Die Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat die künstliche Intelligenz revolutioniert und neue Maßstäbe in der Textgenerierung, Sprachverarbeitung und zahlreichen weiteren Anwendungen gesetzt. Doch trotz aller Fortschritte steckt die Inferenz dieser Modelle, also die Ausführung von Abfragen mit trainierten Modellen, in einem grundlegenden Problem fest. Lange Startzeiten, ineffiziente Nutzung von Hardware-Ressourcen und ein hoher Overhead durch Containerbereitstellung wirken wie ein Bremsklotz in der praktischen Nutzung. Die Firma InferX bietet nun mit einer innovativen Lösung eine fundamentale Verbesserung, die das Potenzial hat, diese Probleme für immer zu beseitigen.Kalte Starts dominieren noch immer die Inferenzprozesse großer Sprachmodelle.
Jedes Mal, wenn eine neue Anfrage bearbeitet wird oder ein Dienst neu gestartet wird, müssen Container hochgefahren und Modelle mit Hunderten Gigabyte geladen werden. Gerade für Modelle, die 100 GB oder mehr wiegen, ist dies eine enorme Belastung, die zu Wartezeiten von mehreren Sekunden oder gar Minuten führen kann. Diese Verzögerungen können gerade in Anwendungen mit Echtzeit- oder Near-Real-Time-Anforderungen starke Nutzererfahrungen beeinträchtigen. Noch gewichtiger ist aber der Faktor der Effizienz. Lange Ladezeiten führen zu unnötiger GPU-Underutilization, also einer geringeren Auslastung teurer Hardware, die im Grunde das Rückgrat moderner KI-Dienste bildet.
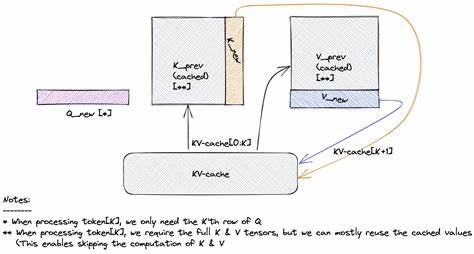
InferX hat sich genau dieser Schwachstelle angenommen und den Inferenzprozess von Grund auf neu gestaltet. Das revolutionäre Konzept basiert darauf, den gesamten GPU-Zustand inklusive der Gewichte, des Key-Value-Caches und des CUDA-Kontexts zu speichern und bei Bedarf blitzschnell wiederherzustellen. Anstatt Modelle jedes Mal vollständig neu zu laden, kann InferX innerhalb von weniger als zwei Sekunden einen Zustand wiederherstellen und so kalte Starts nahezu eliminieren. Dieses Verfahren stellt nicht nur eine iterative Verbesserung dar, sondern ist ein echter Quantensprung im Vergleich zu bisherigen Ansätzen.Was sich auf den ersten Blick simpel anhört, erfordert tiefes technisches Verständnis und erhebliche Innovationen im Umgang mit GPU-Ressourcen und Speicherverwaltung.
Die Fähigkeit, den kompletten Interprozess-Speicher inklusiver aller CUDA-Bibliothekszustände zu snapshotten und wieder zu laden, ist ein Durchbruch, der es erlaubt, Modelle quasi wie Threads zu behandeln. Dies öffnet Türen für dynamisches Hot-Swapping von Modellen während der Ausführung, was bisher absolut unüblich war und neue Flexibilitätslevel in der Nutzung von KI-Systemen erlaubt.Die Folgen dieser Innovation sind für den Anwender direkt spürbar: Signifikant schnellere Antwortzeiten, eine drastische Erhöhung der GPU-Auslastung auf über 90 % und damit einhergehend eine bessere Wirtschaftlichkeit bei Betrieb großer KI-Infrastrukturen. Gerade für Unternehmen, die LLM-basierte Dienste anbieten, bedeutet dies geringere Betriebskosten, verbesserte Skalierbarkeit und eine verbesserte Nutzererfahrung. InferX hebt somit die technische und ökonomische Grundlage von KI-Inferenz auf ein neues Niveau.
Die technische Tiefe des Projekts wird durch Benchmarks untermauert, die zeigen, wie bisherige Ansätze bei der Modellausführung im Vergleich zu InferX um ein Vielfaches langsamer sind und Ressourcen menos effizient nutzen. Die Open-Source-Veröffentlichungen vieler Teile des Systems tragen außerdem zur Transparenz bei und erlauben der Entwicklergemeinde, die Technologie weiter zu erforschen sowie in eigene Projekte zu integrieren. Dies fördert nicht nur Innovation, sondern auch eine engere Zusammenarbeit zwischen Forschung und Praxis.Das Potenzial von InferX wird insbesondere in Anwendungsfällen deutlich, die auf hohe Frequenz und niedrige Antwortzeiten angewiesen sind. Beispielsweise in der Conversational AI, bei automatisierten Übersetzungsdiensten oder im Kundenservice sind schnelle und zuverlässige Reaktionen entscheidend für den Erfolg.
Mit der Fähigkeit, Modelle praktisch sofort einsatzbereit zu machen und nahtlos zwischen ihnen zu wechseln, kann InferX in diesen Szenarien einen echten Wettbewerbsvorteil bieten.Darüber hinaus ist die Nachhaltigkeit ein nicht zu unterschätzender Aspekt. Die effiziente Nutzung der GPU-Ressourcen sorgt für weniger Stromverbrauch und geringere CO2-Emissionen im Betrieb von Rechenzentren, was vor dem Hintergrund steigender Umweltanforderungen und regulatorischer Vorgaben immer wichtiger wird.InferX zeigt eindrucksvoll, wie technische Innovationen in der Praxis alte Paradigmen durchbrechen können. Die grundlegenden Probleme der LLM-Inferenz sind kein Naturgesetz, sondern Resultate von limitierenden Herangehensweisen, die nun mit mutigen neuen Konzepten überwunden werden.
Die Vision einer schnelleren, effizienteren und flexibleren KI-Inferenz wird mit InferX zur greifbaren Realität.Für Entwickler, Unternehmen und Forscher eröffnet sich damit eine neue Ära, in der die Grenzen der Leistungsfähigkeit großer Sprachmodelle nicht mehr durch infrastrukturelle Restriktionen behindert werden. Es bleibt spannend, wie sich die Technologie weiterentwickelt und welche weiteren Verbesserungen in der KI-Inferenz in den kommenden Jahren noch möglich sind. Klar ist jedoch, dass InferX bereits heute einen bedeutenden Meilenstein setzt und das Fundament für schnellere und ressourcenschonendere KI-Anwendungen legt.