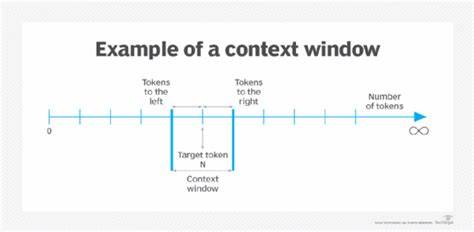
Transformers haben die Welt der künstlichen Intelligenz und des maschinellen Lernens revolutioniert. Sie sind die Grundlage für viele moderne Sprachmodelle und Anwendungen, die natürliche Sprache verstehen und generieren können. Ein zentrales Konzept bei der Arbeit mit Transformers ist das sogenannte Kontextfenster. Dieses definiert den Umfang des Textes, den das Modell zugleich betrachten und verarbeiten kann. Doch was genau verbirgt sich hinter dem Begriff Kontextfenster, wie funktioniert es, und warum ist es so wichtig? Zudem stellt sich die Frage, wie man dieses Kontextfenster effektiv verlängern kann, um noch umfangreichere und komplexere Informationen zu verarbeiten.
Dieser Artikel widmet sich genau diesen Fragestellungen und bietet eine umfassende Übersicht über das Thema. Im Kern beschreibt das Kontextfenster die maximale Anzahl an Token, also einzelnen sprachlichen Einheiten wie Wörtern oder Satzzeichen, die ein Transformer-Modell in einem Durchgang verarbeiten kann. Diese Begrenzung ergibt sich aus der Architektur des Modells und hat entscheidenden Einfluss darauf, wie viel Text gleichzeitig berücksichtigt werden kann. Bei vielen Standardmodellen der ersten Generation liegt diese Zahl typischerweise bei 512 oder 1024 Token, bei neueren Varianten manchmal bei 2048 oder 4096 Token. Die Grenzen des Kontextfensters sind dabei entscheidend für die Leistungsfähigkeit bei Aufgaben wie Textverständnis, Konversationen oder längerer Textgenerierung.
Ist ein Text länger als das Kontextfenster, muss das Modell Teile des Textes ignorieren oder muss aufwendig mit Segmentierungen arbeiten, was die Genauigkeit und Kohärenz beeinträchtigen kann. Der Hintergrund dieser Begrenzung liegt in der Art und Weise, wie Transformer-Modelle aufgebaut sind. Sie verwenden sogenannte Selbst-Attentionsmechanismen, die dafür sorgen, dass jedes Token im Kontext jedes anderen Tokens innerhalb des Fensters betrachtet wird. Das führt zu einer quadratischen Komplexität bezüglich der Tokenanzahl – das heißt, wenn die Zahl der Token verdoppelt wird, vervierfacht sich der Rechenaufwand. Diese Eigenschaft macht es schwierig, das Kontextfenster ohne wesentlich höhere Rechenressourcen massiv zu erweitern.
Deshalb stellt die praktische Erweiterung des Kontextfensters bis heute eine Herausforderung dar, die aktiv erforscht wird. Die Bedeutung eines großen Kontextfensters kann nicht hoch genug eingeschätzt werden. Gerade bei komplexen Dokumenten, wissenschaftlichen Texten, juristischen Akten oder längeren Dialogen wird die Fähigkeit, Kontext über viele Absätze oder Seiten hinweg zu verstehen, entscheidend. Ein eng begrenztes Kontextfenster kann hier dazu führen, dass wichtige Zusammenhänge verloren gehen oder die Antwort nicht auf alle relevanten Informationen eingeht. Auch im Bereich von Aufgaben wie maschineller Übersetzung, Textzusammenfassung oder der Analyse von Büchern spielt das Kontextfenster eine zentrale Rolle für die Qualität und Tiefe der Ergebnisse.
Eine Möglichkeit, um mit der Begrenzung umzugehen, besteht darin, Texte in kleinere Abschnitte aufzuteilen und diese einzeln vom Modell verarbeiten zu lassen. Anschließend werden die Ergebnisse zusammengeführt. Diese Herangehensweise bringt aber ihren eigenen Aufwand und technische Komplexität mit sich. Bei längeren Inhalten kann es auch zu Inkonsistenzen kommen, da das Modell nur fragmentarisch den Zusammenhang erfassen kann. Eine Reihe von innovativen Ansätzen hat das Ziel, die Grenzen des Kontextfensters deutlich zu erweitern.
Hierbei kommen sowohl architektonische Verbesserungen als auch alternative Speicher- und Aufmerksamkeitsmechanismen zum Einsatz. Beispielsweise experimentieren Forscher mit sparsamer oder langfristiger Aufmerksamkeit, wobei das Modell seine Aufmerksamkeit gezielter auf relevante Abschnitte lenken kann und nicht jeden Token mit allen anderen gleichzeitig vergleicht. Dies reduziert den Rechenaufwand erheblich, ohne wichtige Informationen zu vernachlässigen. Eine weitere vielversprechende Königsdisziplin sind sogenannte hierarchische Modelle. Dabei wird der Text nicht auf einer flachen Ebene verarbeitet, sondern es entstehen hierarchische Strukturen, in denen zuerst kleinere Textstücke in sinnvolle Repräsentationen verwandelt werden.
Diese werden dann als kompakte Zusammenfassungen in übergeordnete Ebenen eingespeist. So kann das Modell über viele Iterationen hinweg Kontext effektiv speichern und nutzbar machen, ohne das gesamte Textvolumen auf einmal laden zu müssen. Darüber hinaus setzt die Praxis zunehmend auf hybride Systeme, die Transformer-Modelle mit externen Speichermöglichkeiten verbinden. Dabei kann das Modell wichtige Informationen in einer Datenbank oder einem speziellen Langzeitspeicher ablegen und bei Bedarf abrufen. So lässt sich ein quasi unbegrenztes Kontextvolumen abbilden, das über das native Fenster des Modells hinausgeht.
Solche Ansätze werden insbesondere im Bereich von Chatbots und persönlichen Assistenten verwendet, um Verlauf, Vorlieben und Konversationen besser nachvollziehen zu können. Technische Anpassungen an der Basisarchitektur von Transformern können ebenfalls zur Verlängerung des Kontextfensters beitragen. Einige Entwickler verändern die Art der Positionskodierung, die das Modell über die Reihenfolge der Token informiert. Alternativ verwenden sie Verfahren, die die Aufmerksamkeit nicht strikt positionell gestalten, sondern flexibler und offener gegenüber längeren Texten. Auch sparsames Sampling von Token oder selektive Eingabe von Informationen können helfen, die verfügbare Kapazität besser auszunutzen.
Neben der Architektur selbst spielen die verfügbaren Hardware-Ressourcen eine entscheidende Rolle. Die Verarbeitung großer Kontextfenster erfordert enorme Rechenleistung und große Speicherkapazitäten. Fortschritte in der GPU- und TPU-Technologie sowie optimierte Softwarelösungen tragen dazu bei, längere Texte effizient zu verarbeiten. Ebenso wird an der Verteilung der Verarbeitung auf mehrere Geräte gearbeitet, um die Grenzen einzelner Maschinen zu überwinden. Für Entwickler ist die bewusste Gestaltung des Kontextfensters ein Balanceakt zwischen Leistungsfähigkeit und Ressourcenaufwand.
Je größer das Fenster, desto mehr Computerkapazität ist erforderlich und desto komplexer wird das Training des Modells. Dennoch zeigen viele Use Cases, dass die Investition in größere Kontextfenster besonders bei anspruchsvollen Anwendungen wie juristischer Analyse, wissenschaftlichem Dialog oder detailreicher Kreativarbeit lohnt. Abschließend lässt sich sagen, dass das Kontextfenster bei Transformern ein fundamentales Element für das Verständnis und die Qualität der Ergebnisse ist. Die ständige Forschung und Entwicklung zielen darauf ab, diese Grenzen immer weiter nach oben zu verschieben. Wer diese Mechanismen versteht und gezielt einsetzt, kann davon profitieren, Modelle mit größerem Kontextfenster zu nutzen oder selbst Ansätze zur Erweiterung zu verfolgen.
Die Zukunft verspricht Transformers, die über tausende oder gar zehntausende Token hinweg effizient und kohärent arbeiten können – eine entscheidende Voraussetzung für die nächsten Generationen von künstlicher Intelligenz und deren vielfältige Anwendungen.