modelle, überkonfidente Vorhersagen zu machen – also Antworten mit großer Sicherheit zu liefern, selbst wenn sie falsch sind. Ein zuverlässiges Selbstbewusstsein der Modelle bezüglich ihrer Kenntnisse und Unsicherheiten ist aber gerade für den Einsatz im sicherheitsrelevanten Bereich der Chemie, etwa bei Sicherheitsbewertungen von Substanzen oder toxikologischen Fragestellungen, unverzichtbar. Neben den rein fachlichen Aspekten zeigt ChemBench auch, dass LLMs Schwierigkeiten haben, menschliche Präferenzen oder chemische Intuition zu replizieren.
Bei Fragestellungen zu bevorzugten Molekülen, die typischerweise auf Erfahrungswissen und subtilen Überlegungen beruhen – zum Beispiel in der frühen Phase der Wirkstoffentwicklung – tendieren die Modelle eher zu zufälligen Entscheidungen als zu einer konsistenten Übereinstimmung mit Chemikerurteilen. Diese Erkenntnisse werfen einen spannenden Blick auf die zukünftige Rolle von KI in der Chemie. Einerseits steht außer Frage, dass LLMs schon heute in der Lage sind, viele Routinefragen schnell und verlässlich zu beantworten und bei der Literaturrecherche oder der Generierung von Hypothesen eine enorme Unterstützung bieten können. Andererseits unterstreicht die Studie, dass menschliche Kontrolle und kritisches Denken im Umgang mit KI-generierten Ergebnissen weiterhin notwendig sind. Darüber hinaus bedarf es spezieller Modelle, die mit chemisch-spezifischem Wissen trainiert werden und die mit Datenbanken interagieren können, um ihre Wissenslücken zu schließen.
Das Design von hybriden Systemen, die KI und Expertenwissen geschickt verbinden, könnte die Zukunft prägen – sogenannte „Copilot“-Systeme, die in der Lage sind, Chemiker bei ihrem täglichen Arbeiten und Forschen zu begleiten. Im Bereich der chemischen Ausbildung werden sich ebenfalls Veränderungen ergeben. Da Modelle routinemäßig Fakten abrufen und einfache Probleme lösen können, müssen Lehrpläne und Prüfungsformate mehr Gewicht auf das Verständnis, kritische Denken und die Fähigkeit zur Anwendung chemischer Prinzipien legen, anstatt auf das pure Auswendiglernen. So könnten Chemie-Studierende künftig lernen, besser mit KI-Werkzeugen zusammenzuarbeiten und deren Ergebnisse kritisch zu hinterfragen. Die Einführung von ChemBench als offen zugängliches Benchmarking-Werkzeug ist ein wichtiger Schritt, um die Fortschritte im Bereich der chemischen Künstlichen Intelligenz kontrolliert zu messen und transparent zu dokumentieren.
Die Vielfalt der Fragestellungen und ihrer Schwierigkeit stellt dabei sicher, dass die Modelle ganzheitlich getestet werden und nicht nur auf spezifische Datensätze mit begrenztem Anwendungsrahmen optimiert sind. Zusammenfassend zeigen die aktuellen Untersuchungen, dass große Sprachmodelle das Potenzial besitzen, menschliche Experten in der Chemie in vielen Bereichen zu übertreffen, insbesondere in quantitativen und wissensbasierten Aufgaben. Dennoch führen Begrenzungen beim chemischen Reasoning, fehlende strukturierte molekulare Repräsentationen und mangelnde Fähigkeit zur Selbsteinschätzung zu einem vorsichtigen Umgang mit den Ergebnissen. Die Zukunft der chemischen Forschung und Lehre wird durch die Kombination aus menschlicher Expertise und fortschrittlicher KI geprägt sein – eine Zusammenarbeit, die Synergien hebt und die Grenzen des Machbaren neu definiert. Die rapide Entwicklung der Technologie erfordert gleichzeitig die Beachtung ethischer Implikationen.