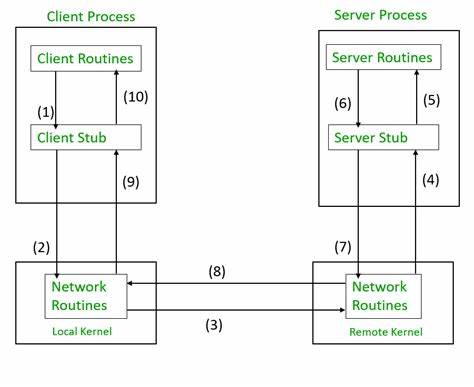
Die Welt der Softwareentwicklung hat sich in den letzten Jahrzehnten rasant weiterentwickelt. Insbesondere der Umgang mit verteilten Systemen stellt Entwickler vor immer größere Herausforderungen: Wie können verschiedene Dienste zuverlässig und konsistent miteinander kommunizieren? Wie lassen sich Fehler in einem komplexen Netzwerk von Services auffangen, ohne den gesamten Ablauf zu gefährden? Diese Fragen führen uns auf eine spannende Reise von traditionellen Remote Procedure Calls (RPC) über Transaktionsmechanismen bis hin zu modernen Konzepten der dauerhaften Ausführung, die insbesondere im Zeitalter von Microservices und Cloud-Infrastrukturen an Bedeutung gewinnen. Was zunächst als einfache Methode zur Kommunikation zwischen verschiedenen Systemen begann, hat sich zu einem tiefgreifenden Forschungsfeld rund um Konsistenz, Fehlertoleranz und Wiederherstellbarkeit entwickelt. RPC ist ein fundamentaler Baustein vieler verteilter Anwendungen. Mit ihm können Funktionen, die auf entfernten Rechnern laufen, so aufgerufen werden, als befänden sie sich lokal.
Doch sobald mehrere dieser Aufrufe miteinander verknüpft und Zustand über mehrere Systeme verteilt wird, treten komplexe Probleme auf. Etwa wenn eine Aktion halb abgeschlossen wird, dann aber die Verbindung abbricht oder ein Fehler auftritt. Die Frage ist, wie man in solchen Fällen Datenkonsistenz und Systemverfügbarkeit gewährleisten kann. Hier kommen Transaktionen ins Spiel – ein Konzept, das ursprünglich für relationale Datenbanken entworfen wurde, um Operationen als unteilbare Einheiten zu behandeln. Transaktionen garantieren die sogenannte ACID-Eigenschaft – Atomicity (Unteilbarkeit), Consistency (Konsistenz), Isolation (Isolation) und Durability (Dauerhaftigkeit).
Während das Konzept in monolithischen Systeme gut funktioniert, stößt es in verteilten Umgebungen, in denen mehrere Datenbanken oder Services zusammenarbeiten, an seine Grenzen. Verteilte Transaktionen versuchen, diese Hürde zu überwinden, indem sie Transaktionen über mehrere Ressourcen hinweg koordinieren. Das bekannteste Protokoll dafür ist der sogenannte Two-Phase Commit (2PC). Es sorgt dafür, dass alle beteiligten Komponenten die Transaktion vorbereiten und erst nach dem kollektiven Commit die Änderungen dauerhaft übernehmen. Dies verhindert Inkonsistenzen, kann aber zu erheblichen Problemen führen, wie blockierenden Sperren und langen Wartezeiten insbesondere bei Ausfällen.
Das Endergebnis ist, dass verteilte Transaktionen zwar Konsistenz bieten, aber die Verfügbarkeit stark beeinträchtigen und das gesamte System anfälliger gegenüber Fehlern machen. Ausgehend von dieser Erkenntnis entstand die Notwendigkeit, Alternativen zu finden, die Fehlertoleranz und Verfügbarkeit bevorzugen, auch wenn dies manchmal auf Kosten der starken Konsistenz geht. Deshalb gewannen Muster und Konzepte wie die Saga Patterns, Event Sourcing und Kompensierende Transaktionen an Bedeutung. Hier werden große Geschäftsprozesse in kleinere, atomare Schritte zerlegt, die jeweils selbständig abgeschlossen werden können. Falls ein Fehler auftritt, werden Rückabwicklungen über Kompensationsaktionen durchgeführt, um den vorherigen Zustand wiederherzustellen – allerdings ohne den hohen Overhead von 2PC.
Parallel dazu haben sich in den letzten Jahren sogenannte Durable Execution Engines herausgebildet, die den Umgang mit solchen lang laufenden und komplexen Abläufen vereinfachen sollen. Temporal ist hierfür ein prominentes Beispiel. Diese Systeme stellen Entwicklern abstrakte Werkzeuge und Plattformen zur Verfügung, die die Orchestrierung mehrerer Services, das Fehlermanagement und die asynchrone Kommunikation vereinfachen. Dadurch entsteht eine robustere Grundlage für Microservice-Architekturen, ohne dass Entwickler alle Fehlerszenarien manuell abdecken müssen. Einer der Kerngedanken hinter Durable Execution Engines ist die Trennung zwischen Workflows und Activities.
Workflows sind deklarative Beschreibungen des Gesamtprozesses, während Activities die kleineren, ausführbaren Einheiten darstellen. Beide zusammen arbeiten so, dass bei Fehlern oder Ausfällen die Workflows dank eines Event-Logs jederzeit wiederhergestellt und weitergeführt werden können. Hierbei werden Prinzipien aus der Event Sourcing Architektur genutzt, um Zustände nachvollziehbar und rekonstruierbar zu machen, was insbesondere für verteilte Systeme einen enormen Vorteil darstellt. Interessanterweise zeigen historische Betrachtungen, dass viele der heutigen Probleme und Lösungsansätze bereits vor Jahrzehnten erkannt wurden. Jim Gray, ein Pionier der Datenbankforschung, veröffentlichte bereits Anfang der 1980er Jahre Arbeiten zu Transaktionen, darunter das Konzept der „Long Lived Transactions“ – also langlebige Transaktionen, die sich über längere Zeiträume und mehrere Systeme erstrecken und eher einem modernen Workflow gleichen.
Die Idee von Kompensationsaktionen als Mittel zur Fehlerbehandlung wurde ebenfalls früh eingeführt – ein Prinzip, das heute vielfach in Enterprise Integration Patterns (EIP) Anwendung findet. Im Java-Umfeld gab es Versuche, diese erweiterten Transaktionsthemen über Standards wie JSR-95 (Activity Service for Extended Transactions) zu standardisieren. Trotz vielversprechender Ansätze und sogar Implementierungen dieser Spezifikation, blieb eine breite Umsetzung aus. Gründe dafür sind unter anderem die Komplexität der Implementierung und fehlende Akzeptanz in der Praxis. Ähnliche Entwicklungen gab es im Bereich von Web Services mit Standards wie WS-AtomicTransaction und WS-BusinessActivity.
Diese Standards fanden ebenfalls keinen größeren Verbreitungsgrad, was teilweise an der Überkomplexität und dem Overhead der Protokolle lag. Parallel dazu boomen leichtgewichtigere Lösungen im Microservice-Umfeld. Libraries wie Resilience4J und FailSafe unterstützen Entwickler bei Retry-Mechanismen und Circuit Breakern, um Fehlertoleranz in der Kommunikation zwischen Services umzusetzen. Das größte Gewicht liegt aber auf Event-getriebener Architektur, Orchestrierungen und der sogenannten Choreografie. Während Orchestrierung einen zentralen Koordinator beschreibt, der die einzelnen Schritte steuert, setzt Choreografie auf dezentrale Steuerung über Events, die einzelne Services abonnieren und auf die sie reagieren.
In den letzten Jahren spiegelt sich dieser Paradigmenwechsel auch in modernen Serverless- und Cloud-Lösungen wider. Anbieter wie AWS mit Step Functions, Microsoft mit Azure Durable Functions oder orchestrierte Systeme wie Uber Cadence bieten Plattformen, die dauerhafte Workflows in einer fehlertoleranten Weise unterstützen. Temporal ist in diesem Umfeld zu einer bedeutenden Open-Source-Alternative geworden, die diesen Trend verstärkt unterstützt. Technische Herausforderungen bleiben dabei spannend: Während klassische RPC-Modelle für kurzlebige, synchrone Aufrufe optimiert sind, fordern dauerhafte Ausführungen eine andere Denke. Langlebige Workflows müssen selbst nach Ausfällen oder Neustarts eines Systems nahtlos weiterlaufen.
Dazu kommt das Management von Zuständen, die persistiert und synchronisiert werden müssen. Temporal adressiert diese Herausforderungen beispielsweise durch eine zentrale Event-Historie, die es Workflows ermöglicht, ihren Zustand jederzeit zu rekonstruieren. Ein weiterer wichtiger Aspekt ist die Integration solcher Konzepte auf Sprachebene. Die Diskussion, ob Transaktionen und dauerhafte Ausführung als Sprachkonstrukte unterstützt werden sollten, ist alt aber erst jüngst wieder aufgebrochen. Projekte wie Autokitteh versuchen, den Entwickler mit automatischen Code-Transformationen zu entlasten, indem Workflow-Logik direkt aus dem Programmcode generiert wird.
Dies könnte die Akzeptanz und Verbreitung solcher Mechanismen deutlich verbessern. Auf der technischen Seite gibt es auch unterschiedliche Ansätze bezüglich der Speicherung von Zustandsinformationen. Während klassische Systeme oft relationale Datenbanken verwenden, setzen manche moderne Engines auf reine Event-Logs, um Abläufe effizienter und schneller abwickeln zu können. Die Wahl hängt von konkreten Anforderungen an Performance, Konsistenz und Skalierbarkeit ab. Letztlich wird die Entwicklung im Bereich dauerhafter Ausführung von verteilten Transaktionen und Workflow-Orchestrierung stark von der wachsenden Komplexität verteilter Systeme und der Cloud-Nutzung getrieben.








