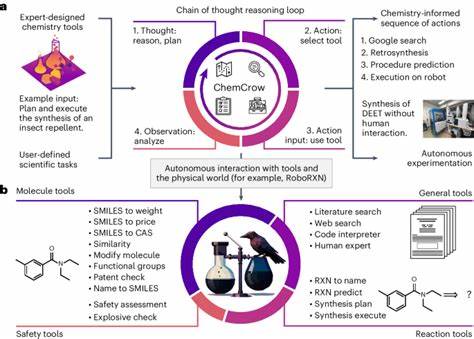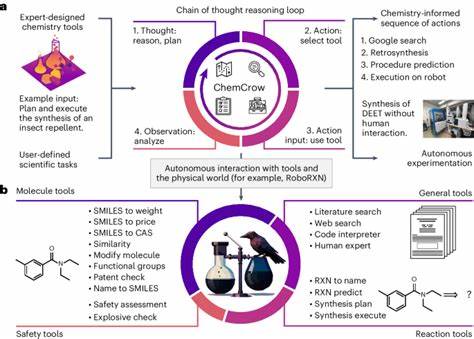
In den letzten Jahren hat die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) die wissenschaftliche Gemeinschaft stark beeindruckt. Besonders im Fachgebiet der Chemie eröffnen diese Technologien neue Möglichkeiten der Forschung, Analyse und Wissensvermittlung. Doch wie steht es um die chemische Kompetenz und die Fähigkeit zur logischen Schlussfolgerung solcher künstlichen Intelligenzsysteme im Vergleich zu erfahrenen Chemikern? Diese Fragestellung ist essenziell, um Potenziale zu erkennen, Grenzen zu definieren und zukünftige Entwicklungen sinnvoll zu steuern. Große Sprachmodelle basieren auf maschinellem Lernen, das auf gigantischen Textdatenmengen trainiert wird. Sie können nicht nur natürliche Sprache verstehen und generieren, sondern auch komplexe Aufgaben lösen, auf die sie nicht explizit programmiert wurden.
Das macht sie für die Chemie besonders interessant, da ein Großteil der chemischen Forschung in Textform vorliegt, sei es in wissenschaftlichen Artikeln, Patenten oder Datenbanken. Das Verständnis und die Aufbereitung dieser Informationen könnte beispielsweise die Forschung erheblich beschleunigen. Mit der Einführung von ChemBench, einem automatisierten Bewertungssystem, wurde ein entscheidender Schritt unternommen, um die Fähigkeiten dieser LLMs systematisch gegenüber der Expertise von menschlichen Chemikern zu prüfen. ChemBench umfasst eine Sammlung von fast 2800 Frage-Antwort-Paaren, die ein breites Spektrum chemischer Fachgebiete und erforderlicher kognitiver Fähigkeiten abdecken – von Grundwissen über komplexes logisches Denken bis zu chemischer Intuition. Bemerkenswert ist, dass einige der fortschrittlichsten Modelle in diesen Tests durchschnittlich besser abschnitten als erfahrene Chemiker.
Insbesondere offene Modelle wie Llama-3.1-405B zeigen, dass auch Open-Source-Modelle proprietären Systemen immer näherkommen, was die Leistungsfähigkeit anbelangt. Trotzdem bestehen weiterhin deutliche Schwächen, vor allem bei Fragen, die intensives fachliches Wissen oder strukturelle Analyse von Molekülen verlangen. Diese Limitationen spiegeln sich unter anderem darin wider, dass viele LLMs Schwierigkeiten haben, chemische Strukturen aus ihren textuellen Darstellungen präzise zu interpretieren. So fällt es den Modellen oft schwer, zum Beispiel die Anzahl von NMR-Signalen korrekt vorherzusagen, eine Aufgabe, die von Chemikern mit molekularer Zeichnung erheblich erleichtert wird.
Die Modelle greifen oftmals auf Wahrscheinlichkeiten zurück, die mit den Trainingsdaten nahestehenden Molekülen ähneln, anstatt die molekulare Struktur wirklich zu „verstehen“ und deduktiv zu analysieren. Ein weiteres Problem ist die Sicherheitsbewertung chemischer Substanzen. Obwohl LLMs in chemikaliensicherheitsbezogenen Tests durchaus solide Leistungen zeigten, müssen Fehlinformationen in diesem Bereich unbedingt vermieden werden, denn sie können potenziell gefährliche Auswirkungen haben. Zudem neigen viele Modelle dazu, übermäßig selbstsicher aufzutreten und unterschätzen die Wahrscheinlichkeit von Fehlern, was zu einer kritischen Herausforderung in der praktischen Anwendung führt. Die bisher beobachtete starke Variation in der Leistung der Modelle über unterschiedliche Fachgebiete hinweg macht deutlich, dass LLMs derzeit eher breit gefächerte Kompetenzen besitzen als spezialisierte Expertenfähigkeiten.
Während sie in allgemeinen und technischen Bereichen meist gute Resultate liefern, zeigt sich bei Themen wie Toxikologie oder analytischer Chemie ein deutlich geringeres Leistungsniveau. Der Vergleich mit menschlicher Expertise fördert zudem eine wichtige Erkenntnis zutage: Das traditionelle Lernen und Prüfen in der Chemie, basierend auf Lehrbuchfragen und Multiple-Choice-Tests, bildet heutzutage nicht notwendigerweise ausreichend die Fähigkeit ab, komplexe, praxisnahe Probleme zu lösen. LLMs brillieren oft genau bei diesen standardisierten Aufgaben, stoßen aber dort an ihre Grenzen, wo tiefgehende strukturelle und intuitive Schlussfolgerungen gefragt sind. Diese Beobachtung hat weitreichende Konsequenzen für die Chemieausbildung. Die zunehmende Leistungsfähigkeit von KI erfordert ein Umdenken hin zu mehr kritischem Denken, der Entwicklung von Problemlösungskompetenzen und der Fähigkeit, Modelle und ihre Ergebnisse eingehend zu hinterfragen.
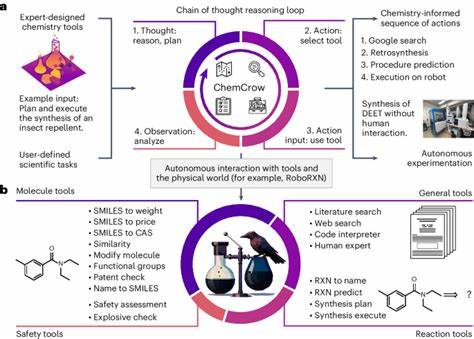
Die Rolle des Chemikers wandelt sich dadurch zu einer Schnittstelle zwischen domänenspezifischem Fachwissen und der Anwendung intelligenter Assistenzsysteme. Gleichzeitig stellt die Integration von LLMs in die chemische Forschung und Praxis ein enormes Potenzial dar. Sie könnten beispielsweise als „Co-Piloten“ fungieren, die bei der Recherche, Hypothesengenerierung, Reaktionsplanung und sogar Durchführung von Experimenten unterstützen. Besonders leistungsfähige Modelle, die mit spezialisierten Datenbanken wie PubChem oder Gestis gekoppelt sind, könnten komplexe Wissensbereiche effektiv abdecken und so die Innovationsgeschwindigkeit erhöhen. Doch trotz dieser Fortschritte gilt es stets die Grenzen der Modelle zu beachten.
Derzeit fehlt es LLMs oft an der Fähigkeit, ihre eigenen Unsicherheiten realistisch einzuschätzen, was für den Nutzer zu Fehleinschätzungen führen kann. Eine verbesserte Kalibrierung der Vertrauenswerte und das explizite Kommunizieren von Unsicherheiten sind daher wichtige Ziele zukünftiger Entwicklungen. Zudem darf nicht vernachlässigt werden, dass LLMs trotz immer größerer Datenmengen und komplexerer Architekturen auf Trainingsdaten basieren und daher in gewisser Weise auch auf bereits Bekanntem „aufsitzen“. Sie reproduzieren somit vorhandenes Wissen und Muster, ohne echtes kreatives oder „intuitives“ Verstehen im menschlichen Sinne zu erlangen. Trotzdem überraschen sie oft mit der Fähigkeit, neue Verknüpfungen zu generieren, was die Diskussion um sogenannte „künstliche Allgemeine Intelligenz“ befeuert.
Die Ethik des Einsatzes solcher KI-Modelle in der Chemie ist ein weiterer kritischer Aspekt. Die Möglichkeit, KI für die Entwicklung toxischer oder gar illegaler Substanzen zu missbrauchen, verlangt nach verantwortungsvoller Regulierung, Transparenz und umfassender Überwachung. Chemiker, Entwickler und politische Entscheidungsträger müssen hierbei eng zusammenarbeiten, um missbräuchliche Nutzung wirksam zu verhindern. Insgesamt ergibt sich ein komplexes Bild: Große Sprachmodelle verfügen bereits heute über beeindruckende chemische Kenntnisse und zeigen in Tests eine Leistung, die mit der von menschlichen Experten konkurrieren kann. Dennoch sind sie derzeit noch weit davon entfernt, erfahrene Chemiker vollständig zu ersetzen.
Vielmehr ergänzen sie das Fachwissen und die Erfahrung des Menschen und eröffnen neue Synergien, die in Zukunft die Chemie nachhaltig prägen werden. Die weitere Verbesserung der Modelle wird maßgeblich von der Entwicklung zuverlässiger und repräsentativer Benchmarking-Systeme wie ChemBench abhängen. Diese ermöglichen ein objektives Messen von Fortschritten und fördern die Entwicklung von sichereren und nützlicheren Anwendungen. Ebenfalls entscheidend ist die verstärkte Integration von Spezialwissen und strukturierten Daten in die Modelle sowie die Forschung an besserem Verständnis und Erklärbarkeit von KI-Systemen. Abschließend steht fest, dass die Chemiewelt am Beginn einer neuen Ära steht, in der menschliche Expertise und künstliche Intelligenz eng miteinander verwoben sind.
Die Herausforderungen, etwa in der Genauigkeit, Interpretierbarkeit und Sicherheit, sind groß, doch die Chancen für Innovation, Effizienzsteigerung und Erweiterung des Wissensfundaments sind immens. Ein verantwortungsvoller, informierter Umgang mit LLMs wird entscheidend sein, um das volle Potenzial für die Wissenschaft und Gesellschaft zu erschließen.