In der schnelllebigen Welt der Künstlichen Intelligenz (KI) gewinnen multimodale große Sprachmodelle (MLLMs) zunehmend an Bedeutung. Diese Modelle kombinieren textuelle und visuelle Eingaben, um komplexe Aufgaben zu bewältigen, die in der Realität häufig vorkommen. Ein entscheidendes Element hierbei ist die räumliche Intelligenz, also die Fähigkeit, Beziehungen zwischen verschiedenen Objekten und Szenen im Raum zu verstehen und sinnvoll miteinander zu verknüpfen. Während bisherige Benchmarks überwiegend einzelne Bilder und die darauf basierenden Zusammenhänge untersucht haben, bleibt die Bewertung von Multi-Image-Raumintelligenz weitgehend unzureichend erforscht. Genau hier setzt MMSI-Bench an – ein neues, umfassendes Benchmark speziell für die Multi-Image räumliche Intelligenz, das einen wichtigen Meilenstein in der KI-Bewertung darstellt.
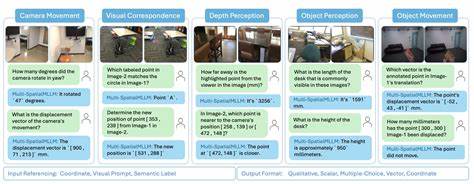
MMSI-Bench wurde mit höchster Sorgfalt und durch langwierige menschliche Annotation entwickelt. Ein Team aus sechs erfahrenen Forschern mit Expertise in 3D-Vision investierte über 300 Stunden in die Erstellung von 1.000 sorgfältig formulierten Multiple-Choice-Fragen. Diese Fragen basieren auf mehr als 120.000 Bildern, die gezielt ausgewählt und kombiniert wurden, um komplexe räumliche Aufgaben und Zusammenhänge zu erzeugen.
Die Besonderheit von MMSI-Bench liegt nicht nur in der schieren Menge und Komplexität, sondern auch in der Präzision der Ablenkungsoptionen und der transparenten Schritt-für-Schritt-Begründungen, welche die Modellleistung nachvollziehbar machen. Ein zentrales Anliegen von MMSI-Bench ist die Förderung der Forschung im Bereich der räumlichen Intelligenz über Bildgrenzen hinweg. Während bisherige Benchmarks die Interaktionen innerhalb eines einzelnen Bildes bewerten, geht MMSI-Bench einen Schritt weiter und fordert die Modelle heraus, das Zusammenspiel und die räumlichen Relationen mehrerer Bilder zu erfassen, zu rekonstruieren und zu interpretieren. Dies entspricht deutlich besser den Anforderungen realitätsnaher Anwendungen, in denen Informationen aus verschiedenen Blickwinkeln, Zeitpunkten oder Kamerapositionen zusammengeführt werden müssen. Die Evaluierung einer Vielzahl von 34 offenen und proprietären multimodalen Modellen verdeutlicht den enormen Schwierigkeitsgrad von MMSI-Bench.
Die besten offenen Modelle erreichen dabei lediglich eine Genauigkeit von etwa 30 Prozent, während das leistungsstärkste Modell von OpenAI, das o3 reasoning model, eine Genauigkeit von vierzig Prozent erzielt. Diese Zahlen stehen in starkem Kontrast zum menschlichen Durchschnitt von 97 Prozent und zeigen eindrucksvoll, wie groß die Lücke zwischen Mensch und Maschine im Bereich der Multi-Image-Raumintelligenz derzeit noch ist. Neben der Benchmarking-Funktion bietet MMSI-Bench auch ein automatisiertes Fehleranalysesystem, das die Leistung der Modelle auf vier wesentliche Schwachstellen hin untersucht. Dazu zählen Fehler bei der Bildverankerung, Probleme beim Überlappungsmatching und der Szenenrekonstruktion, Schwierigkeiten bei der situationsbezogenen Transformationslogik sowie Fehler in logischen räumlichen Schlussfolgerungen. Diese differenzierte Diagnose erlaubt Entwicklern, gezielt an den Schwachstellen ihrer Modelle zu arbeiten und so die räumliche Intelligenz entscheidend zu verbessern.
Ein weiterer bemerkenswerter Aspekt von MMSI-Bench ist die Verbindung zwischen multimodaler Bildverarbeitung und natürlicher Sprachverarbeitung. Multimodale Sprachmodelle müssen nicht nur einzelne Bildinhalte verstehen, sondern sie auch miteinander in einen kohärenten Zusammenhang bringen und diesen beschreiben oder erklären können. Die sorgfältige Annotation der Fragen und Begründungen im MMSI-Bench ermöglicht es Modellen, komplexe räumliche Denkprozesse nachzuvollziehen und dadurch ein besseres Verständnis zu entwickeln. Die Relevanz von MMSI-Bench geht weit über die akademische Forschung hinaus. In Anwendungsfeldern wie der Robotik, der autonomen Navigation, der Augmented Reality oder im Bereich der Überwachungssysteme ist die Fähigkeit zur Multi-Image-Raumintelligenz von zentraler Bedeutung.
Beispielsweise müssen autonome Fahrzeuge Szenen aus verschiedenen Kameras betrachten und räumliche Beziehungen auch unter sich bewegenden Bedingungen zuverlässig bewerten können. MMSI-Bench liefert hierfür eine wertvolle Grundlage zur objektiven Bewertung und Weiterentwicklung der zugrundeliegenden KI-Systeme. Die Integration von MMSI-Bench in bestehende Forschungs- und Entwicklungsprozesse bietet zudem den Vorteil, dass Fortschritte im Bereich der räumlichen Intelligenz messbar und vergleichbar werden. Entwickler können so gezielt herausfinden, welche architektonischen oder algorithmischen Ansätze effektiv sind und wie Modelle bei komplexen räumlichen Aufgaben abschneiden. Dies kann den Innovationszyklus stark beschleunigen und zugleich die Qualität und Sicherheit von KI-Anwendungen maßgeblich erhöhen.
Darüber hinaus fördert MMSI-Bench die interdisziplinäre Zusammenarbeit zwischen Computer-Vision-Experten, Forschern der natürlichen Sprachverarbeitung und Praktikern aus verschiedenen technischen Branchen. Die Herausforderung, Multi-Image-Raumintelligenz zu meistern, erfordert ein tiefes Verständnis sowohl visueller Wahrnehmung als auch kognitiver Verarbeitungsmechanismen, was in MMSI-Bench in beispielhafter Weise zusammengeführt wird. Insgesamt markiert MMSI-Bench einen neuen Standard bei der Bewertung multimodaler KI-Systeme und hebt die Bedeutung räumlicher Intelligenz im Zusammenspiel mit sprachlichen Fähigkeiten hervor. Die bisher erzielten Ergebnisse machen klar, dass es noch ein weiter Weg ist, bis Maschinen die räumliche Wahrnehmung von Menschen auch nur annähernd erreichen. Doch mit MMSI-Bench steht nun ein leistungsfähiges Werkzeug bereit, um diese Herausforderung methodisch anzugehen und zielgerichtet Fortschritte zu erzielen.
Forscher und Entwickler, die im Bereich der multimodalen KI tätig sind, profitieren von MMSI-Bench durch dessen praxisnahe Fragestellungen, hochwertige Annotation und die detaillierten Fehleranalysen. Dies macht es möglich, neben reiner Leistungssteigerung auch die Robustheit und Kontextsensitivität der Modelle zu optimieren. Die Verfügbarkeit von MMSI-Bench und die zugrunde liegenden Datensätze ermöglichen eine offene und transparente Forschungsumgebung. Hierdurch wird Innovation gefördert und die Gemeinschaft angeregt, neue Ideen und Verfahren zu entwickeln, die der komplexen Realität visueller und sprachlicher Informationsverarbeitung besser gerecht werden. Zusammenfassend lässt sich sagen, dass MMSI-Bench ein zukunftsweisender Benchmark im Bereich der Multi-Image räumlichen Intelligenz ist.
Die Kombination aus anspruchsvollen Aufgaben, präzisen Annotationen und einem tiefen Fokus auf multimodale Zusammenhänge macht MMSI-Bench zu einem unverzichtbaren Werkzeug für alle, die KI-Systeme mit verbesserter räumlicher Wahrnehmung und reasoning Fähigkeiten entwickeln möchten. Die damit verbundenen Fortschritte könnten weitreichende Auswirkungen auf zahlreiche praxisrelevante Anwendungsbereiche haben, von der autonomen Mobilität bis hin zu intelligenten Assistenzsystemen. Die Herausforderung ist groß, doch MMSI-Bench zeigt den Weg auf, wie KI das Lernen über einzelne Bilder hinaus meistern kann und so zu einem tieferen, räumlichen Verständnis der Welt gelangt.