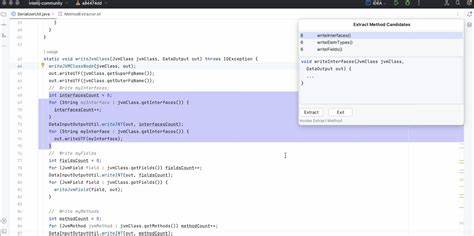
Die fortschreitende Entwicklung großer Sprachmodelle (Large Language Models, LLM) eröffnet völlig neue Möglichkeiten in der Automatisierung von Programmieraufgaben. Insbesondere in der Java-Entwicklung, wo sich repetitive Aufgaben schnell summieren können, verspricht der Einsatz solcher Technologien eine erhebliche Erleichterung für Entwickler. Ein faszinierendes Beispiel hierfür ist die Entwicklung eines IntelliJ-Plugins, das auf LLM basiert und das automatisierte Generieren von Code sowie Tests ermöglicht. Dieses Plugin hilft dabei, mühsame Routineaufgaben zu minimieren und unterstützt Entwickler dabei, ihre Konzentration auf komplexere Probleme zu lenken.Der Kern dieses Projekts gründet auf der Idee, dass viele Aufgaben in der Softwareentwicklung, die sich präzise durch natürliche Sprachregeln beschreiben lassen, sich durch maschinelles Lernen automatisieren lassen.
Durch die Definition von klaren Schnittstellen und Datenmodellen können wiederkehrende Schritte wie das Schreiben von Unit-Tests, Implementierungen oder Fixtures in einem Großteil generiert werden. Die Grundlage bildet eine Sammlung von Regeln und Referenzklassen, die als Verständnisrahmen für das LLM dienen.Eine praktische Validierung erfolgte zunächst mit einem Python-Command Line Interface (CLI), welches dazu verwendet wurde, den Automatisierungsansatz auf ein API-Projekt mit mehreren Tausend Codezeilen anzuwenden. Das positive Ergebnis führte zur Entwicklung eines Plugins für die IntelliJ-IDE, einer der beliebtesten Entwicklungsumgebungen für Java. Im Mittelpunkt steht dabei die Möglichkeit, wiederkehrende Programmieraufgaben durch Eingabe natürlicher Sprachbefehle zu definieren und das LLM Aufgaben wie das Erstellen von Testklassen entsprechend diesen Regeln ausführen zu lassen.
Eine Besonderheit des Systems ist die Anpassbarkeit. Jeder Entwickler oder jedes Team hat unterschiedliche Standards und Arbeitsweisen. Deshalb ist es wichtig, dass die Regeln zur Codeerzeugung individualisierbar sind. Beispiele hierfür sind unterschiedliche Vorlieben beim Einsatz von Java-Prüfbibliotheken, dem Umfang von Testfällen oder der Handhabung von Abhängigkeiten. Durch die Möglichkeit, Systemprompts gezielt zu definieren, kann jede Gruppe den erzeugten Code an ihre spezifischen Bedürfnisse anpassen und so eine konsistente Codebasis gewährleisten.
Ein zentraler Aspekt ist die Sammlung und Einbindung relevanter Referenzklassen und Schnittstellen. Das Plugin nutzt eigens definierte Annotationen, um die für eine bestimmte Aufgabe notwendigen Quellen automatisch zu identifizieren und zusammenzustellen. Besonders zentral ist dabei die Nutzung von Interfaces als Grundlage. Interfaces bieten eine klare Abgrenzung der gewünschten Funktionalität, während die Analyse von Implementierungsklassen schnell komplex wird, da dort die Grenzen der Referenzketten schwer zu definieren sind. Durch die Fokussierung auf Schnittstellen verbleibt die Codegenerierung übersichtlich und effizient.
Das Ergebnis ist ein Werkzeug, das Sinn macht in Projekten, in denen sich klare Muster erkennen lassen. Es kann innerhalb kurzer Zeit hundert bis dreihundert Zeilen Code erzeugen, die anschließend mit geringem Aufwand geprüft und direkt übernommen werden können. Dies steigert die Produktivität deutlich, gerade bei wiederkehrenden Aufgaben wie der Erstellung von Unit-Tests basierend auf vorgegebenen APIs.Die Integration von LLMs ist dabei ein pragmatischer Ansatz, der keine tiefgehenden Expertenkenntnisse in künstlicher Intelligenz voraussetzt. Vielmehr ist die Arbeitsweise geprägt vom Definieren von Regeln, der Festlegung von Handschriften und anschließender Übergabe an das Sprachmodell.
Dieses Prinzip ist für Unternehmen und Entwickler äußerst attraktiv, weil es mit überschaubarem Aufwand einen hohen Automatisierungsgrad erreicht.Neben der Produktivitätssteigerung eröffnet das Plugin auch Chancen für die Qualitätssicherung. Durch konsequente Anwendung vordefinierter Testregeln entstehen einheitliche und umfassende Testfälle, die typischerweise manuell nur unvollständig erzeugt werden. Dies trägt langfristig zu stabileren und wartbaren Softwarelösungen bei.Die Herausforderung in diesem Ansatz liegt in der Komplexität des gesamten Kontextes: Um funktionierenden Code zu generieren, muss das Sprachmodell beispielsweise nicht nur die API-Schnittstelle kennen, sondern auch die Struktur von Datenklassen und die Verfügbarkeit von Hilfsklassen berücksichtigen.
Die sorgfältige Definition von Referenzen und Regeln bildet die Grundlage für den Erfolg.Dieser pragmatische Weg zur Automatisierung wurde vom Entwickler als „hochgradig vielversprechend“ bewertet. Er sieht in der Kombination aus klar definierten Mustern, automatischer Quellcode-Sammlung und leistungsfähigen LLMs den Schlüssel zur nächsten Entwicklungsstufe in der Softwareentwicklung. Eine verstärkte Formalisierung der Methode und die breitere Anwendung in der Praxis könnten dazu führen, dass ein Großteil bisher manueller Programmierarbeiten effizient automatisiert wird.Für Interessierte bietet das Projekt eine offene Diskussionsplattform und umfangreiche Dokumentationen, was die Zusammenarbeit fördert und den Austausch von Erfahrungen erleichtert.
So kann die Community dazu beitragen, das Plugin weiterzuentwickeln und Herausforderungen zu adressieren, die bislang den breiteren Einsatz hemmen.Zusammenfassend lässt sich sagen, dass die Verbindung von großen Sprachmodellen mit integrierten Entwicklungsumgebungen wie IntelliJ eine spannende und zukunftsweisende Entwicklung ist. Sie ermöglicht es, repetitive und gut definierte Aufgaben im Softwareentwicklungsprozess schneller, zuverlässiger und anpassbarer zu erledigen. Dies gibt Entwicklern mehr Zeit, sich auf kreative und anspruchsvollere Aspekte ihrer Arbeit zu konzentrieren und unterstützt Unternehmen dabei, Software in höherer Qualität und schnellerer Taktung bereitzustellen.In Zukunft sind weitere Fortschritte bei Sprachmodellen zu erwarten, die komplexere reasoningbasierte Aufgaben übernehmen können.




![America's Trucks Became Inferior to Europe's [video]](/images/90263BAB-09D4-4C9C-B54E-1D31DA987440)
