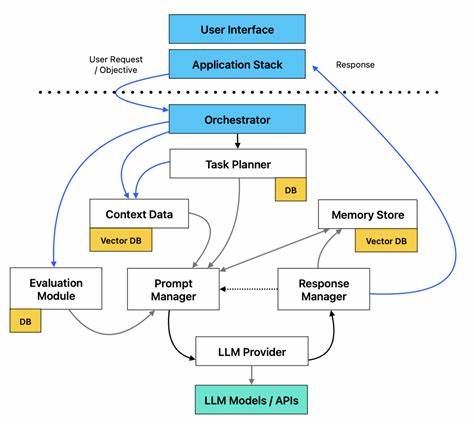
Die rasante Entwicklung der künstlichen Intelligenz hat mit der Etablierung großer Sprachmodelle, auch bekannt als Large Language Models (LLMs), eine neue Ära in der Softwareentwicklung eingeläutet. Diese Modelle eröffnen völlig neue Möglichkeiten, Software intelligenter, flexibler und benutzerfreundlicher zu gestalten. Immer mehr Entwickler und Unternehmen nutzen LLMs, um innovative Anwendungen zu bauen, die natürliche Sprache verstehen, interpretieren und darauf reagieren können. Dabei reicht das Anwendungsspektrum von einfachen Textanalysen bis hin zu komplexen Dialogsystemen und automatisierten Datenextraktionen. Der Schlüssel zum erfolgreichen Einsatz von LLMs liegt jedoch nicht nur in der Modellarchitektur selbst, sondern auch in der Art und Weise, wie Software um diese Modelle herum gestaltet wird.
Der Einstieg in das Entwickeln mit LLMs erfordert eine gezielte Einrichtung geeigneter Entwicklungsumgebungen und Toolchains. Besonders für Python-Entwickler stehen inzwischen viele APIs und Bibliotheken zur Verfügung, die den Zugriff auf verschiedenste Modelle vereinfachen. Das Einrichten stabiler Python-Umgebungen ist essentiell, um die vielfältigen Funktionen der LLMs effizient und fehlerfrei nutzen zu können. Plattformen wie GitHub Codespaces bieten hier eine hervorragende Möglichkeit, ohne Umgebungsprobleme direkt auf leistungsstarken Maschinen zu arbeiten, was gerade bei Workshops oder Teamprojekten einen reibungslosen Ablauf garantiert. Die Grundlagen beim Umgang mit LLMs liegen im richtigen Prompting.
Das bedeutet, die Eingabeaufforderungen so zu formulieren, dass das Modell möglichst präzise und nützliche Antworten erzeugt. Ein gut konzipierter Prompt kann den Unterschied zwischen einer vagen und einer treffenden Antwort ausmachen. Dabei helfen nicht nur einfache Terminalbefehle, sondern auch fortgeschrittene Techniken wie das Nutzen von Systemprompts oder das Einfügen von Textfragmenten und Anhängen, um den Kontext zu erweitern und die Ergebnisse zu verfeinern. Die Integration von Prompting-Funktionalitäten direkt in Python-Code erhöht die Flexibilität und ermöglicht dynamische Interaktionen mit unterschiedlichen Modellen. Ein besonders praktisches Anwendungsfeld ist der Aufbau von Tools, die natürliche Sprache in strukturierte Daten umzusetzen, etwa durch Text-zu-SQL-Generatoren.
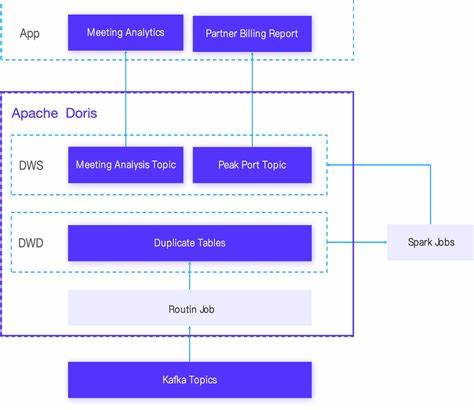
Solche Anwendungen erlauben es Anwendern, komplexe Datenbankabfragen einfach per Sprache zu steuern, ohne selbst SQL beherrschen zu müssen. Das spart Zeit, erhöht die Benutzerfreundlichkeit und macht Datenbanken auch für Nicht-Experten zugänglich. Die prototypische Entwicklung solcher Tools lässt sich mithilfe von LLMs schnell realisieren, da die Modelle kontextbasiert lernen und flexibel auf unterschiedliche Datenbankschemata reagieren. Die strukturierte Datenextraktion gilt als eine der ökonomisch wertvollsten Anwendungen von LLMs. Unternehmen profitieren enorm davon, wenn sie aus unstrukturierten oder unübersichtlichen Quellen automatisch relevante Informationen erfassen und in gut nutzbare Formate überführen können.
Ob es sich um das Auslesen von Rechnungen, Verträgen oder sonstigen Dokumenten handelt – große Sprachmodelle zeigen hier beeindruckende Fähigkeiten, Daten präzise zu identifizieren und zu klassifizieren. Diese Automatisierung reduziert menschlichen Aufwand und Fehlerquellen deutlich. Ein weiteres spannendes Thema bei der Arbeit mit LLMs ist die semantische Suche und Retrieval-Augmented Generation (RAG). Dabei werden Dokumente und Inhalte nicht nur aufgrund von Schlüsselwortübereinstimmungen gefunden, sondern auch semantisch anhand ihrer Bedeutung und Kontextnähe bewertet. Dies geschieht mithilfe sogenannter Vektor-Embeddings, bei denen Texte als numerische Repräsentationen in hochdimensionalen Räumen abgebildet werden.
Solche Verfahren ermöglichen eine viel präzisere Suche, die auch bei Synonymen oder umschreibenden Formulierungen relevante Ergebnisse liefert. Die Kombination von klassischer Volltextsuche mit solchen semantischen Methoden schafft hybride Systeme, die sowohl effizient als auch hochperformant sind. Mit der Einführung von Tool-Nutzung durch LLMs wurde ein weiterer Innovationssprung vollzogen. Sprachmodelle können mittlerweile eigenständig APIs ansteuern, Befehle ausführen oder sogar Aktionen außerhalb ihres direkten Textbereichs übernehmen. Dies erweitert den Anwendungsrahmen erheblich und erlaubt die Erstellung komplexer, interaktiver Assistenten oder automatisierter Workflows.
Doch mit dieser erweiterten Funktionalität kommen auch neue Herausforderungen, beispielsweise im Bereich der Sicherheit. Das Risiko von sogenannten Prompt-Injection-Angriffen steigt, bei denen bösartige Eingaben das Modell manipulieren, um unerwünschte Operationen auszulösen. Daher gewinnt das Thema LLM-Sicherheit immer mehr an Bedeutung. Effektive Abwehrmechanismen gegen solche Angriffe sind essenziell, insbesondere wenn die LLMs in produktiven Umgebungen sensible Daten verarbeiten oder kritische Dienste steuern. Ansätze wie das Dual-LLM-Pattern trennen den vertrauenswürdigen Teil des Systems von jener Komponente, die unkontrollierte Nutzereingaben verarbeitet und so potenzielle Gefahren isolieren kann.
Neue Forschungsergebnisse, unter anderem von Google DeepMind, treiben diese Konzepte weiter voran und schaffen vielversprechende Methoden, um Manipulationen zuverlässig zu verhindern. Neben Sicherheit ist auch das Testen und Bewerten von LLM-basierten Systemen ein komplexes Thema. Traditionelle Unit-Tests stoßen an ihre Grenzen, da LLM-Antworten oft nicht deterministisch sind und sich durch kleine Eingabeänderungen stark unterscheiden können. Hier kommen spezielle Evaluationsmethoden zum Einsatz, darunter sogenannte Evals und der Einsatz von LLMs selbst als Prüfinstanzen. Diese unterstützen dabei, qualitative Unterschiede in Antworten zu erfassen und die Effektivität von Modellanpassungen oder Prompt-Veränderungen objektiv zu beurteilen.
Ein gut entwickeltes Evaluation-Framework bietet damit nicht nur Sicherheit, sondern auch die Möglichkeit, kontinuierlich Verbesserungen voranzutreiben und die Wettbewerbsfähigkeit zu stärken. Die Landschaft der verfügbaren LLM-Modelle ist heute äußerst vielfältig. Marktführer wie OpenAI bleiben zwar zentrale Player, doch ebenso gewinnen Modelle aus dem Hause Anthropic, Gemini oder anderer Anbieter an Bedeutung. Zudem bieten zahlreiche „open weights“ Modelle eine Alternative, die insbesondere im Hinblick auf Kosten und lokale Nutzbarkeit attraktiv sind. Selbst auf privaten Geräten mit moderater Leistung können inzwischen beeindruckende Modelle betrieben werden, was neue Nutzungsszenarien ermöglicht und Abhängigkeiten von Cloud-Diensten reduziert.
Zukunftsträchtig sind auch Entwicklungen im Bereich multimodaler LLMs, die nicht nur reine Textinformationen verarbeiten, sondern auch Bild-, Audio- oder sogar Videodaten interpretieren und generieren können. Solche Modelle erweitern das Anwendungsspektrum enorm und erlauben komplexe Interfaces, die der natürlichen menschlichen Kommunikation noch näherkommen. Die Integration dieser Fähigkeiten in bestehende Software wird die Art und Weise verändern, wie Nutzer mit Technologien interagieren. Zusammenfassend lässt sich sagen, dass die Entwicklung von Software auf Basis von Large Language Models ein dynamisches und faszinierendes Feld ist, das große Chancen bietet. Von der Einrichtung der Umgebung über das Design effektiver Prompt-Strategien bis hin zum Aufbau sicherer, skalierbarer Systeme – die Bandbreite an Fähigkeiten und Herausforderungen ist groß.
Wer sich mit Engagement und einem offenen Blick für Innovationen diesem Bereich widmet, wird in der Lage sein, leistungsstarke Anwendungen zu schaffen, die nicht nur technisch überzeugen, sondern auch echten Mehrwert für Anwender und Unternehmen bieten.