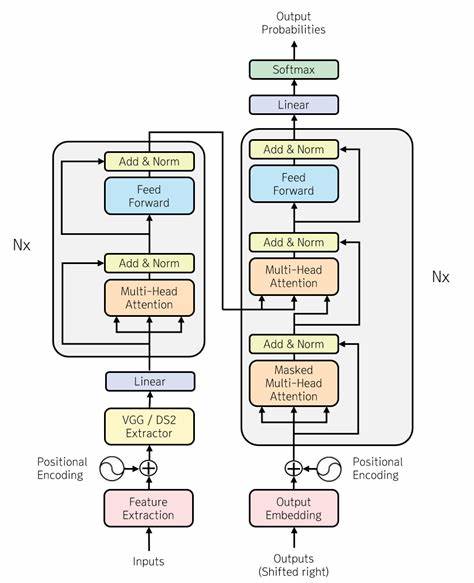
Die Transformer-Architektur hat in den letzten Jahren die natürliche Sprachverarbeitung revolutioniert und ist heute aus vielen Anwendungen wie maschineller Übersetzung, Textgenerierung oder Sprachverständnis nicht mehr wegzudenken. Ursprünglich im Jahr 2017 mit dem wegweisenden Paper "Attention Is All You Need" vorgestellt, hat das Transformer-Modell aufgrund seines innovativen Aufmerksamkeitsmechanismus und seiner Effizienz im Sequenz-zu-Sequenz-Lernen weltweit großes Interesse erweckt. Doch trotz seiner Popularität ist das Verständnis der zugrundeliegenden Mechanismen und die praktische Implementierung für viele Einsteiger eine Herausforderung. Der Code „transformer-from-scratch“ bietet eine einfache, auf PyTorch basierende Umsetzung des ursprünglichen Transformer-Modells und richtet sich vor allem an Lernende und Entwickler, die das Modell besser nachvollziehen möchten, ohne sich in komplexen Optimierungen oder hochgradig spezialisierten Implementierungen zu verlieren. Der Fokus dieser Implementierung liegt auf didaktischer Nachvollziehbarkeit und einer klaren Struktur des Codes.
Anders als viele industriell genutzte Transformer-Varianten, bei denen Geschwindigkeit und Effizienz primär im Vordergrund stehen, wurde hier bewusst auf solche Optimierungsaspekte verzichtet. Dies hat den Vorteil, dass die einzelnen Bausteine und Abläufe des Transformers leichter nachvollzogen und modifiziert werden können. Das Projekt beinhaltet wesentliche Komponenten wie einen einfachen Byte-Pair-Encoding-Tokenizer, der die Texteingabe vorverarbeitet, eine klare Definition des Transformer-Modells selber, sowie ein Skript, das die Trainingsschritte strukturiert. Der Einstieg beginnt mit dem Tokenizer, welcher sich an Byte-Pair-Encoding orientiert – eine Methode, die Wörter in häufige und seltene Segmente zerlegt und so den Wortschatz reduziert, ohne dabei den Kontext stark zu verlieren. Durch die Tokenisierung wird eine Basis geschaffen, auf der das Modell trainiert werden kann.
Dabei zieht die Implementierung eigene Daten heran, im Beispiel werden Samurai Champloo Englisch-Subtitles verwendet, was einen spannenden und leicht zugänglichen Korpus ergibt. Die Tokenisierung wird schrittweise auf eine gewünschte Vokabulargröße von zum Beispiel 8000 Tokens ausgeweitet, wobei die resultierenden Files wie tokens.txt oder vocab.json die Grundlage für das Training sind. Das eigentliche Herzstück bildet das Transformer-Modell in PyTorch, welches sämtliche Kernkomponenten wie die mehrschichtige Self-Attention, die Encoder- sowie Decoder-Module und die Positionsembeddings enthält.
Eine Besonderheit hierbei ist, dass die Architektur sich an den Parametern aus dem Originalpapier orientiert, jedoch mit überschaubaren Dimensionen und Kontextgrößen, um die Anforderungen für Training auf einem durchschnittlichen Laptop erfüllbar zu machen. Die Modelltiefe, die Anzahl der Attention Heads, sowie die Dimensionen der Embeddings und Feedforward-Netzwerke sind so gewählt, dass ein schneller Einstieg möglich ist, obwohl potenziell längere Trainingszeiten notwendig sind. Das Training des Modells erfolgt in einem separaten Skript, das neben der Definition von Hyperparametern wie Lernrate, Batchgröße oder Kontextlänge auch die Trainingsschleife selbst implementiert. Während des Trainings wird der Verlust, beispielsweise mittels Cross-Entropy, pro Epoche ausgegeben, sodass Fortschritte sichtbar werden. Praktisch wird ersichtlich, dass das Modell auf einem einfachen Datensatz nach einigen Durchläufen beginnt, sinnvollere Sequenzen zu generieren, auch wenn die Resultate anfangs noch weit entfernt von natürlicher Sprache sind.
Besonders interessant sind die von der Community beobachteten Schwierigkeiten beim Minimieren des Verlusts, was auf verschiedene Ursachen wie zu kleine Trainingsmengen, suboptimale Hyperparameter oder fehlendes Gewichtstying zurückgeführt werden kann. Die Thematik des Gewichtsbindens, oder Weight Tying, bei dem die Ein- und Ausgangsschichten des Modells gemeinsame Parameter verwenden, wird dabei als wichtige, wenn auch nicht umgesetzte Optimierungsmöglichkeit erwähnt. Gewichtstying kann oftmals die Konvergenz verbessern und Modellparameter reduzieren, bleibt jedoch in diesem einfachen Framework außen vor, um die Übersicht zu bewahren. Dies gibt zugleich Raum für interessierte Entwickler, den Code zu erweitern und eigene Experimente zu wagen. Neben der eigentlichen Implementierung vermittelt das Projekt ehrliche und wertvolle Einblicke in die Herausforderungen bei der Arbeit mit Transformern: Die Parameterauswahl ist häufig nicht trivial und basiert bis heute stark auf empirischen Tests.
Das Originalpapier gibt zwar viele Richtwerte vor, doch deren Übertragbarkeit auf kleinere Datensätze oder Hobbyprojekte ist limitiert. Hier helfen Reflexionen des Autors, die auf das Austesten verschiedener Kontextgrößen, Lernraten oder Batchgrößen verweisen und gleichzeitig vor den Gefahren falscher Parameter warnen. Abschließend bietet die einfache Transformer-Implementierung in PyTorch vor allem eines: einen praktischen Zugang zum Verständnis und zur Experimentierfreude mit einer der mächtigsten Methoden der modernen KI. Sie ermöglicht es, einzelne Konzepte wie Self-Attention, Positionsembeddings und Trainingsabläufe transparent nachzuvollziehen und mit eigenen Ideen zu erweitern. Für Anwender, die sich ins Thema KI und NLP einarbeiten wollen, stellt dieses Projekt daher eine wertvolle Ressource dar, die sowohl theoretische Grundlagen als auch praktische Umsetzung beispielhaft vereint.
Auch wenn der Fortschritt durch geringe Rechenleistung begrenzt sein mag, bringt das Lernen am Modell wertvolle Erkenntnisse für eine fundierte Arbeit mit Transformers in realen Anwendungen. Insbesondere für Einsteiger im Bereich Deep Learning ist es empfehlenswert, sich mit solchen schlanken Implementationen auseinanderzusetzen, bevor komplexe Frameworks oder vortrainierte Modelle genutzt werden. Attentive Aufmerksamkeit, experimentelle Anpassungen und Iterationen im Code helfen, ein tieferes Verständnis aufzubauen und die manchmal als undurchsichtig empfundenen Mechanismen von Transformermodellen transparent zu machen. Unter dem Strich trägt dies langfristig zu einer fundierteren Entwicklung im Bereich der künstlichen Intelligenz bei und bietet eine solide Basis für weiterführende Projekte.







![Hackers Access Windows SMB Shares [video]](/images/E8C7EC23-78E9-431E-A2C5-647D23E34297)