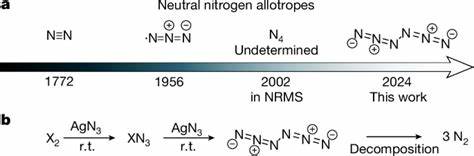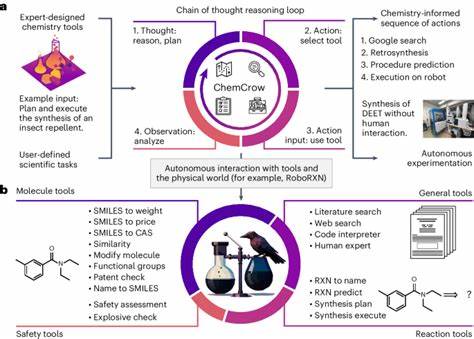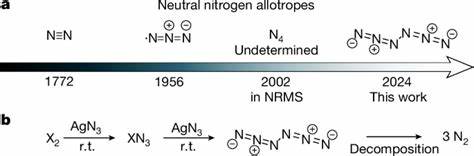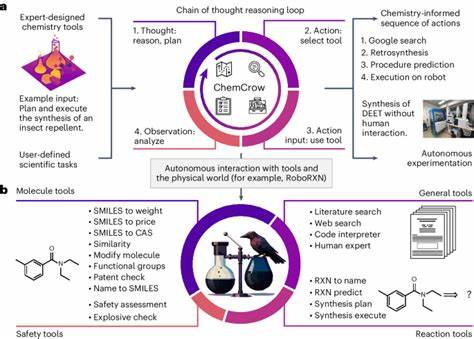
Die letzten Jahre haben eine rasante Entwicklung im Bereich der Künstlichen Intelligenz (KI) erlebt, insbesondere durch die Einführung großer Sprachmodelle, auch Large Language Models (LLMs) genannt. Diese Modelle, trainiert auf umfangreichen Textdatensätzen, können auf bislang ungeahnte Weise komplexe Aufgaben im Bereich der natürlichen Sprache bewältigen. Die Chemie als naturwissenschaftliche Disziplin, die traditionell stark auf menschliches Fachwissen und intuitive Schlussfolgerungen angewiesen ist, erlebt nun den Einfluss dieser technologische Revolution. Ein aktueller Vergleich zwischen den chemischen Kenntnissen sowie der Schlussfolgerungsfähigkeit von LLMs und der Expertise erfahrener Chemiker eröffnet faszinierende Einblicke in die Zukunft der chemischen Forschung und Lehre. Große Sprachmodelle zeigen sowohl beeindruckende Fähigkeiten als auch deutliche Schwächen, welche für Forscher, Lehrende und Anwender von entscheidender Bedeutung sind.
Das Potenzial großer Sprachmodelle in der Chemie beruht darauf, dass ein Großteil chemischen Wissens in wissenschaftlichen Publikationen, Lehrbüchern, Datenbanken und Protokollen in Textform vorliegt. Im Gegensatz zu klassischen Datenbankabfragen oder spezialisierten Softwarelösungen können LLMs komplexe sprachbasierte Anfragen verstehen, bearbeiten und ausgeben. Sie können Fragen zu molekularen Eigenschaften beantworten, Reaktionsrouten vorschlagen oder sogar chemische Gedankenspiele durchführen. Dieses breite Anwendungsspektrum macht sie zu vielversprechenden digitalen Assistenten für Chemiker, die bei der Auswertung tausender Publikationen und Daten entlasten und neue Hypothesen generieren können, die menschlichen Forschern möglicherweise entgehen. Eine zentrale Fragestellung lautet, wie gut diese Modelle im Vergleich zu menschlichen Experten tatsächlich abschneiden.
Ausgehend von einer umfangreichen Studie, in der über 2.700 Frage-Antwort-Paare aus diversen Chemiegebieten zusammengestellt wurden, wurden führende LLMs überprüft und their chemical performance with that of professional chemists compared. Interessanterweise erzielte das bestbewertete Modell im Durchschnitt deutlich bessere Ergebnisse als die menschlichen Experten in diesem Test. Das allein ist ein beachtlicher Fortschritt – der jedoch nicht ohne kritische Begleiterscheinungen ist. Zwar können LLMs große Datenmengen sehr effizient verarbeiten und kombinieren, doch stoßen sie bei grundlegenden Aufgaben, die auf einfache Faktenabfrage oder logisches Vernetzen abzielen, gelegentlich an Grenzen oder liefern übermäßig zuversichtliche, jedoch falsche Antworten.
Die Leistung der Modelle schwankt auch stark in verschiedenen chemischen Unterdisziplinen. Während sie in der allgemeinen und technischen Chemie relativ gut abschneiden, zeigen sich Schwächen vor allem bei sicherheitsrelevanten Aspekten und analytischer Chemie, wie etwa bei der Auswertung von Kernspinresonanzspektren. Ein Grund hierfür liegt im Unterschied der Darstellung molekularer Strukturen: Die Modelle müssen die molekularen Stringrepräsentationen (z. B. SMILES) eigenständig interpretieren und strukturbezogen logisch verarbeiten, was ihnen oft schwerfällt, da ihr Training hauptsächlich textbasiert ist und keine direkte experimentelle Erfahrung umfasst.
Im Gegensatz dazu können menschliche Experten aus Erfahrung und kontextuellem Wissen auch visuelle Darstellungen und praktische Hinweise verarbeiten. Ein weiteres interessantes Ergebnis betrifft die Einschätzung der Unsicherheit durch die Modelle. Idealerweise sollten LLMs angeben können, wie sicher sie sich mit einer Antwort sind, um Fehlinformationen zu minimieren. In der Praxis zeigen Forscher jedoch, dass viele Modelle kein verlässliches Selbstvertrauen in ihre Antworten artikulieren. Über- oder unterschätzte Konfidenz kann bei der Anwendung fatale Folgen haben, insbesondere in Fragestellungen, die gesundheitliche und sicherheitsrelevante Konsequenzen betreffen.
Somit bleibt weiterhin die menschliche Kontrolle unerlässlich, auch wenn die Modelle zunehmend leistungsfähiger werden. Die Erkenntnisse dieser Untersuchung haben weitreichende Implikationen für die chemische Ausbildung. Das traditionelle Lernen, das oft auf das Auswendiglernen von Fakten und einfachen Problemlösefähigkeiten basiert, dürfte künftig weniger zielführend sein, wenn KI-Systeme derartige Wissensbestandteile besser abrufen können. Stattdessen rückt das Vermitteln von kritischem Denken, komplexer Schlussfolgerung und der Fähigkeit, Modellantworten zu interpretieren und zu hinterfragen, in den Vordergrund. Die Ausbildung von Chemikern muss sich also anpassen, um den bestmöglichen Umgang mit KI-gestützten Werkzeugen zu fördern.
Neben der Ausbildung birgt die Integration von LLMs in die chemische Forschung und Praxis großes Potenzial. KI-gestützte Copiloten können in der Literaturrecherche, der Planung von Experimenten oder bei der Bewertung möglicher Reaktionsmechanismen eine wertvolle Unterstützung sein. Einige Modelle können bereits in Kombination mit externen Hilfsmitteln, wie Suchmaschinen oder Syntheseplänen, Reaktionen vorschlagen oder autonom erste Versuche durchführen. Diese Entwicklung verspricht eine Beschleunigung der Forschung und die Öffnung neuer Erkenntnispfade. Dennoch besteht weiterhin die Herausforderung, die Modelle mit Fokus auf Chemie zu verbessern.
So zeigte sich, dass der Zugang zu spezialisierten chemischen Datenbanken (z. B. PubChem) und nicht nur zu wissenschaftlichen Artikeln die Ergebnisse bei wissensintensiven Fragen deutlich verbessern würde. Auch die Skalierung der Modelle, sprich das Training mit noch größerer Datenmenge und höherer Komplexität, könnte den Leistungszuwachs weiter befeuern. Gleichzeitig muss die sichere Nutzung durch mehr Transparenz über Grenzen und Unsicherheiten gesichert werden.
Ein spannendes Thema ist außerdem die Frage der „chemischen Intuition“ – also der menschlichen Fähigkeit, auf Basis von Erfahrung entstehende Präferenzen oder Einschätzungen zu treffen, beispielsweise welche Moleküle in einer frühen Phase der Wirkstoffentwicklung bevorzugt werden sollten. Hier erzielten die Modelle bislang keine nennenswerte Übereinstimmung mit Expertenentscheidungen. Das legt nahe, dass chemische Präferenzentscheidungen weiterhin vor allem menschliches Erfahrungswissen sind und dass KI-Systeme erst noch lernen müssen, solche subtile Urteilskraft nachzubilden. Die Debatte, ob LLMs „kreativ“ oder „verstehen“ können, wie es Menschen tun, ist in der Chemie besonders relevant. Einerseits zeigen die Modelle beeindruckende Fortschritte in der Kombination und Anwendung verfügbaren Wissens.
Andererseits spiegeln sie ihre Trainingsdaten oftmals nur wider ohne tiefes konzeptuelles Verständnis. Die Bezeichnung „stochastische Papageien“ bringt diese Herausforderung auf den Punkt: Modelle reproduzieren Muster, ohne echtes Verstehen oder Bewusstsein zu haben. Trotzdem sind diese Fortschritte für die chemische Disziplin ein Meilenstein, der den Dialog zwischen Mensch und Maschine in der Forschung auf eine neue Ebene hebt. Auch ethische und sicherheitstechnische Aspekte müssen unbedingt bedacht werden. Die Nutzung von LLMs im Chemiebereich kann missbraucht werden, etwa für die Entwicklung gefährlicher Substanzen oder chemischer Waffen.
Daher ist ein verantwortungsvoller Umgang entscheidend, ebenso wie Regulierungen und Schutzmechanismen. Große Sprachmodelle müssen so gestaltet und überwacht werden, dass sie keine problematischen Informationen unkontrolliert verbreiten. Die Einführung von standardisierten und umfassenden Bewertungsframeworks wie dem sogenannten ChemBench ist ein wichtiger Schritt, um die Fähigkeiten und Grenzen dieser Modelle differenziert zu erfassen. Mit Tausenden sorgfältig validierten Fragen aus verschiedenen Chemiegebieten und Schwierigkeitsgraden bietet ChemBench eine Grundlage, um Modelle systematisch zu testen und Fortschritte zu messen. Dadurch wird auch der Vergleich zwischen menschlichen Experten und KI-gestützten Systemen transparenter und objektiver.
Zusammenfassend lässt sich sagen, dass große Sprachmodelle in der Chemie ein enormes Potenzial besitzen, die Forschung, Lehre und Praxis zu transformieren. Sie können menschliche Experten in vielen Bereichen ergänzen und teilweise sogar übertreffen. Jedoch bestehen weiterhin klare Grenzen, gerade bei grundlegendem Faktenwissen, komplexer Strukturinterpretation, Unsicherheitseinschätzung und menschlicher Intuition. Für eine erfolgreiche Integration in den chemischen Alltag ist es daher essenziell, das Zusammenspiel von KI und menschlichem Urteil noch besser zu verstehen und weiterzuentwickeln. Zudem wird die Chemie-Ausbildung zunehmend darauf angewiesen sein, Schülerinnen und Schüler sowie Studierende darin zu schulen, kritisch mit KI-Ergebnissen umzugehen, denn das Wissen, das reine Fakten und Daten umfasst, wird von KI künftig weitgehend bereitgestellt werden können.
Der Mensch bleibt unverzichtbar als kritischer Denker, als kreativer Problemlöser und als Entscheider mit ethischem Bewusstsein. Mit dem stetigen Fortschritt in der Entwicklung und Anpassung großer Sprachmodelle speziell für chemische Fragestellungen werden diese Systeme in Zukunft noch leistungsfähiger und vielseitiger agieren. Die Herausforderung liegt darin, diese Werkzeuge sicher, verantwortungsvoll und gewinnbringend in die Chemie einzubinden, damit das Potenzial voll ausgeschöpft und etwaige Risiken minimiert werden können. Die nächsten Jahre versprechen somit spannende Innovationen an der Schnittstelle von Künstlicher Intelligenz und Chemie – zum Nutzen der Wissenschaft, der Bildung und der Gesellschaft.