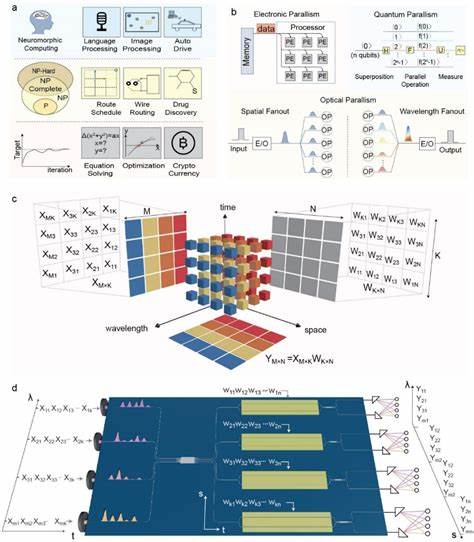
Die rasante Entwicklung im Bereich der künstlichen Intelligenz (KI), des Internets der Dinge (IoT) und der Mobilfunktechnologie der nächsten Generation (5G und 6G) stellt heute enorme Anforderungen an Rechenleistung und Energieeffizienz. Die stetig wachsende Datenmenge fordert nicht nur leistungsstarke, sondern auch skalierbare und energieeffiziente Hardwarelösungen. Klassische elektronische Systeme stoßen hier zunehmend an ihre Grenzen, was die Suche nach innovativen Technologien zum Beschleunigen von Tensoroperationen vorantreibt. Eine wegweisende Innovation stellt der hypermultiplexierte integrierte photonikbasierte optische Tensorprozessor (HITOP) dar, der durch den Einsatz von dreidimensionaler paralleler optischer Verarbeitung – in Raum, Zeit und Wellenlänge – eine drastische Steigerung der Rechenleistung bei minimalem Energieverbrauch ermöglicht. Das Herzstück dieser Technologie ist die Kombination aus innovativen III/V-Mikrolasern im Mikrometerbereich und hochfrequenten Lithium-Niobat-Dünnfilm-Elektrooptik-Modulatoren.
Ersteres ermöglicht eine flexible und skalierbare Erzeugung verschiedener Wellenlängen mit ultraniedrigem Energieverbrauch, letzteres gewährleistet die schnelle und präzise Umsetzung der Daten in optische Signale bei Energiewerten im Bereich von wenigen Femtjoule pro Symbol. Besonders bemerkenswert ist die Nutzung der Lasing-Schwelle der VCSEL-Laser als analoge Inline-Aktivierungsfunktion (ReLU), welche nicht nur die Berechnung beschleunigt, sondern auch die Latenz reduziert und die Systemkomplexität senkt. Das neuartige Architekturkonzept von HITOP nutzt das Prinzip, dass Tensoroperationen durch die Multiplikation großer Matrizen – eine Grundoperation in neuronalen Netzen und vielen wissenschaftlichen Simulationen – realisiert werden. Während herkömmliche Systeme eine modulare Anordnung einzelner Recheneinheiten mit entsprechend hohen elektromagnetischen Schnittstellen verlangen, überschreitet HITOP diese Beschränkungen durch hyperskalare Multiplexierung in drei Dimensionen: Zeit, Raum und Wellenlänge. Die Eingabematrix wird über mehrere Laserquellen gleichzeitig auf unterschiedlichen Wellenlängen encodeirt und durch zeitliche Taktschritte mit Gewichtungsmatrizen über breitbandige modulare Lithium-Niobat-Chips multipliziert.
Die jeweiligen Ergebnisse werden anschließend von hochpräzisen integrierenden Detektoren akkumuliert und in Echtzeit zum endgültigen Resultat summiert. Dieses System meistert gleichzeitig das Problem der exponentiell wachsenden Modulatoranzahl klassischer Wellenlängenmultiplexing-Lösungen, da nur eine lineare Anzahl an Modulatoren für eine quadratische Explosion an Operationen benötigt wird. Die verwendeten VCSELs (Vertical Cavity Surface Emitting Lasers) für die Erzeugung ultrafeiner Wellenlängenkanäle punkten durch ihre hohe Effizienz von bis zu 20 % am Ausgang und der Fähigkeit, mit einem Modulationsbandbreite von über 10 GHz zu arbeiten. Die Wafer-fertigungstechnik erlaubt eine Massenproduktion von mehreren zehntausend Laserquellen mit schmaler spektraler Trennung, wodurch eine feine Abstimmung in einem breiten Wellenlängenbereich von mehreren Nanometern möglich ist. Die Ther-male Abstimmung gibt dazu eine flexible Justierung der Laserwellenlänge.
Solche Eigenschaften sind essentiell für die Stabilität und Kontrollierbarkeit des optischen Multiplexsystems in HITOP. Ergänzt wird dies von den hocheffizienten Lithium-Niobat-Dünnfilm (TFLN) Modulatoren, die im Vergleich zu konventionellen Silizium- oder Indium-Phosphid-Modulatoren durch niedrigere Verlust-, höhere Bandbreiten- und gegenüberliegende Spannungsanforderungen bestechen. Ihre Fähigkeit, Multiwellenlängen im breiten C-Band (1550 nm) zuverlässig zu modulieren, erlaubt eine flexible und gleichzeitig schnelle Gewichtung der Eingangssignale. Neben der hohen Elektrooptik-Bandbreite (>40 GHz) garantieren die dual-port Mach-Zehnder-Modulatoren eine differenzielle Detektion zur präzisen Kodierung positiver und negativer Gewichtswerte, was für KI-Berechnungen unabdingbar ist. Ein weiteres herausragendes Charakteristikum des Systems ist das Hinzufügen analoger nichtlinearer Verarbeitung durch Nutzung der Laserschwelle in den VCSELs als ReLU-Funktion.
Während klassische neuronale Netze auf digitale ReLU-Operationen angewiesen sind, ermöglicht diese optoelektronische Inline-Aktivierung einen erheblichen Abbau von Umwandlungs- und Verarbeitungslatenzen und erhöht zugleich die Kompaktheit und Energieeffizienz des gesamten Prozessors. Die experimentelle Verifikation von HITOP wurde mit realen KI-Modellen durchgeführt, die hunderte Tausend Parameter innehaben. Dabei erreichte das System bei Bildklassifikationsaufgaben mit Datensätzen wie MNIST und EMNIST eine hohe Genauigkeit von bis zu 93 % und mehr, was die praktische Anwendbarkeit von optischer Tensorverarbeitung unter Beweis stellt. Besonders beeindruckend ist die systemimmanente Skalierbarkeit: Die Anzahl der Modulatoren wächst linear, die Rechenleistung hingegen quadratisch. Dies macht HITOP zu einer der vielversprechendsten Plattformen für das Training und die Inferenz großer KI-Modelle, die heute mit digitalen GPUs und ASICs nur mit enorm hohem Energieverbrauch realisierbar sind.
Im Detail zeigt HITOP, dass das Prinzip des Zeitmultiplexing in Kombination mit Wellenlängen- und Raummultiplexing, das bislang in optischen Systemen häufig jeweils isoliert betrachtet wurde, nun miteinander fusioniert wird, um eine beispiellose parallele Verarbeitung zu realisieren. Außerdem hilft die Integration von hochpräzisen zeitlichen Delay-Elementen, anpassbaren Stromquellen für Laser und modulare Bausteine für Wellenlängenverteilung dabei, die Synchronisation der optischen Kanäle mit der elektrischen Steuerung sicherzustellen, was wesentliche Voraussetzung für die hohe Rechenpräzision ist. Ein weiterer bedeutender Vorteil ist die Energieeffizienz. Das System operiert mit einem optischen Energieverbrauch von wenigen femtojoule pro Rechenoperation, wobei das Hauptverbraucherelement – die Digital-Analog-Wandler (DACs) – ebenfalls stetig verbessert werden, insbesondere durch die Weiterentwicklung co- beziehungsweise heterointegrierter optoelektronischer Bauelemente, um den Energiebedarf in Zukunft noch weiter zu senken. Damit rückt der energieeffiziente und skalierbare optische Prozessor in den Bereich realer praktischer Einsatzszenarien vor, angefangen von Cloud-Rechenzentren über Edge-Devices bis hin zu autonomen Systemen.
In puncto Fertigungstechnologie zeigt HITOP exemplarisch, wie die Kombination aus etablierten Wafer-Fertigungsmethoden für VCSELs und der Innovationsfähigkeit von TFLN-Modulatoren den Brückenschlag zwischen Forschung und industrieller Serienfertigung schafft. Die Potentiale werden mit fortgeschrittenen Integrationstechnologien (etwa Photonen-Wellenleiter-Bonding, Mikroringfilter für Multiplexing und heterogene Integration von Detektoren) komplettiert und eröffnen den Weg zum voll-integrierten On-Chip Tensorprozessor. Im Gesamtbild zeigt die Entwicklung des hypermultiplexierten integrierten photonikbasierten optischen Tensorprozessors den nächste großen evolutionären Schritt in optischer KI-Hardware. Die Technologie kombiniert hohe Rechengeschwindigkeit, hohe Rechenpräzision, niedrige Energieaufnahme und lineare Skalierbarkeit – Eigenschaften, die für den Durchbruch von KI-Anwendungen entscheidend sind. Angesichts der stetig steigenden Anforderungen an Rechenressourcen für Deep Learning und komplexe Simulationen erscheint die Kombination aus photonischer Parallelität und innovativen elektrooptischen Bauelementen wie HITOP als eine der vielversprechendsten Lösungen.


![Do Dumb Things [pdf]](/images/2524CF93-E070-4DDD-8268-440288F5AE03)