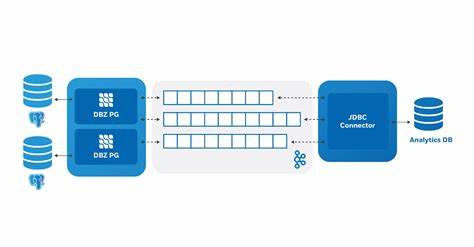
PostgreSQL ist weithin bekannt für seine Robustheit und flexiblen Funktionen, die es zu einem Favoriten unter Datenbankentwicklern machen. Besonders bei großen Datenmengen und komplexen Datenstrukturen spielt die Oversized-Attribute-Storage-Technik, kurz TOAST, eine bedeutende Rolle. TOAST behandelt sehr große Datenwerte, indem sie außerhalb der regulären Tabellen gespeichert werden, um die Effizienz und Leistung der Datenbank zu erhöhen. Wenn jedoch reale Datenänderungen in PostgreSQL in Echtzeit verfolgt und transportiert werden sollen, wie etwa mittels Debezium, entstehen dabei spezifische Herausforderungen im Zusammenhang mit TOAST-Spalten, die eine präzise und vollständige Replikation erschweren. Dieses komplexe Thema beleuchtet die Funktionsweise von TOAST in der PostgreSQL-Replikation, die Limitationen von Debezium bei der Verarbeitung großer Spaltendaten sowie innovative Lösungsansätze, mit besonderem Fokus auf den Einsatz von Apache Flink für ein robustes Backfilling dieser TOAST-Daten.
TOAST dient in PostgreSQL als Mechanismus, um besonders große Werte aus Spalten wie Text oder Binärdaten auszulagern und effizient zu verwalten. Diese Werte können beispielsweise langformatige Texte, Mediendateien oder andere umfangreiche Daten repräsentieren. Statt sie direkt in der Haupttabelle zu speichern, werden sie ausgegliedert und komprimiert in speziellen Untertabellen abgelegt. Diese technische Vorgehensweise erhöht die Performance der Datenbank und minimiert den Speicherbedarf bei Abfragen, die diese großen Werte nicht benötigen. Doch sobald man versucht, Datenänderungen auf Basis von PostgreSQLs logischer Replikation via Debezium zu erfassen, ergeben sich Probleme: Die Change Data Capture (CDC)-Events liefern nicht zwingend den kompletten Datensatz inklusive der ausgelagerten TOAST-Werte.
Dies liegt in der Art und Weise begründet, wie PostgreSQL Abfrage- und Replikationsmechanismen für solche großen Spalten implementiert. Ein zentrales Konzept bei der Replikation von PostgreSQL-Daten ist das sogenannte Replica Identity, das bestimmt, wie Updates an Tabellen erkannt und behandelt werden. Standardmäßig nutzt PostgreSQL für die meisten Tabellen nicht die Replica Identity FULL, um Performanceeinbußen und erhöhte WAL-Volumina zu vermeiden. Dadurch werden TOAST-Spalten bei Änderungen nur dann mitgeliefert, wenn sie sich tatsächlich geändert haben. Unveränderte TOAST-Felder erscheinen in den Change Events dementsprechend entweder gar nicht oder werden durch einen speziellen Platzhalter markiert.
In Debezium ist dies der Wert __debezium_unavailable_value. Dieser generische Marker signalisiert, dass der Wert der TOAST-Spalte im Event nicht enthalten ist. Für Verbraucher dieser Events bedeutet dies erhebliche Herausforderungen, da der aktuelle Zustand der betreffenden Datensätze ohne diese Werte nicht vollständig rekonstruierbar ist. Das Fehlen vollständiger TOAST-Daten in Change Events erfordert oft, dass Datenkonsumenten spezielle Logiken implementieren, um mit den Platzhaltern umzugehen. Einige Systeme, wie beispielsweise Snowflake, ermöglichen dies durch intelligente MERGE-Abfragen, die nur tatsächliche Änderungen berücksichtigen und Platzhalterwerte ignorieren.
Diese Lösungswege sind allerdings suboptimal, da sie tiefes Wissen über die zu behandelnden TOAST-Spalten auf Seiten jedes einzelnen Verbrauchers voraussetzen. Dies erhöht die Komplexität, erschwert Wartung und Skallierung der Dateninfrastruktur und führt zu einer fragmentierten Herangehensweise, bei der viele Konsumenten ähnliche Probleme individuell lösen müssen. Die Notwendigkeit, diese Komplexität am Ursprung zu adressieren, also schon beim Datenproduzenten Debezium, ist daher hoch. Debezium bietet bereits einen eingebauten Mechanismus in Form des Reselect Postprocessors. Dieses Feature aktualisiert die Change Events dynamisch, indem es bei fehlenden TOAST-Werten eine zusätzliche Abfrage gegen die Quell-Datenbank ausführt, um den aktuellen vollständigen Wert zu ermitteln und in das Event einzufügen.
Dadurch entsteht ein vollständigeres Bild des Datensatzes ohne dass der Verbraucher selbst weitere Sonderbehandlung implementieren muss. Obwohl der Reselect-Ansatz für viele Anwendungsfälle ausreichend sein kann, ist er nicht frei von Nachteilen. Die zusätzlichen Datenbankabfragen verursachen höhere Latenzen und können die Last auf der Quell-Datenbank erhöhen, insbesondere wenn viele Change Events mit fehlenden TOAST-Werten gleichzeitig auftreten. Noch gravierender ist die Problematik von Datenrennen: Wenn mehrere Updates schnell hintereinander erfolgen, kann der Reselect Postprocessor veraltete oder inkonsistente Daten zurückliefern, da er immer nur den aktuellen Zustand abfragt, aber keine zeitpunktbezogenen Zustandsbilder aus der Vergangenheit bereitstellt. Dieses Verhalten kann zu Dateninkonsistenzen in den downstream Systemen führen.
Aus diesem Grund lohnt es sich, alternative Ansätze zu betrachten, die eine sichere und performante Backfilling-Strategie für TOAST-Spalten ermöglichen. Hier kommt die moderne Datenstromverarbeitung mit Apache Flink ins Spiel. Flink bietet leistungsstarke APIs und Frameworks, die es erlauben, Statefulness und zeitliche Zusammenhänge in Datenströmen zu modellieren und zu verarbeiten. Damit wird es möglich, fehlende TOAST-Werte während der Verarbeitung von Change Events eigenständig und ohne Rückgriff auf die Quell-Datenbank zu rekonstruieren und zu ergänzen. Eine mögliche Umsetzung erfolgt mit dem Flink DataStream API.
Hier wird mittels eines benutzerdefinierten Prozessors eine Zustandsverwaltung implementiert, die für jeden Datensatz den letzten bekannten Wert der TOAST-Spalte speichert. Bei Eingang eines Inserts oder Snapshot-Events wird der Zustand entsprechend aktualisiert. Für Update-Events, in denen die TOAST-Spalte nicht verändert wurde, wird der gespeicherte Wert aus dem Zustand ausgelesen und in den Change Event eingefügt. So entsteht ein konsistenter Datenstrom mit vollständigen Datensätzen. Auch das Löschen von Einträgen führt zu einer Bereinigung des gespeicherten Zustands.
Die Persistenz und Skalierbarkeit von Flinks State Management sorgt dafür, dass auch bei Millionen von Datensätzen und hohen Datenvolumina diese Methode stabil und performant arbeitet. Ein großer Vorteil von Flinks Ansatz liegt in der Entkopplung von der Quell-Datenbank. Die Verarbeitung erfolgt im Stream und kann so optimal an moderne event-getriebene Architekturen angepasst werden, etwa bei der Integration in Kafka-basierte Systeme. Allerdings benötigt die Entwicklung von DataStream-Anwendungen ein gewisses Maß an Expertise, und der imperative Programmierstil birgt auch das Risiko von Fehlern oder Komplexitätsfallen. Für viele Organisationen ist SQL die bevorzugte Sprache für Datenverarbeitung.
Apache Flink bietet daher mit Flink SQL eine deklarative Alternative an, die komplexe Stream-Operationen in vertrauten SQL-Statements ermöglicht. Das Backfilling von TOAST-Spalten lässt sich hier mit sogenannten OVER-Aggregationen realisieren. Diese übertragen die letzte gültige Wertänderung innerhalb eines definierten Zeitfensters auf nachfolgende Change Events, die den TOAST-Wert als Platzhalter führen. So entstehen kontinuierliche, aktualisierte Datenreihen ohne Lücken. Die Verwendung von SQL senkt die Einstiegshürde und erleichtert die Integration in bestehende Analyse- und Datenverarbeitungssysteme.
Dennoch hat die SQL-basierte Methode ebenfalls Limitationen. Beispielsweise ist die Steuerung der Speicherzeit von Zuständen in Flink SQL weniger flexibel als in imperativen APIs. Bei langen Updatezyklen oder verzögerten Deletes kann der Zustand unnötig lange gehalten werden, was möglicherweise zu erhöhtem Ressourcenverbrauch führt. Außerdem lassen sich besondere Situationen wie das gezielte Entfernen alter Zustände oder komplexe Logiken nicht immer einfach ausdrücken. Eine sehr vielversprechende Neuerung stellen die Process Table Functions (PTFs) dar, die in Flink 2.
1 eingeführt werden. PTFs verbinden die Vorteile imperativer Programmierung mit der Eleganz von SQL und bieten unter anderem direkten Zugriff auf persistenten Zustand und Timerfunktionen. Sie sind polymorphisch, das heißt, ihre Eingabe- und Ausgabeformate können dynamisch bestimmt werden – ideal, um komplexe Backfilling-Logiken flexibel zu realisieren. Durch die Handhabung von Zuständen auf Tabellenebene ermöglichen sie eine präzise Steuerung über Lebenszyklen von gespeicherten TOAST-Werten, darunter auch das automatische Bereinigen von Daten, sobald ein Datensatz gelöscht wird. Die Implementierung einer TOAST-Backfill-Logik mit PTFs führt zu klareren und leichter wartbaren SQL-Statements.
Da das komplexe State-Handling in der Funktion gekapselt ist, müssen sich Entwickler und Dateningenieure gegenübersitzender Verarbeitungsschichten nicht mit den technischen Details beschäftigen. Der modulare Aufbau fördert die Wiederverwendbarkeit und erleichtert die Zusammenarbeit in größeren Teams oder Organisationen. Zusammenfassend stellt das Backfilling von TOAST-Spalten in Change Data Capture-Szenarien eine anspruchsvolle, aber essenzielle Aufgabe dar, um vollständige und korrekte Datenströme zu garantieren. Während Debezium mit seinem Reselect Postprocessor eine einfache und sofort nutzbare Lösung bietet, stößt diese bei steigenden Anforderungen an Skalierbarkeit und Datenkonsistenz schnell an ihre Grenzen. Die Kombination aus Apache Flink und seinen APIs eröffnet flexible und leistungsstarke Möglichkeiten, um das Problem auf höherer Ebene zu adressieren und den Datenfluss in verteilten Architekturen zu optimieren.
Die Einführung von Process Table Functions verspricht dabei eine besonders elegante Symbiose aus SQL-Freundlichkeit und Statefulness und kann in Zukunft zum bevorzugten Weg für das Backfilling von TOAST-Daten avancieren. Unternehmen, die kritisch auf präzise Echtzeitdaten angewiesen sind, sollten diese Entwicklungen aufmerksam verfolgen und prüfen, wie sich moderne Stream-Processing-Frameworks in ihre bestehende Datenarchitektur integrieren lassen. Es bleibt spannend, wie das Umfeld um Debezium und Apache Flink weiter wächst und welche weiteren Innovationen das Datenmanagement bei großen, komplexen Systemen vorantreiben wird. Bereits heute lohnt es sich, bestehende Limitierungen zu erkennen, passende Werkzeuge zu wählen und damit den Grundstein zu legen für zuverlässige, performant verarbeitete Datenpipelines im Zeitalter der Echtzeit-Datenverarbeitung.