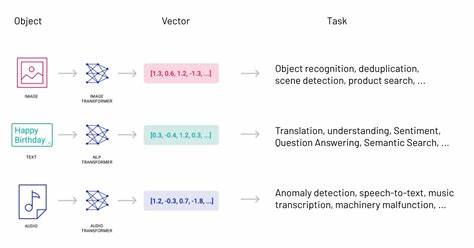
Die Sprachsynthese gehört seit Jahrzehnten zu den spannendsten Feldern der Künstlichen Intelligenz, doch traditionelle Technologien stoßen immer wieder an ihre Grenzen, wenn es um Natürlichkeit, Emotion und Kontextverständnis geht. Mit der Bland.ai TTS Engine zeichnet sich nun eine neue Ära ab, die das Konzept der computergenerierten Sprache grundlegend verändert. Basierend auf der innovativen Architektur großer Sprachmodelle (Large Language Models, LLMs) verspricht Bland.ai eine transformative Entwicklung im Bereich der Text-zu-Sprache-Systeme und setzt damit neue Maßstäbe in puncto Ausdrucksstärke, Stilvielfalt und Authentizität.
Anders als klassische TTS-Systeme, die typischerweise einem sequentiellen Prozess folgen — angefangen bei der Textnormalisierung über phonemische Umwandlungen, Prosodiemodellierung bis hin zur Wellenerzeugung — verbindet Bland.ai Textverstehen und Spracherzeugung in einer holistischen, generativen Operation. Während traditionelle Engines die mechanische Umwandlung von Text in Sprache automatisieren, betrachtet Bland.ai den Vorgang als ein kreatives Zusammenspiel von Bedeutung und Ausdruck. Dabei nutzt die Plattform die komplementäre Stärke moderner Transformer-Modelle, die primär für natürliche Sprachverarbeitung entwickelt wurden, und erweitert sie gezielt, um direkt audiobasierte Token zu erzeugen.
Ein zentrales Element der Technologie ist die Kombination aus großen zweikanaligen Gesprächsdaten mit präzisen, zeitlich abgeglichenen Transkriptionen, Sprecherrollen und kontextuellen Markierungen. Diese Tiefe an Daten ermöglicht es dem Modell, komplexe Gesprächsdynamiken wie Sprecherwechsel, Unterbrechungen und emotionale Nuancen nicht nur zu erkennen, sondern auch authentisch nachzubilden. Viele verfügbare Datensätze bieten keine oder nur begrenzte Möglichkeiten bezüglich sauberer Trennung der Sprecherkanäle und präziser Ausrichtung auf Äußerungsebene, was Bland.ai durch sorgfältiges Lizenzieren und Aufbereiten von mehreren Millionen Stunden hochqualitativer zweikanaliger Audiodaten umgeht. Dieses Maß an Datenvielfalt und -qualität ist eine der wichtigsten Voraussetzungen für realistische und kontextsensitiv natürliche Sprachausgabe.
Die technische Grundlage der Bland.ai Engine setzt auf eine verfeinerte Transformer-Architektur. Während klassische LLMs sequenziell auf Basis von Text-Token zukünftige Textsequenzen vorhersagen, wurden diese Ansätze so erweitert, dass das Modell unmittelbar Audio-Token erzeugt. Dazu verwendet Bland.ai eine speziell entwickelte Audio-Tokenizertechnik namens SNAC (Spectral Normalized Audio Codec), welche kontinuierliche Audiosignale in diskrete Token übersetzt.
Diese Token spiegeln sowohl grobe prosodische Merkmale als auch feine phonemische Details wider – ein entscheidender Fortschritt gegenüber bisherigen Ansätzen, die oft entweder in ihrer Auflösung eingeschränkt oder zu komplex für effizientes Training waren. Während des Trainingsprozesses sorgt eine exakte Zuordnung zwischen Text und Audio-Token-Paaren dafür, dass das Modell lernt, welche akustischen Muster zu welchen Sprachinhalten und Emotionen passen. Dadurch wird die Spracherzeugung nicht als isolierter Schritt betrachtet, sondern als ein ganzheitlicher Prozess, der Betonung, Sprechtempo, Betonung und selbst subtilste Dialogeigenschaften simultan berücksichtigt. Diese Herangehensweise hebt die Bland.ai Engine deutlich von bisherigen sequenziellen Verfahren ab und bringt eine neue Dimension an Natürlichkeit in die Sprachsynthese.
Besonders hervorzuheben ist das systemeigene Stil- und Emotionsmanagement. Statt auf starre Vektoren oder explizite Stil-Embeddings zu setzen, nutzt Bland.ai das Potenzial des LLM-Kontexts, um anhand weniger Beispiele oder durch explizite stilistische Markierungen wie <excited> oder <calm> die gewünschte Sprechweise zu adaptieren. Dieser elegante Ansatz ermöglicht eine flexible Übertragung von Stilen und Gefühlsmodulationen, ohne dass vorab aufwendige Trainingsphasen erforderlich sind. Bereits wenige hochwertige Beispiele genügen, um die Engine auf neue Stimmen, Stimmungen oder sogar nonverbale Klangeffekte wie <barking> einzustimmen.
Die Integration von Soundeffekten und die nahtlose Verschmelzung verschiedener Stimmcharakteristiken sind weitere Innovationen des Bland.ai Systems. Es ist beeindruckend, wie die Engine natürliche und künstliche Klänge kombiniert, um so vielfältige Anwendungsfälle zu unterstützten – sei es in multimedialen Produktionen, interaktiven Assistenten oder individualisierten Kundensupport-Szenarien. Dabei bleiben klare Qualitätsanforderungen an die Eingangsdaten essenziell, da Störgeräusche oder minderwertige Aufnahmequalität leicht zu hörbaren Fehlern führen können. Wie bei jeder hochkomplexen KI-Technologie stellen auch bei Bland.
ai Aspekte wie Effizienz und Zuverlässigkeit weiterhin Herausforderungen dar. Das Team um Bland arbeitet intensiv daran, sogenannte Token-Repetitionen, die zu unangenehmen Schleifen in der Audiospur führen können, zu minimieren und die Leistungsfähigkeit auf männliche Stimmen auszugleichen, bei denen bisher ein leichter Nachteil in der Synthesequalität besteht. Darüber hinaus sind Echtzeitfähigkeit und Speicheroptimierung wichtige Entwicklungsschwerpunkte, um die Lösung nicht nur in Forschungslaboren, sondern eben auch in produktiven und interaktiven Systemen etablieren zu können. Aus praktischer Sicht adressiert Bland.ai auch maßgeschneiderte Einsatzmöglichkeiten.
Die Fähigkeit zur Domänenspezifischen Aussprache, etwa für Fachbegriffe in Medizin, Finanzen oder Technik, sorgt für authentische und korrekte Wiedergabe selbst komplexer Inhalte. Die dynamische Anpassung emotionaler Ausdrücke je nach Gesprächssituation steigert die Nutzerakzeptanz und sorgt für empathischere Interaktionen. Hinzu kommt die schnelle Adaptierbarkeit auf neue Sprachen und die Möglichkeit der Stimmklonung durch wenige Beispielaufnahmen, was gerade für mehrsprachige Anwendungen und Markenstimmen von großem Nutzen ist. Zukunftsweisend sind außerdem die angestrebten Erweiterungen in den Bereichen hierarchische Tokenisierung und crossmodale Einbindung. Die Idee, neben Text- auch visuelle oder Umgebungsinformationen in die Sprachgenerierung einzubeziehen, könnte die Natürlichkeit und den Kontextbezug synthetischer Stimmen weiter erhöhen – etwa in smarten Geräten oder multimodalen Kommunikationslösungen.
Gleichzeitig spielt kontinuierliches Lernen für eine stetige Verbesserung durch Echtzeit-Feedback eine wichtige Rolle, ohne dabei die Privatsphäre der Nutzer zu beeinträchtigen. Zusammenfassend positioniert sich die Bland.ai TTS Engine als wegweisendes Produkt, das weit über Verbesserungen klassischer Methoden hinausgeht. Es ist eine Vision, die mit der Verschmelzung von Sprache und Bedeutung, von Technik und Emotion, Menschlichkeit in maschinengenerierte Stimmen bringt. Diese Entwicklung verspricht nicht nur einen höheren Automatisierungsgrad bei digitalen Sprachassistenten und interaktiven Systemen, sondern hebt auch die Interaktion zwischen Mensch und Maschine auf ein neues, viel reichhaltigeres und natürlicheres Niveau.
Wer heute auf diese Technologie setzt, investiert in die Zukunft der Kommunikation – eine Zukunft, in der künstlich erzeugte Stimmen nicht mehr als bloße Nachahmung, sondern als eigenständige, brillante Gesprächspartner empfunden werden. Bland.ai zeigt eindrucksvoll, wie Sprach-KI basierend auf großen Sprachmodellen die Grenzen des Möglichen verschiebt. Durch die intelligente Kombination von Datenqualität, innovativer Modellarchitektur und einer flexiblen, kontextsensitiven Stilerzeugung entsteht eine Synthese, die überzeugt und begeistert. Unternehmen, Entwickler und Kreative können damit vielfältige Anwendungen realisieren – von personalisierten Sprachbots über barrierefreie Kommunikation bis hin zu immersiven Medienerlebnissen.
Die Zukunft der Sprache ist digital, emotional und dynamisch, und Bland.ai ist ein zentraler Treiber dieses Wandels.